







本文为和鲸python 特征工程入门与实践·闯关训练营资料整理而来,加入了自己的理解(by GPT4o)
原作者:云中君,大厂后端研发工程师
**作者:云中君,**大厂后端研发工程师
1、前言
特征工程是数据科学中的关键步骤,它基于领域知识从原始数据中提取特征,以提升机器学习模型的性能。数据是特征工程的基础,没有数据就不可能提取特征。
本节主要从以下几个方面对数据进行讲解:
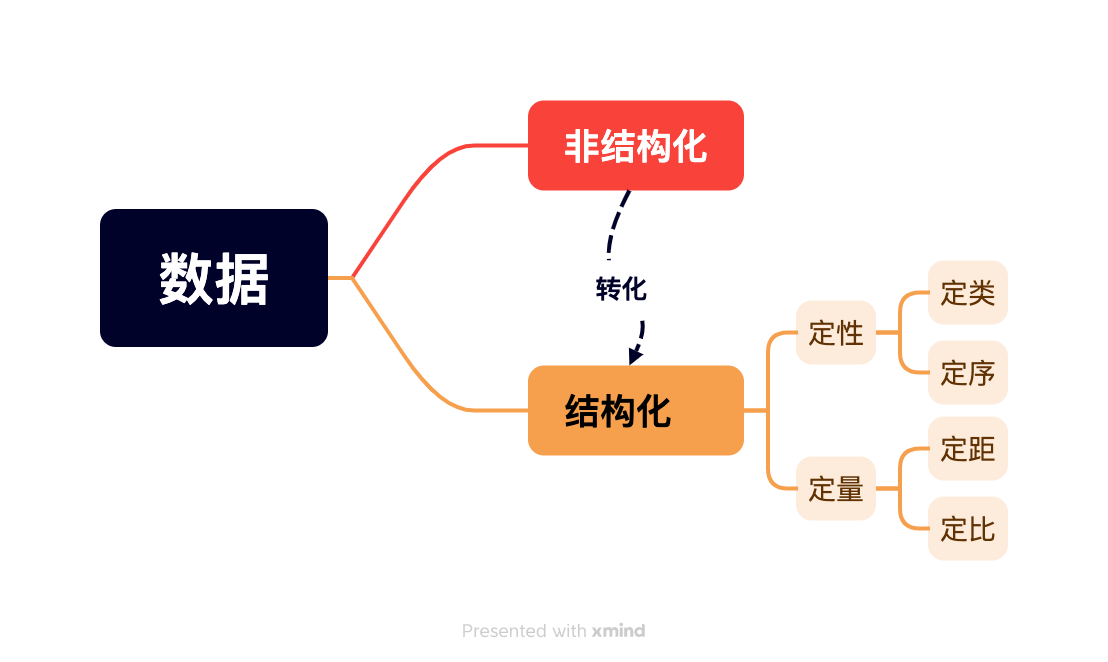
- 结构化数据与非结构化数据
- 定量数据与定性数据
- 数据的4个等级
- 数据可视化
2、基础知识讲解
当你拿到一个新的数据集时,基本工作流程是怎样的呢?
(1) 数据有没有组织?数据是以表格形式存在、有不同的行列,还是以非结构化的文本格式存在?
(2) 每列的数据是定量的还是定性的?单元格中的数代表的是数值还是字符串?
(3) 每列处于哪个等级?是定类、定序、定距,还是定比?
(4) 我可以用什么图表?条形图、饼图、茎叶图、箱线图、直方图,还是其他?
2.1判断数据结构
拿到一个新的数据集后,首先观察数据是结构化还是非结构化的
- 结构化(有组织)数据:可以分成观察值和特征的数据,一般以表格的形式组织(行是观察值,列是特征)
- 非结构化(无组织)数据:作为自由流动的实体,不遵循标准组织结构(例如表格)的数据。通常,非结构化数据在我们看来是一团数据,或只有一个特征(列)。
举例:
以原始文本格式存储的数据,如服务器日志和推文是非结构化数据;科学仪器报告的气象数据是高度结构化的,因为存在表格的行列结构。
服务器日志
127.0.0.1 - - [01/Mar/2021:12:36:49 0800] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36
气象数据
| 时间 | 气温 |
|---|---|
| 1743-11-01 | 6.068 |
| 1744-04-01 | 5.788 |
| 1744-05-01 | 10.644 |
2.2定性数据和定量数据
处理结构化的表格数据时,第一个问题是:数据是定量的,还是定性的?
- 定量数据通常是结构化的,可以用数字进行计数、测量和表示,更加严格和明确。它本质上是数值,衡量某样东西的数量,生成结论性的信息
- 定性数据通常是非结构化数据或半结构化,是描述性的和概念性的。它本质上是类别,描述某样东西的性质,从定性数据中生成可以用于解释、发展假设和初步理解。
基本示例:
- 以华氏度或摄氏度表示的气温是定量的
- 阴天或晴天是定性的
- 白宫参观者的名字是定性的
- 献血的血量是定量的。
数据可以同时是定量和定性的。例如,餐厅的评分(1~5星)虽然是数,但是这个数也可以代表类别。如果餐厅评分应用要求你用定量的星级系统打分,并且公布带小数的平均分数(例如4.71星),那么这个数据是定量的。如果该应用问你的评价是讨厌、还行、喜欢、喜爱还是特别喜爱,那么这些就是类别。由于定量数据和定性数据之间的模糊性,我们会使用一个更深层次的方法进行处理,称为数据的4个等级。
下面让我们用旧金山工资数据集来分析一下数据的定性与定量
# 存储表格数据
import pandas as pd
# 数据计算包
import numpy as np
# 数据可视化包
import matplotlib.pyplot as plt
import seaborn as sns
# 允许行内渲染图形
%matplotlib inline
# 流行的数据可视化主题
plt.style.use('fivethirtyeight')
# 到导入数据集 旧金山工资
path = './data/'
salary_ranges = pd.read_csv(path+'Salary_Ranges_by_Job_Classification.csv')
# 查看前几行
salary_ranges.head()
| SetID | Job Code | Eff Date | Sal End Date | Salary SetID | Sal Plan | Grade | Step | Biweekly High Rate | Biweekly Low Rate | Union Code | Extended Step | Pay Type | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | COMMN | 0109 | 07/01/2009 12:00:00 AM | 06/30/2010 12:00:00 AM | COMMN | SFM | 00000 | 1 | $0.00 | $0.00 | 330 | 0 | C |
