







 本文介绍了Iceberg数据库如何支持表结构的动态演化,包括添加、删除和修改列、字段,以及更新排序和分区。强调了元数据更新的原子性和无副作用特性,以及如何通过Spark进行维护操作,如过期快照、数据文件压缩和重写清单文件以提高查询性能。
本文介绍了Iceberg数据库如何支持表结构的动态演化,包括添加、删除和修改列、字段,以及更新排序和分区。强调了元数据更新的原子性和无副作用特性,以及如何通过Spark进行维护操作,如过期快照、数据文件压缩和重写清单文件以提高查询性能。
Evolution
Iceberg 支持就底表演化。您可以像 SQL 一样演化表结构——即使是嵌套结构——或者当数据量变化时改变分区布局。Iceberg 不需要像重写表数据或迁移到新表这样耗费资源的操作。
例如,Hive 表的分区布局无法更改,因此从每日分区布局变更到每小时分区布局需要新建一个表。而且因为查询依赖于分区,所以必须为新表重写查询。在某些情况下,即使是像重命名一个列这样简单的变化要么不被支持,要么可能导致数据正确性问题。
Schema evolution(Schema演变)
Iceberg 支持以下模式演变更改:
- 添加 – 在表中或嵌套结构中添加一个新列
- 删除 – 从表中或嵌套结构中移除一个已有的列
- 重命名 – 重命名一个已有的列或嵌套结构中的字段
- 更新 – 扩展列、结构字段、映射键、映射值或列表元素的类型
- 重新排序 – 改变列或嵌套结构中字段的顺序
Iceberg 的架构更新是元数据更改,因此不需要重写任何数据文件来执行更新。
请注意,映射键不支持添加或删除会改变等值性的结构字段。
Correctness(正确性)
Iceberg 保证模式演化更改是独立的,没有副作用,且无需重写文件:
- 添加的列从不从另一个列读取现有值。
- 删除列或字段不会改变任何其他列中的值。
- 更新列或字段不会改变任何其他列中的值。
- 改变结构中列或字段的顺序不会改变与列或字段名相关联的值。
Iceberg 使用唯一的 ID 来跟踪表中的每一列。当您添加列时,它会被分配一个新的 ID,所以现有数据绝不会被错误使用。
- 按名称跟踪列的格式可能会在重用名称时无意中“取消删除”一个列,这违反了规则 #1。
- 按位置跟踪列的格式不能删除列而不改变用于每列的名称,这违反了规则 #2。
Iceberg 表的分区可以在现有表中更新,因为查询不会直接引用分区值。
当您演化一个分区规范时,使用早期规范编写的旧数据保持不变。新数据使用新的规范在新的布局中编写。每个分区版本的元数据分别保留。因此,当您开始编写查询时,您会得到分割规划。这是每个分区布局使用它为特定分区布局派生的过滤器分别计划文件的地方。这里有一个人为示例的视觉表示:
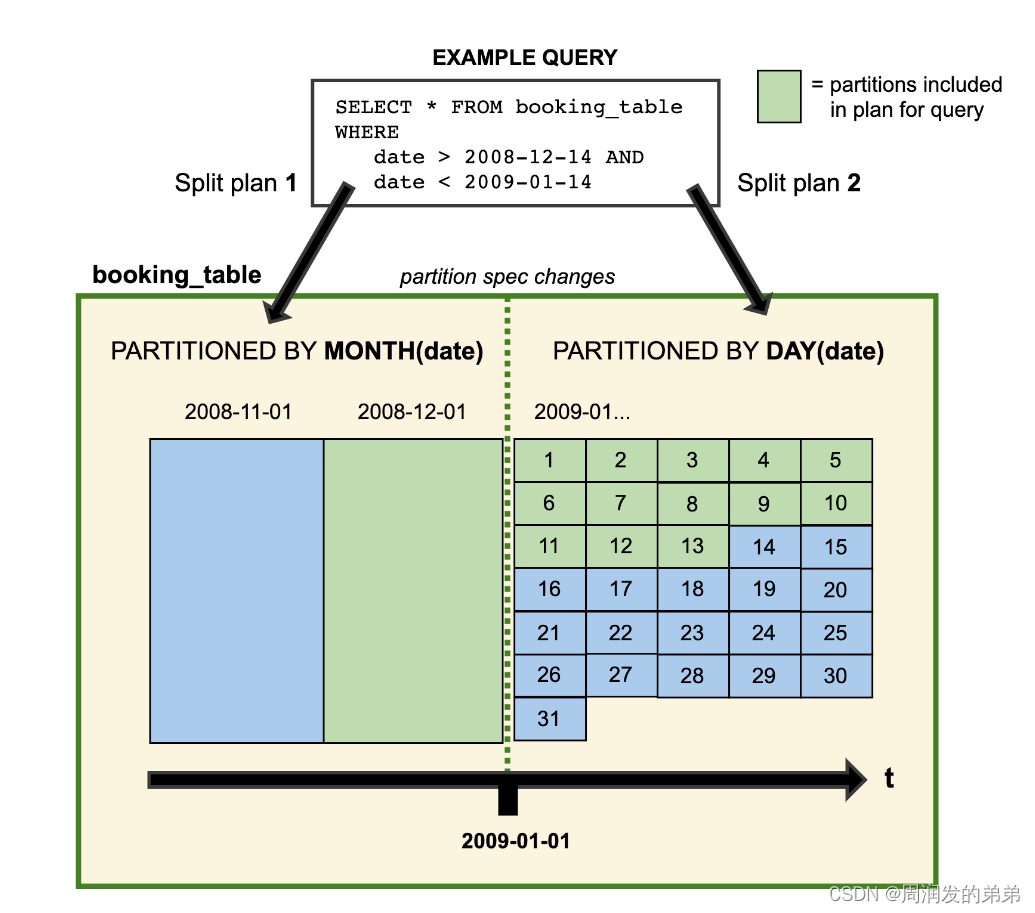
2008年的数据按月分区。从2009年开始,表更新,数据改为按天分区。两种分区布局能够在同一张表中共存。
Iceberg 使用隐藏分区,所以您不需要为了快速查询而编写特定分区布局的查询。相反,您可以编写选择您需要的数据的查询,Iceberg 会自动剪除不包含匹配数据的文件。
分区演化是一个元数据操作,并不会急切地重写文件。
Iceberg 的 Java 表 API 提供了 updateSpec API 来更新分区规范。例如,以下代码可以用来更新分区规范,添加一个新的分区字段,该字段将 id 列的值分成 8 个桶,并移除现有的分区字段 category:
Table sampleTable = ...;
sampleTable.updateSpec()
.addField(bucket("id", 8))
.removeField 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 87
87

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











