






通过特定应用程序代码解耦语法
到目前为止,我们已经知道了怎么用ANTLR的语法来定义语言了,接下来我们要给我们的语法注入一些新的元素了。就语法本身而言,其用处并不大,因为它只能告诉我们一个用户输入的句子是否符合语言程序的语法规范。要建立一个完整的语言程序,我们就需要语法解析器在遇到特定的输入的时候能够产生对应的动作。“语法->动作”的映射对集合就是连接我们的语言程序(或者,至少是语言接口)的语法到大型实际相关应用之间的桥梁。
在这一章中,我们将要学习怎样使用语法分析树的监听器(listener)和访问器(visitor)来建立语言应用程序。当一个语法分析树遍历器发现或结束识别一个节点的时候,监听器就会响应对应的规则进入事件和规则退出事件(分析识别事件)。某些程序可能需要控制一棵语法树的遍历方式,为了满足这种需求,ANTLR生成的分析树同样也支持非常有名的访问者模式(visitor pattern)。
监听器和访问器之间最大的差别就是,监听器的方法不能通过调用特定的方法来访问子节点。而访问器则需要明确调用子节点,从而才能保证遍历过程继续下去(就如我们在第2.5节中看到的那样)。这是因为这些明确的调用过程,访问器才能够控制遍历的顺序已经遍历节点的数量。为了方便起见,我会用事件方法这个词来代指监听器回调方法或访问器方法。
这一章中,我们的目标是了解ANTLR为我们生成树访问工具的作用以及原理。首先,我们监听器的运行机制开始,了解我们怎样利用监听器和访问器嵌入我们的特定应用程序代码。然后,我们将学习怎样让ANTLR给规则的每个选项生成一个特定的方法。当我们对ANTLR的树遍历过程有了较深的了解之后,我们将看看三个计算器的实现例子,分别代表了三种不同的传递子表达式结果的方法。最后,我们将讨论下这三种传递方式的优缺点。完成了这些之后,我们就已经为下一章中的实例做好充足的准备了。
7.1 从动作代码嵌入到监听器的演化
如果你用过之前版本的ANTLR或者是其它编译器生成器,你一定会很惊讶,我们可以不使用嵌入动作代码就实现语言程序。监听器和访问器机制使得程序代码和语法分离开来(也就是所谓的解耦),这会产生很多令人兴奋的好处。这种解耦可以很好地将程序独立出来,而不是将其打散了分散到语法的各个部分中去。出去嵌入动作之后,我们可以实现语法重用,也就是几乎不需要重新生成语法分析器就可以将相同的语法应用到不同的程序中去。
没有了嵌入动作之后,ANTLR也可以实现用相同的语法使用不同的编程语言生成语法分析器。(我预期在4.0发布之后会开始支持不同的目标语言。)此外,语法错误的修改和语法更新也会变得更加容易,因为我们不用再担心会因为嵌入动作导致合并冲突。
在这一节,我们要探讨下从嵌入动作到语法完全独立的这个过程。下面展示了一个属性文件的语法规则,其中使用<<…>>的方式嵌入代码。像“<<start_file>>”这样的动作标识都表示这里有一段合适的Java代码。
grammar PropertyFile;
file : {«start file»} prop+ {«finish file»} ;
prop : ID '=' STRING '\n' {«process property»} ;
ID : [a-z]+ ;
STRING: '"' .*? '"';
这样的结合写法就将语法和一个特定的应用程序绑定到一起了。更好的做法是建立一个PropertyFileParser(由ANTLR生成的一个类)的子类,然后将嵌入代码转换成其成员函数。这样的做法可以在语法中仅保留对这些新建的函数的调用就可以了。然后,通过创建不同的子类,我们可以实现在不修改语法的前提下实现不同的程序。下面是一个这种实现的例子:
grammar PropertyFile;
@members {
void startFile(){ } // blank implementations
void finishFile(){ }
voiddefineProperty(Token name, Token value) { }
}
file : {startFile();} prop+ {finishFile();} ;
prop : ID '=' STRING'\n'{defineProperty($ID, $STRING)} ;
ID : [a-z]+ ;
STRING : '"' .*? '"';
这样可以实现语法的重用,但是这样的语法仍然和Java关联起来了,因为语法中使用的是Java语言的函数调用方式。我们将在稍后处理这个问题。
为了证明重构代码的可重用性,我们来建立两个简单的应用程序,第一个应用程序仅仅是简单地输出它识别到的属性。实现的过程也就是简单地扩展ANTLR自动生成的语法分析类,并重载几个语法中定义的方法。
class PropertyFilePrinterextendsPropertyFileParser {
void defineProperty(Token name, Token value) {