| 1 | COMMN | 0110 | 07/01/2009 12:00:00 AM | 06/30/2010 12:00:00 AM | COMMN | SFM | 00000 | 1 | $15.00 | $15.00 | 323 | 0 | D |
| 2 | COMMN | 0111 | 07/01/2009 12:00:00 AM | 06/30/2010 12:00:00 AM | COMMN | SFM | 00000 | 1 | $25.00 | $25.00 | 323 | 0 | D |
| 3 | COMMN | 0112 | 07/01/2009 12:00:00 AM | 06/30/2010 12:00:00 AM | COMMN | SFM | 00000 | 1 | $50.00 | $50.00 | 323 | 0 | D |
| 4 | COMMN | 0114 | 07/01/2009 12:00:00 AM | 06/30/2010 12:00:00 AM | COMMN | SFM | 00000 | 1 | $100.00 | $100.00 | 323 | 0 | M |
# 查看数据的基本信息
salary_ranges.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1356 entries, 0 to 1355
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SetID 1356 non-null object
1 Job Code 1356 non-null object
2 Eff Date 1356 non-null object
3 Sal End Date 1356 non-null object
4 Salary SetID 1356 non-null object
5 Sal Plan 1356 non-null object
6 Grade 1356 non-null object
7 Step 1356 non-null int64
8 Biweekly High Rate 1356 non-null object
9 Biweekly Low Rate 1356 non-null object
10 Union Code 1356 non-null int64
11 Extended Step 1356 non-null int64
12 Pay Type 1356 non-null object
dtypes: int64(3), object(10)
memory usage: 137.8+ KB
info方法可以查看数据的行数、列数、缺失值数目以及每列的数据类型
# 另一种计算缺失值数量的方法
salary_ranges.isnull().sum()
SetID 0
Job Code 0
Eff Date 0
Sal End Date 0
Salary SetID 0
Sal Plan 0
Grade 0
Step 0
Biweekly High Rate 0
Biweekly Low Rate 0
Union Code 0
Extended Step 0
Pay Type 0
dtype: int64
用describe方法查看一些定量数据的描述性统计。注意,describe方法默认描述定量列,但是如果没有定量列,也会描述定性列
# 定量数据的描述性统计
salary_ranges.describe()
| Step | Union Code | Extended Step | |
|---|---|---|---|
| count | 1356.000000 | 1356.000000 | 1356.000000 |
| mean | 1.294985 | 392.676991 | 0.150442 |
| std | 1.045816 | 338.100562 | 1.006734 |
| min | 1.000000 | 1.000000 | 0.000000 |
| 25% | 1.000000 | 21.000000 | 0.000000 |
| 50% | 1.000000 | 351.000000 | 0.000000 |
| 75% | 1.000000 | 790.000000 | 0.000000 |
| max | 5.000000 | 990.000000 | 11.000000 |
