







 文章讲述了电商公司商品部门面临的关键商品竞品信息监测挑战,通过介绍一个基于Selenium和Tkinter的自动化爬虫工具,实现淘宝商品价格、销量等数据的定期抓取,以便进行数据分析,辅助决策。
文章讲述了电商公司商品部门面临的关键商品竞品信息监测挑战,通过介绍一个基于Selenium和Tkinter的自动化爬虫工具,实现淘宝商品价格、销量等数据的定期抓取,以便进行数据分析,辅助决策。
项目概况
1.1 问题描述
某电商公司的商品部门负责运营公司旗下的几百种商品。为了更好了解商品的价格趋势、销售热度和竞品信息,商品部门需要定期监测关键商品及其竞品的信息。但是,公司旗下有很多商品,竞品众多且信息又分布在各大电商平台的搜索结果页面中,要手动查询和监测这么多商品信息,工作量实在太大,消耗时间和人力的同时也难以全面覆盖所有的商品和信息。
为解决此问题,商品部门希望有一个自动化的解决方案,能定期自动爬取关键商品及其竞品的信息,包括价格、月销量、店铺等数据。得到这些信息后,商品部门分析人员只需要对信息进行分析整理,就可以轻松发现主商品的价格变化趋势、竞品的销量状况、潜在商机等,这些信息可以帮助公司及时调整策略,对主商品的定价和竞品的应对有非常重要的参考价值。
1.2 程序流程

项目仓库
taobao-crawler-selenium: 基于 Selenium 和 Tkinter 的爬取淘宝商品的Web自动化工具 (gitee.com)
youngzm339/taobao-crawler-selenium: 基于 Selenium 和 Tkinter 的爬取淘宝商品的Web自动化工具 (github.com)
使用指南
安装依赖
- 确保已经正确安装Python
- 安装requirements.txt中的依赖
安装WebDriver驱动
注意需要使用与您浏览器安装版本相对应的WebDriver,
本工具代码为Google Chrome提供适配:
Google Chrome WebDriver
如果使用其它游览器,请自行寻找所使用游览器的WebDriver驱动,并更改源代码文件中游览器有关参数为你所使用游览器的参数
options = webdriver.ChromeOptions()
browser = webdriver.Chrome(options=options)
修改settings.ini
格式:
<所需关键词>
<起始页码>
<终止页码>
例如
阿迪达斯运动鞋
1
10
启动
python ./taobaoCrawler.py
流程图
效果图
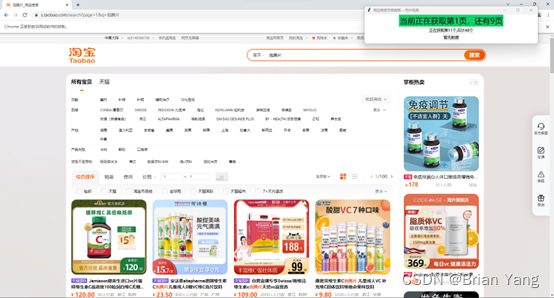
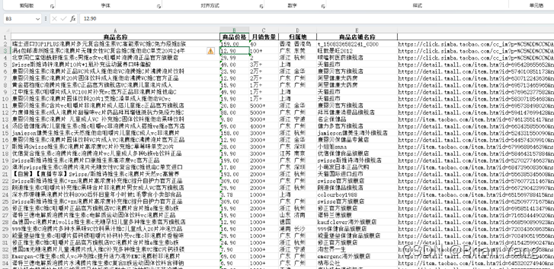















 201
201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