System.out.println(name.getText()+"="+value.getText());
}
}
这个类中,我们并没有重载startFile()和finishFile()这两个方法,因为在父类PropertyFileParser中已经由ANTLR自动生成了其默认实现了。在这里,我们并不想去改它。
要执行我们的代码,我们需要创建我们自己写的PropertyFileParser的子类的实例。
PropertyFileLexer lexer = newPropertyFileLexer(input);
CommonTokenStream tokens = newCommonTokenStream(lexer);
PropertyFilePrinter parser = newPropertyFilePrinter(tokens);
parser.file(); // launch our special version of the parser
第二个程序,我们将识别到的属性保存到一个map对象中,而不是直接输出来。我们需要做的所有改动仅仅是创建一个新的子类,并在defineProperty()函数中写入不同的代码。
class PropertyFileLoaderextendsPropertyFileParser {
Map<String,String> props =new OrderedHashMap<String,String>();
void defineProperty(Token name, Token value) {
props.put(name.getText(), value.getText());
}
}
语法分析程序执行完之后,props字段中就会填充上识别到的键值对了。
这个语法中还有一个问题存在,那就是嵌入动作限制了我们只能生成Java语言的程序。若是想要提高语法重用性并做到与目标语言无关,我们需要彻底不使用嵌入动作。在下面的两节中我们将展示如何使用监听器和访问器实现这一点。
7.2 使用分析树监听器实现语言程序
要建立一个独立于应用和语法的语言程序,关键在于用语法分析器创建一棵语法树,然后使用特定程序代码遍历这课语法树。我们可以自己手动编写代码来遍历这棵树,当然,我们也可以使用ANTLR生成的树遍历工具来实现。在这一节中,我们使用ANTLR内建的ParseTreeWalker来建立一个基于监听器版本的属性文件程序。
首先,我们看一下没有任何嵌入代码的属性文件语法。
listeners/PropertyFile.g4
file : prop+ ;
prop : ID '=' STRING'\n';
下面是一个样例的属性文件:
listeners/t.properties
user="parrt"
machine="maniac"
ANTLR会根据语法自动生成PropertyFileParser类,这个类会自动建立下面这样的语法分析树:
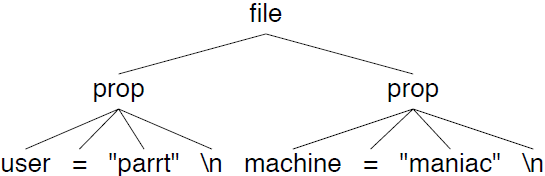
一旦我们建立了语法树之后,我们就可以使用ParseTreeWalker来遍历所有节点,并触发对应的进入事件和退出事件。
我们先来看看ANTLR根据PropertyFile语法自动生成的PropertyFileListener这个监听器接口。ParseTreeWalker在发现和离开节点的时候,会分别为每一个规则子树引发进入和退出事件。因为我们的PropertyFile语法中只有两个语法规则,所以接口中只有4个方法。
listeners/PropertyFileListener.java
import org.antlr.v4.runtime.tree.*;
import org.antlr.v4.runtime.Token;
public interface PropertyFileListenerextendsParseTreeListener {
void enterFile(PropertyFileParser.FileContext ctx);
void exitFile(PropertyFileParser.FileContext ctx);
void enterProp(PropertyFileParser.PropContext ctx);
void exitProp(PropertyFileParser.PropContext ctx);
}
FileContext和PropContext分别是语法分析树节点具体的实现对象。它们包含了很多有用的方法。
为了方便起见,ANTLR也生成了一个PropertyFileBaseListener类来提供接口函数的默认实现,就像我们在上一节中在@members区域中写的一样,这个类提供了所有函数的空实现方法。
public class PropertyFileBaseVisitor<T>extendsAbstractParseTreeVisitor<T>