可以很明显的看出pandas把数据类型为int的看做定量列了,我们来看看定量列Biweekly High Rate(双周最高工资)和定性列Grade(工作种类)。
salary_ranges = salary_ranges[['Biweekly High Rate','Grade']]
salary_ranges.head()
| Biweekly High Rate | Grade | |
|---|---|---|
| 0 | $0.00 | 00000 |
| 1 | $15.00 | 00000 |
| 2 | $25.00 | 00000 |
| 3 | $50.00 | 00000 |
| 4 | $100.00 | 00000 |
清理一下数据,移除工资前面的美元符号,保证数据类型正确。当处理定量数据时,一般使用整数或浮点数作为类型(最好使用浮点数);定性数据则一般使用字符串或Unicode对象。
salary_ranges['Biweekly High Rate'].describe()
count 1356
unique 593
top $3460.00
freq 12
Name: Biweekly High Rate, dtype: object
# 删除工资的美元符号
salary_ranges['Biweekly High Rate']=salary_ranges['Biweekly High Rate'].map(lambda value:value.replace('$',''))
# 检查一下
salary_ranges.head()
| Biweekly High Rate | Grade | |
|---|---|---|
| 0 | 0.00 | 00000 |
| 1 | 15.00 | 00000 |
| 2 | 25.00 | 00000 |
| 3 | 50.00 | 00000 |
| 4 | 100.00 | 00000 |
# 将Biweekly High Rate列转换成float
salary_ranges['Biweekly High Rate'] = salary_ranges['Biweekly High Rate'].astype(float)
# 将Grade转换为str
salary_ranges['Grade'].astype(str)
salary_ranges.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1356 entries, 0 to 1355
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Biweekly High Rate 1356 non-null float64
1 Grade 1356 non-null object
dtypes: float64(1), object(1)
memory usage: 21.3+ KB
2.3数据的四个等级
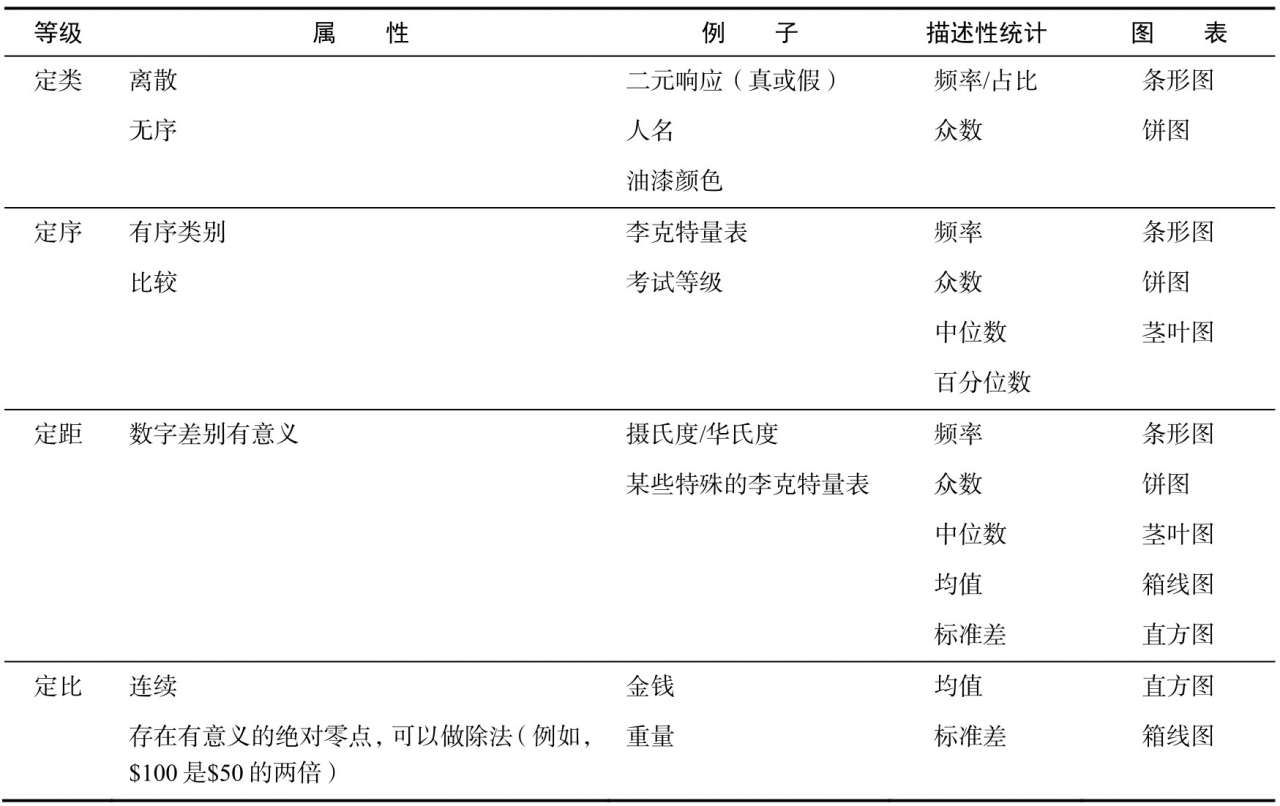
我们已经可以将数据分为定量和定性的,但是还可以继续分类。数据的4个等级是:
- 定类等级(nominal level)
- 定序等级(ordinal level)
- 定距等级(interval level)
- 定比等级(ratio level)
定类等级
定类等级是数据的第一个等级,其结构最弱。这个等级的数据只按名称分类。例如,血型(A、B、O和AB型)、动物物种和人名。这些数据都是定性的。在上面"旧金山工作工资"的数据集中,工作种类处于定类等级。
在这个等级上,不能执行任何定量数学操作,例如加法或除法。这些数学操作没有意义。因为没有加法和除法,所以在此等级上找不到平均值。
# 对工作种类进行计数
salary_ranges['Grade'].value_counts().head()
00000 61
07450 12
06870 9
07420 9
07170 9
Name: Grade, dtype: int64
出现最多的工作种类是00000,意味着这个种类是众数,即最多的类别。因为能在定类等级上进行计数,所以可以绘制图表,如条形图和饼图
通过绘制条形图和饼图,可以更直观的观察定类数据
# 条形图
salary_ranges['Grade'].value_counts().sort_values(ascending=False).head(20).plot(kind='bar')
<AxesSubplot:>

