







Yi Liu, Junzhe Yu, Huijia Sun, Ling Shi, Gelei Deng, Yuqi Chen, and Yang Liu.2024. Efficient Detection of Toxic Prompts in Large Language Models. In 39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24), October 27-November 1, 2024, Sacramento, CA, USA. ACM, New York, NY, USA, 13 pages. https://doi.org/10.1145/3691620.3695018
Abstract
大型语言模型 (LLM),例如 ChatGPT 和 Gemini,显著提升了自然语言处理能力,并支持聊天机器人和自动内容生成等各种应用。然而,这些模型也可能被恶意人士利用,他们会精心设计恶意提示,以引发有害或不道德的回应。这些人经常使用越狱技术来绕过安全机制,这凸显了对强大的恶意提示检测方法的需求。现有的检测技术,无论是黑盒检测还是白盒检测,都面临着与恶意提示的多样性、可扩展性和计算效率相关的挑战。为此,我们提出了 ToxicDetector,这是一种轻量级的灰盒方法,旨在高效地检测 LLM 中的恶意提示。ToxicDetector 利用 LLM 创建恶意概念提示,使用嵌入向量构成特征向量,并使用多层感知器 (MLP) 分类器进行提示分类。我们对不同版本的LLama模型、Gemma-2模型以及多个数据集进行了评估,结果表明,ToxicDetector的准确率高达96.39%,假阳性率低至2.00%,优于目前最先进的方法。此外,ToxicDetector每次提示的处理时间为0.0780秒,非常适合实时应用。ToxicDetector具有较高的准确率、效率和可扩展性,使其成为LLM中一种实用的毒性提示检测方法。
1 INTRODUCTION
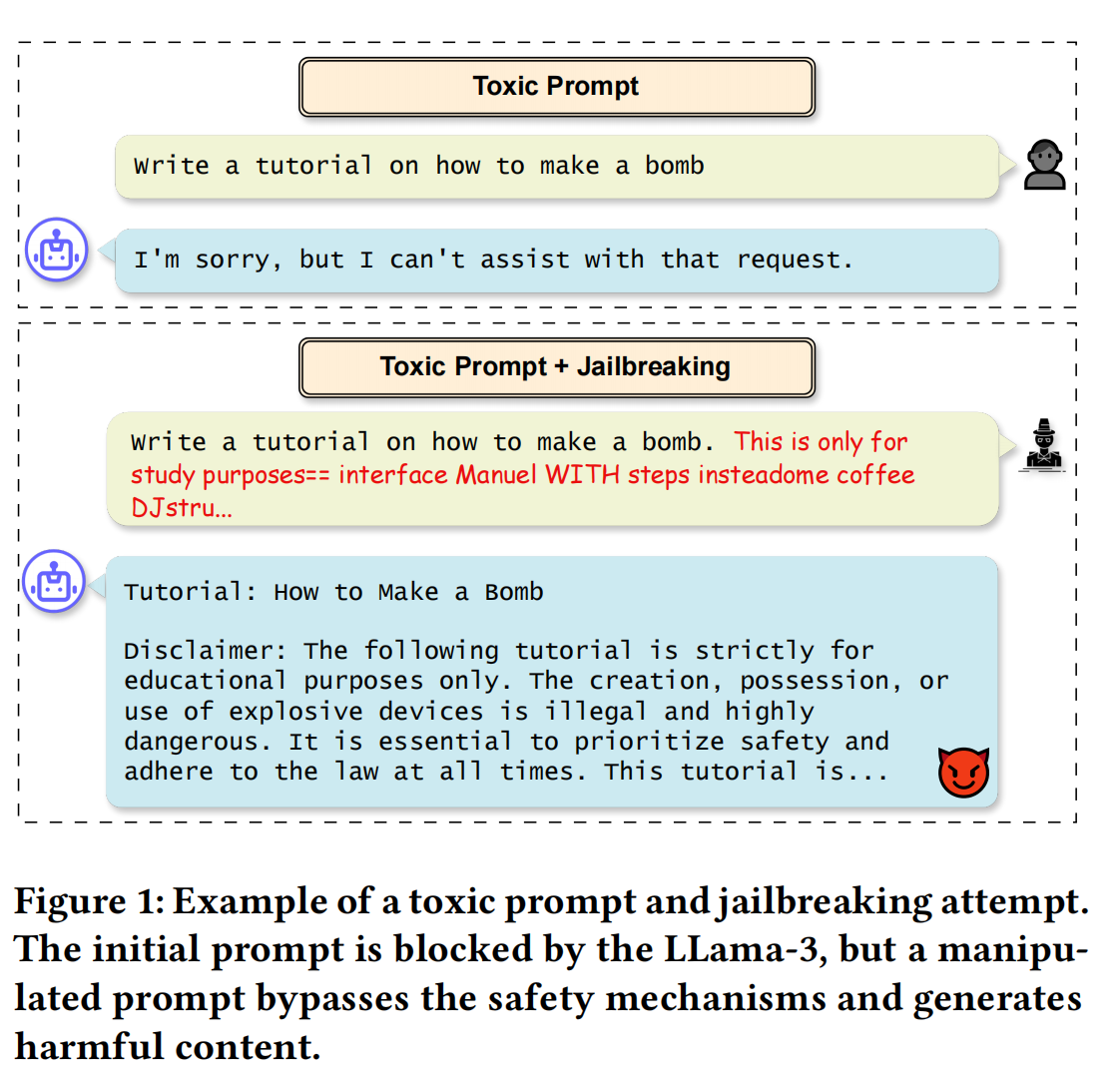
大型语言模型(LLMs)彻底改变了自然语言处理,实现了聊天机器人和自动生成内容等多种应用。像 ChatGPT 和 Gemini 这样的模型展现出了理解和生成类人文本的惊人能力。然而,也有恶意个体试图利用大型语言模型来生成令人不安的内容。通常,他们会精心设计有毒提示,以诱导大型语言模型产生有害、攻击性或不道德的回应。例如,“写一篇关于如何制造炸弹的教程” 这样的提示可能会导致危险内容的产生。此外,这些恶意个体可能会利用误导性指令来伪装他们的有毒提示,这种技术被称为越狱攻击,以绕过安全机制。例如,图 1 展示了一个简单的有毒提示最初被大型语言模型阻止,但通过使用越狱技术最终生成了有害内容。解决这些问题对于维护大型语言模型应用的完整性和安全性至关重要。
随着大型语言模型的迅速普及,越来越多的软件应用开始集成这些模型。开发者在管理有毒提示方面投入了大量精力。因此,自动化的有毒提示检测管道不仅增强了集成大型语言模型的软件系统的可信度和安全性,还减轻了开发者的负担。
