







pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包
pandas 是围绕着 Series 和 DataFrame 两个核心数据结构展开的
一、导入相关包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame二、创建对象:
(一)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
s = Series([1,3,5,7])
print sPS:如果list中有其他的数据类型,则会返回 object类型(多种数据类型;

(二)
Series允许传递index(左侧下标) 和 value (右侧下标),这里就和字典一样,不过value的表达是data
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
s = Series(index = ['a','b','c'] , data= [1,3,5])
print s
并且可以使用 s.index 和 s.values 来查询 , 这里是一一对应关系,但是又是相互独立的narray。
PS:Serise 还有name 属性, 可以定义 s.name 和 s.index.name , eg ---> s.name = 'a_series'
(三)
DataFrame是一个表格型的数据结构,它含有一组有序的列(类似于 index),每列可以是不同的值类型(不像 ndarray 只能有一个 dtype)。
基本上可以把 DataFrame 看成是共享同一个 index 的 Series 的集合。
DataFrame 的构造方法与 Series 类似,只不过可以同时接受多条一维数据源,每一条都会成为单独的一列:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
data = {'state':['china','china','china','japan','japan'] , 'year':['2012','2012','2013','2014','2015'],'pop':['1.5','1.6','1.7','1.8','1.9']}
df = DataFrame(data)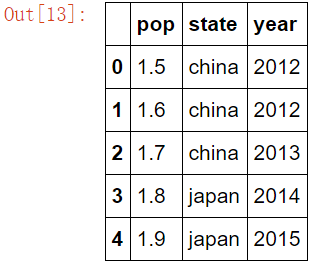
并且对于上述操作:
DataFrame(data=None,index=None,coloumns=None),coloumns就是name , 并且index可以修改左侧顺序的名称。
cloumns可以修改上面name的先后顺序,并且让权值对齐;
df = DataFrame(data,index = ['one','two','three','four','five'],columns=['year','pop','state','love'])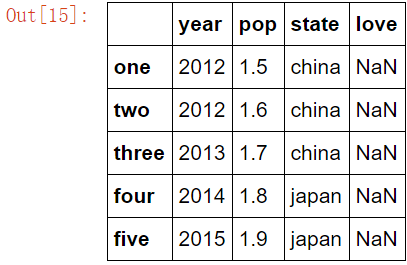
并且如果想提取出某一列的话,就对其进行如同C语言结构体的操作即可,
df.state
















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