# 饼图
salary_ranges['Grade'].value_counts().sort_values(ascending=False).head(5).plot(kind='pie')
<AxesSubplot:ylabel='Grade'>

定序等级
定序等级继承了定类等级的所有属性,而且有重要的附加属性:定序等级的数据可以自然排序。因此可以认为列中的某些数据比其他数据更好或更大。和定类等级一样,定序等级的天然数据属性仍然是类别,即使用数来表示类别也是如此。
因为能排序和比较,所以能计算中位数和百分位数。对于中位数和百分位数,我们可以绘制茎叶图和箱线图。
其他的例子包括:
- 使用李克特量表(比如1~10的评分)
- 考试的成绩(F、D、C、B、A)
# 旧金山国际机场数据集
customer = pd.read_csv(path+'2013_SFO_Customer_survey.csv')
customer.shape
(3535, 95)
Q7A_ART这一列是关于艺术品和展览的。可能的选择是0、1、2、3、4、5、6。
0:空
1:不可接受
2:低于平均
3:平均
4:不错
5:特别好
6:从未有人使用或参观过
art_ratings = customer['Q7A_ART']
art_ratings.describe()
count 3535.000000
mean 4.300707
std 1.341445
min 0.000000
25% 3.000000
50% 4.000000
75% 5.000000
max 6.000000
Name: Q7A_ART, dtype: float64
# 这个列代表类别,只考虑1~5
art_ratings = art_ratings[(art_ratings>=1)&(art_ratings<=5)]
# 将值转换成字符串
art_ratings = art_ratings.astype(str)
art_ratings.describe()
count 2656
unique 5
top 4
freq 1066
Name: Q7A_ART, dtype: object
# 格式正确,进行可视化
art_ratings.value_counts().plot(kind='pie')
<AxesSubplot:ylabel='Q7A_ART'>