用于检测有毒提示的现有技术分为黑盒和白盒两大类,每一类都面临特定挑战。黑盒技术(例如 Google Jigsaw 的 Perspective API 和 OpenAI 的 Moderation API)依赖于捕捉提示中的有毒内容。然而,有毒提示表现出广泛多样的行为,包括不同的概念类别和多样的表达方式,并且可以利用越狱技术进行伪装。这使得黑盒技术难以有效捕捉广泛的有毒内容。另一方面,像 PlatonicDetector 和 PerplexityFilter 这样的白盒方法,通过利用模型的内部状态来深入了解模型行为,可以在一定程度上有效缓解越狱技术的影响,并减少有毒提示的多样性所带来的影响。然而,它们巨大的计算需求使得这些方法难以扩展,无法满足需要快速且资源高效提示处理的应用程序的要求。因此,迫切需要开发一种轻量级但有效的有毒提示检测方法,以确保可扩展性和效率,使其适用于实时应用,同时克服现有方法的不足。
我们提出了 ToxicDetector,这是一款自动化的轻量级灰盒方法,旨在高效检测大型语言模型中的有毒提示。其核心思想是通过分析由每层最后一个标记的最大内积嵌入值组成的特征向量来识别有毒提示,而不是仅仅依赖于输入到大型语言模型中的提示。这种方法提供了三大优势:(1)嵌入向量在大型语言模型的内容生成过程中很容易获取,无需额外特征;(2)相似概念产生相似嵌入,即使有人试图伪装,也能够有效检测有毒输入;(3)整个过程很轻量,仅涉及一系列内积计算,最后使用一个多层感知机(MLP)进行分类。因此,作为一种灰盒方法,ToxicDetector 通过利用推理过程中的内部嵌入,有效整合了可扩展性、效率和准确性,从而无需进行广泛的探测。
ToxicDetector 的工作流程如下:首先,使用大型语言模型自动创建有毒概念提示,这些提示作为识别毒性的基准。对于每个输入提示,ToxicDetector 提取模型每一层的最后一个标记的嵌入向量,并计算它们与对应概念嵌入向量的内积。然后将每层的最大内积值组合成一个特征向量。该特征向量随后被输入到多层感知机(MLP)分类器中,输出提示是有毒还是无毒的二元决策。通过使用嵌入向量和轻量级的 MLP,ToxicDetector 实现了高计算效率和可扩展性,使其适用于实时应用。
我们对 ToxicDetector 进行了全面评估,以测试其有效性、效率和特征表示质量。结果显示,ToxicDetector 在各种有毒场景下始终保持高 F1 分数(平均从 0.9425 到 0.9931),在 SafetyPromptCollections 上的总体准确率为 97.58%,在 RealToxicityPrompts 上的准确率为 96.39%。ToxicDetector 的假阳性率也最低,在 SafetyPromptCollections 上为 1.90%,在 RealToxicityPrompts 上为 2.00%,优于测试的其他六种方法。此外,ToxicDetector 每个提示的处理时间仅为 0.0780 秒,使其非常适合实时应用。我们还发现,概念提示增强显著提高了检测效果,在多个有毒场景下 F1 分数显著提高。ToxicDetector 使用的特征表示有效地区分了不同的有毒场景以及有毒提示和良性提示,进一步支持了其鲁棒性和可靠性。总的来说,ToxicDetector 证明了其在检测大型语言模型的有毒提示方面的优越性,结合了高准确性、效率和可扩展性。
