









1.样本均值:我们有n个样本,每个样本的观测值为Xi,那么样本均值指的是 1/n * ∑x(i),求n个观测值的平均值
2.数学期望:就是样本均值,是随机变量,即样本数其实并不是确定的
PS:从概率论的角度而言:样本指的是我们现在有多少东西需要去观测,它是一种随机变量,即样本的多少是不确定 的,我们得到的样本均值并不是真正意义上的期望。
3.期望:已知其观测值f(x)及其概率P,求其观测值与概率乘积的累加和,∑Xi*Pi
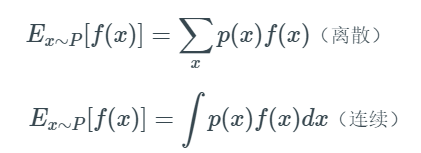
PS:期望是一种固定值,他的观测值是基于已知某几类数值及其概率,是不同于数学期望中的观测值Xi的,数学期望 的观测值有一点取决于样本数量的味道,也就是求和这里的n其实是不同的
4.方差:先看一下方差的公式
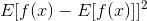
直观的说就是:观测值f(x)与其期望相减的差值的期望
换言之:方差反应的是观测值与其期望的偏差
PS:因为是与期望相减,所以这里的方差本质也是一个固定值而非随机变量
5.样本方差:
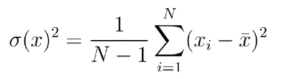
这里的观测值减去的是均值!均值的意思就是原本物质所存在的均值,即 1/n * ∑x(i)
而实际上我们可以得知方差的求解应该减去的是期望才对,其中的缘故在于我们并不能得知真正的期望是多少,
只能通过随机变量的样本求得一个近似的值来预估期望,即利用下式来证明:
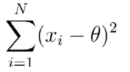
那么同理返回样本方差的等式,上式最小意味着利用样本均值求解样本方差会把真实方差算小了
因此将N处理成N-1来增大样本方差的值
引出两个结论:
(a)当分母为N-1的时候,是我们对方差做的一个无偏估计
(b)当分母为N的时候,是我们对方差做的一个极大似然估计
做一个小总结:
样本均值是数学期望,求的是n个观测值的平均值,而期望指的是观测值及其概率的乘积的累加和
在样本足够多的情况下,可以理解为样本均值趋近于期望E
即:1/n*∑x(i) ≈ ∑p(i)*x(i)
方差的本质是固定不变的,得到的是这个状态正儿八经与期望的偏差,
而样本方差是随机变量,得到的是也是一种偏差,只不过这种偏差是对正确偏差的一种估计值。
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