# 条形图
art_ratings.value_counts().plot(kind='bar')
<AxesSubplot:>

# 箱线图,不可能将之前的Grade列画成箱线图,因为找不到中位数。
art_ratings.value_counts().plot(kind='box')
<AxesSubplot:>

定距等级
在定类和定序等级,我们一直在处理定性数据。即使其内容是数,也不代表真实的数量。在定距等级,我们摆脱了这个限制,开始研究定量数据。在定距等级,数值数据不仅可以像定序等级的数据一样排序,而且值之间的差异也有意义。这意味着,在定距等级,我们不仅可以对值进行排序和比较,而且可以加减。
例子:定距等级的一个经典例子是温度。如果美国得克萨斯州的温度是32℃,阿拉斯加州的温度是4℃,那么可以计算出32-4=28℃的温差。
既然可以把值加在一起,就能引入两个熟悉的概念:算术平均数(就是均值)和标准差
# 气候数据集
climate = pd.read_csv('./data/GlobalLandTemperatures/GlobalLandTemperaturesByCity.csv')
climate.head()
| dt | AverageTemperature | AverageTemperatureUncertainty | City | Country | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|
| 0 | 1743-11-01 | 6.068 | 1.737 | Århus | Denmark | 57.05N | 10.33E |
| 1 | 1743-12-01 | NaN | NaN | Århus | Denmark | 57.05N | 10.33E |
| 2 | 1744-01-01 | NaN | NaN | Århus | Denmark | 57.05N | 10.33E |
| 3 | 1744-02-01 | NaN | NaN | Århus | Denmark | 57.05N | 10.33E |
| 4 | 1744-03-01 | NaN | NaN | Århus | Denmark | 57.05N | 10.33E |
# 移除缺失值
climate.dropna(axis=0,inplace=True)
climate.head()
| dt | AverageTemperature | AverageTemperatureUncertainty | City | Country | Latitude | Longitude | |
|---|---|---|---|---|---|---|---|
| 0 | 1743-11-01 | 6.068 | 1.737 | Århus | Denmark | 57.05N | 10.33E |
| 5 | 1744-04-01 | 5.788 | 3.624 | Århus | Denmark | 57.05N | 10.33E |
| 6 | 1744-05-01 | 10.644 | 1.283 | Århus | Denmark | 57.05N | 10.33E |
| 7 | 1744-06-01 | 14.051 | 1.347 | Århus | Denmark | 57.05N | 10.33E |
| 8 | 1744-07-01 | 16.082 | 1.396 | Århus | Denmark | 57.05N | 10.33E |
# 检查缺失值
climate.isnull().sum()
dt 0
AverageTemperature 0
AverageTemperatureUncertainty 0
City 0
Country 0
Latitude 0
Longitude 0
dtype: int64
温度数据属于定距等级,这里不能使用条形图或饼图进行可视化,因为值太多了。我们看看AverageTemperature(平均温度)
# 显示独特值得数量
climate['AverageTemperature'].nunique()
103481
# 直方图 用不同的桶包含不同的数据,对数据的频率进行可视化
climate['AverageTemperature'].plot(kind='hist')
<AxesSubplot:ylabel='Frequency'>