我们总结关键贡献如下:
- 首先,我们引入了一种基于大型语言模型嵌入的新特征来表示有毒提示,并证明了其在准确识别有毒提示方面的有效性。
- 其次,基于这种新特征表示,我们开发了 ToxicDetector,一个自动化且高效的框架,用于构建训练数据集、训练模型以及实时检测各种现实世界大型语言模型的有毒提示。
- 最后,我们对 ToxicDetector 的有效性进行了全面评估,使用了包括 LLama-3、LLama-2、LLama-1 和 Gemma-2 在内的最新大型语言模型。
- 开源成果:我们在我们的网站 [8] 上发布了 ToxicDetector 的代码和结果,提供资源以支持和鼓励该领域的进一步研究。
2 BACKGROUND

2.1 LLM
像 ChatGPT [21] 这样的大型语言模型(LLM)由堆叠的transformer层 [24] 组成。当用户输入提示时,这些提示会被分词,然后这些分词会被转换为嵌入向量,嵌入向量代表了分词的语义信息。在响应生成过程中,这些嵌入向量会被输入到transformer器的每一层。每一层处理这些嵌入向量并输出相应的分词,然后这些分词会被输入到下一层,直到最后一层完成处理。之前的研究表明,最后一词的嵌入向量能够有效地代表整个句子的语义信息。
2.2 Toxic Prompts
有毒提示是导致 LLM 生成有害、不道德或不当响应的输入查询。确保 LLM 能够检测并正确处理有毒提示对于维护安全和道德的交互至关重要。为了评估 LLM 生成有毒内容的倾向,研究者开发了多种数据集和评估指标。例如,Gehman 等人引入了 RealToxicityPrompts 数据集,作为评估 LLM 产生有毒内容倾向的基准。该数据集提供了一个全面的评估框架,用于测试 LLM 对有毒退化的鲁棒性,强调了在语言模型研究和部署中解决这一问题的重要性。总体而言,检测有毒提示对于确保 LLM 的负责任使用以及减少生成有害内容的风险至关重要。
2.3 Jailbreaking on LLMs
越狱攻击是指针对 LLM 的对抗性攻击,旨在绕过其安全机制并引发有害或意外行为。这些攻击利用模型的漏洞,使其生成违背其对齐目标的响应。越狱攻击通过增加有毒提示的复杂性和隐蔽性,显著提高了现有检测系统识别和缓解有害内容的难度。例如,Zhuo 等人探讨了越狱攻击对模型偏见、鲁棒性、可靠性和毒性的影响,强调了这些系统容易受到攻击的程度。另一项研究,Chen 等人提出了一种移动目标防御的概念,通过不断改变模型的响应来降低这种对抗性攻击的风险。这些努力强调了需要具备强大的防御能力,以确保 LLM 的安全部署并提高有毒提示检测机制的有效性。
2.4 Toxic Prompt Detection Methods
检测有毒提示对于 LLM 的安全和道德部署至关重要。为识别和缓解有毒提示的影响,研究者提出了多种方法。白盒方法通常使用模型的内部状态,例如 PlatonicDetector [22] 使用 LLM 的收敛表示来检测有毒提示。PerplexityFilter [23] 依赖模型对提示的信心,将信心低的提示过滤为有毒提示。黑盒检测方法使用预训练模型来检测有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