climate['AverageTemperature'].describe()
count 8.235082e+06
mean 1.672743e+01
std 1.035344e+01
min -4.270400e+01
25% 1.029900e+01
50% 1.883100e+01
75% 2.521000e+01
max 3.965100e+01
Name: AverageTemperature, dtype: float64
继续处理数据,加入year(年)和century(世纪)两列,只观察美国的数据
# 将dt列转换成日期,取年份
climate['dt'] = pd.to_datetime(climate['dt'])
climate['year'] = climate['dt'].map(lambda value:value.year)
# 只看美国
climate_sub_us = climate.loc[climate['Country'] == 'United States']
climate_sub_us['century'] = climate_sub_us['year'].map(lambda x: int(x/100+1))
climate_sub_us.head()
C:\Users\chengyuanting\AppData\Local\Temp\ipykernel_20140\2138487398.py:7: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
climate_sub_us['century'] = climate_sub_us['year'].map(lambda x: int(x/100+1))
| dt | AverageTemperature | AverageTemperatureUncertainty | City | Country | Latitude | Longitude | year | century | |
|---|---|---|---|---|---|---|---|---|---|
| 47555 | 1820-01-01 | 2.101 | 3.217 | Abilene | United States | 32.95N | 100.53W | 1820 | 19 |
| 47556 | 1820-02-01 | 6.926 | 2.853 | Abilene | United States | 32.95N | 100.53W | 1820 | 19 |
| 47557 | 1820-03-01 | 10.767 | 2.395 | Abilene | United States | 32.95N | 100.53W | 1820 | 19 |
| 47558 | 1820-04-01 | 17.989 | 2.202 | Abilene | United States | 32.95N | 100.53W | 1820 | 19 |
| 47559 | 1820-05-01 | 21.809 | 2.036 | Abilene | United States | 32.95N | 100.53W | 1820 | 19 |
# 使用新的centery列,对每个世纪化直方图
climate_sub_us['AverageTemperature'].hist(by=climate_sub_us['century'], sharex=True, sharey=True, figsize=(10, 10), bins=20)
array([[<AxesSubplot:title={'center':'18'}>,
<AxesSubplot:title={'center':'19'}>],
[<AxesSubplot:title={'center':'20'}>,
<AxesSubplot:title={'center':'21'}>]], dtype=object)

这4幅直方图显示AverageTemperature随时间略微上升,确认一下
climate_sub_us.groupby('century')['AverageTemperature'].mean().plot(kind='line')
<AxesSubplot:xlabel='century'>

century_changes=climate_sub_us.groupby('century')['AverageTemperature'].mean()
century_changes
century
18 12.073243
19 13.662870
20 14.386622
21 15.197692
Name: AverageTemperature, dtype: float64
定距及更高等级的一大好处是,我们可以使用散点图:在两个轴上绘制两列数据,将数据点可视化为图像中真正的点。在气候变化数据集中,year和averageTemperature列都属于定距等级。因为它们的差值是有意义的。因此可以对美国每月的温度绘制散点图,其中x轴是年份,y轴是温度。我们希望可以看见之前折线图表示的升温趋势:
# 我们针对year和averageTemperature两列数据进行描绘
x = climate_sub_us['year']
y = climate_sub_us['AverageTemperature']
fig, ax = plt.subplots(figsize=(10, 5))
ax.scatter(x, y)
plt.show()

# 用groupby清除美国气温的噪声
climate_sub_us.groupby('year').mean()['AverageTemperature'].plot()
<AxesSubplot:xlabel='year'>

# 用滑动均值平滑图像
climate_sub_us.groupby('year').mean()['AverageTemperature'].rolling(10).mean().plot()
<AxesSubplot:xlabel='year'>

定比等级
在这个等级上,我们拥有最高程度的控制和数学运算能力。和定距等级一样,我们在定比等级上处理的也是定量数据。这里不仅继承了定距等级的加减运算,而且有了一个绝对零点的概念,可以做乘除运算。
旧金山工资数据中,可以看到Biweekly High Rate列处于定比等级,因而可以进行新的观察
# 那个工资最高
fig = plt.figure(figsize=(15, 5))
ax = fig.gca()
salary_ranges.groupby('Grade')[['Biweekly High Rate']].mean().sort_values('Biweekly High Rate', ascending=False).head(20).plot.bar(stacked=False, ax=ax, color='darkorange')
ax.set_title('Top 20 Grade by Mean Biweekly High Rate')
Text(0.5, 1.0, 'Top 20 Grade by Mean Biweekly High Rate')

# 哪个工作工资最低
fig = plt.figure(figsize=(15, 5))
ax = fig.gca()
salary_ranges.groupby('Grade')[['Biweekly High Rate']].mean().sort_values('Biweekly High Rate', ascending=False).tail(20).plot.bar(stacked=False, ax=ax, color='darkorange')
ax.set_title('Bottom 20 Grade by Mean Biweekly High Rate')
Text(0.5, 1.0, 'Bottom 20 Grade by Mean Biweekly High Rate')

# 计算最高工资和最低工资的比值
sorted_df = salary_ranges.groupby('Grade')[['Biweekly High Rate']].mean().sort_values('Biweekly High Rate', ascending=False)
sorted_df.iloc[0][0] / sorted_df.iloc[-1][0]
13.931919540229886
每个等级上可行与不可行的操作
3、跟练
运用上面所学知识,让我们来对GlobalLandTemperaturesByCountry.csv数据进行探索性分析,尝试独自写出代码
# 1、读取GlobalLandTemperaturesByCountry.csv数据
# 存储表格数据
import pandas as pd
# 数据计算包
import numpy as np
# 数据可视化包
import matplotlib.pyplot as plt
import seaborn as sns
# 允许行内渲染图形
%matplotlib inline
# 流行的数据可视化主题
plt.style.use('fivethirtyeight')
# 到导入数据集 温度数据集
df = pd.read_csv('./data/GlobalLandTemperatures/GlobalLandTemperaturesByCountry.csv')
# 查看前几行
df.head()
| dt | AverageTemperature | AverageTemperatureUncertainty | Country | |
|---|---|---|---|---|
| 0 | 1743-11-01 | 4.384 | 2.294 | Åland |
| 1 | 1743-12-01 | NaN | NaN | Åland |
| 2 | 1744-01-01 | NaN | NaN | Åland |
| 3 | 1744-02-01 | NaN | NaN | Åland |
| 4 | 1744-03-01 | NaN | NaN | Åland |
# 2、移除缺失值
df.dropna(axis = 0,inplace = True)
# 3、检查缺失值
df.isnull().sum()
dt 0
AverageTemperature 0
AverageTemperatureUncertainty 0
Country 0
dtype: int64
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 544811 entries, 0 to 577460
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 dt 544811 non-null object
1 AverageTemperature 544811 non-null float64
2 AverageTemperatureUncertainty 544811 non-null float64
3 Country 544811 non-null object
dtypes: float64(2), object(2)
memory usage: 20.8+ MB
# 4、对数据的频率进行可视化
df['AverageTemperature'].plot(kind='hist')
<AxesSubplot:ylabel='Frequency'>

# 5、对AverageTemperature进行描述下分析
df['AverageTemperature'].describe()
count 544811.000000
mean 17.193354
std 10.953966
min -37.658000
25% 10.025000
50% 20.901000
75% 25.814000
max 38.842000
Name: AverageTemperature, dtype: float64
# 6、可视化每个国家的温度分布情况
df.groupby('Country')['AverageTemperature'].apply(lambda x:x.hist(bins=20))
Country
Afghanistan AxesSubplot(0.08,0.07;0.87x0.81)
Africa AxesSubplot(0.08,0.07;0.87x0.81)
Albania AxesSubplot(0.08,0.07;0.87x0.81)
Algeria AxesSubplot(0.08,0.07;0.87x0.81)
American Samoa AxesSubplot(0.08,0.07;0.87x0.81)
...
Western Sahara AxesSubplot(0.08,0.07;0.87x0.81)
Yemen AxesSubplot(0.08,0.07;0.87x0.81)
Zambia AxesSubplot(0.08,0.07;0.87x0.81)
Zimbabwe AxesSubplot(0.08,0.07;0.87x0.81)
Åland AxesSubplot(0.08,0.07;0.87x0.81)
Name: AverageTemperature, Length: 242, dtype: object

# 7、探索温度随时间的变化趋势
df['dt'] = pd.to_datetime(df['dt'])
df.set_index('dt')['AverageTemperature'].plot(figsize=(15,6))
<AxesSubplot:xlabel='dt'>

df.set_index('dt')['AverageTemperature'].resample('40A').mean().plot(figsize=(15, 6), title='Temperature Trend Over 40 Years')
<AxesSubplot:title={'center':'Temperature Trend Over 40 Years'}, xlabel='dt'>

# 8、绘制温度的箱线图
df.boxplot(column='AverageTemperature')
<AxesSubplot:>

4、闯关题
STEP1:根据要求完成题目
答题说明:
请在题目下方的答题Code Cell中输入你的答案,并按照步骤说明完成你的提交。
请注意,一定要按照顺序依次运行下方的代码,否则会出现报错喔!
答案全部为大写字符串、无任何分隔符(如:a1 =‘A’ 或 a1 =‘AB’)
STEP1:根据要求完成题目
Q1. (多选)下面哪些数据属于定量数据?
A. 班级里的学生姓名
B. 工资月收入
C. 客服反馈用户投诉
D. 摄氏度表示的气温
Q2. (单选)以下哪些选项为正确选项?
A. 定性数据可以计算定比
B. 定量数据可以计算定序
C. 定性数据可以计算定类
Q3. (单选)选出以下错误的选项?
A. 定类数据可以绘制饼图
B. 定序数据可以绘制条形图
C. 定距数据可以绘制直方图
D. 定比数据可以绘制饼图
答案是 D. 定比数据可以绘制饼图。
解释:
- A. 定类数据可以绘制饼图:正确。定类数据(如分类数据)适合使用饼图来显示各类别的比例。
- B. 定序数据可以绘制条形图:正确。定序数据(如有顺序的分类数据)适合使用条形图来表示不同类别的频数或比例。
- C. 定距数据可以绘制直方图:正确。定距数据(如间隔数据)可以使用直方图来展示数据的分布。
- D. 定比数据可以绘制饼图:错误。虽然定比数据可以用来绘制饼图,但这并不是定比数据的最佳可视化方式。定比数据更适合使用条形图、折线图或散点图等来显示比例和比较。
因此,选项 D 是错误的。
#填入你的答案并运行,注意大小写
a1 = 'BD' # 如 a1= 'AB'
a2 = 'C' # 如 a2= 'B'
a3 = 'D' # 如 a3= 'B'















 9768
9768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