implements PropertyFileVisitor<T>
{
@Override public T visitFile(PropertyFileParser.FileContextctx) { }
@Override public T visitProp(PropertyFileParser.PropContextctx) { }
}
(译者注:上面的代码出现得好像和文本描述的内容有点不相符,但是不影响理解。)
对接口的默认实现可以允许我们只对我们感兴趣的方法进行重载和实现。例如,下面的代码就是对属性文件加载器的再实现,它使用了监听器机制,却只有一个方法:
listeners/TestPropertyFile.java
public static class PropertyFileLoaderextends PropertyFileBaseListener {
Map<String,String> props = new OrderedHashMap<String, String>();
public void exitProp(PropertyFileParser.PropContext ctx){
String id = ctx.ID().getText(); // prop : ID '=' STRING '\n' ;
String value = ctx.STRING().getText();
props.put(id,value);
}
}
这个版本代码的主要特征就是其扩展了BaseListener,这个监听器的方法会在解析器完成后调用。
在这一步我们会接触到很多接口和类,下面,我们先看一看主要类和接口之间的继承关系是怎样的(接口用斜体表示)。
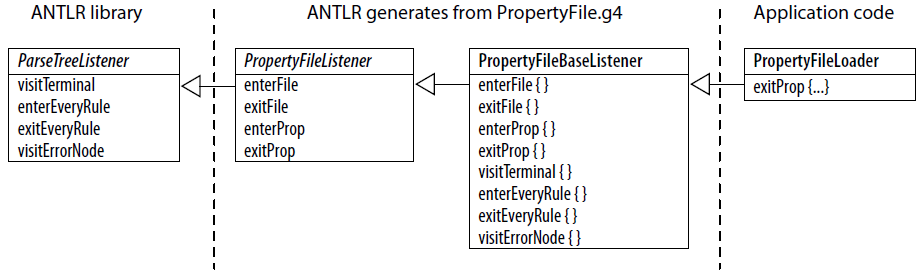
ParseTreeListener接口位于ANTLR运行时库当中,所有的监听器都继承自它,它决定了所有监听器都要响应visitTerminal(),enterEveryRule(),exitEveryRule()以及(依据语法错误)visitErrorNode()方法。ANTLR会根据PropertyFile语法生成PropertyFileListener接口,并生成了一个默认实现所有接口方法的类:PropertyFileBaseListener。唯一一个我们自己建立的类就是PropertyFileLoader,它从PropertyFileBaseListener哪里继承了所有的空实现的函数。
exitProp()方法访问了一个规则上下文对象:PropContext。这个对象是和prop规则紧密联系在一起的。也就是说,对于prop规则中定义的每一个元素(ID和STRING),上下文对象中都会对应有一个方法。由于这些元素正好都是语法中的词法节点(符号元素),所以这些对应的方法会返回语法树节点中的TerminalNode。我们可以直接通过getText()方法获得这些符号对应的文本内容,也可以通过getSymbol()方法获得这些符号的Token。
现在,我们可以做一些令人兴奋的事情了。让我们来遍历这棵树,然后通过新的PropertyFileLoader来进行监听。
listeners/TestPropertyFile.java
// create a standard ANTLR parse treewalker
ParseTreeWalker walker = new ParseTreeWalker();
// create listener then feed to walker
PropertyFileLoader loader = new PropertyFileLoader();
walker.walk(loader, tree); // walk parse tree
System.out.println(loader.props);// print results
下面,我们复习下怎样运行一个ANTLR语法,首先将生成的代码进行编译,然后启动一个测试程序来处理输入文件:
$ antlr4 PropertyFile.g4
$ ls PropertyFile*.java
PropertyFileBaseListener.java PropertyFileListener.java
PropertyFileLexer.java PropertyFileParser.java
$ javac TestPropertyFile.java PropertyFile*.java
$ cat t.properties
user="parrt"
machine="maniac"
$ java TestPropertyFile t.properties
{user="parrt",machine="maniac"}
我们的测试程序成功地将属性赋值文本转换成内存中的map数据结构了。
基于监听器的方法是一个很不错的方法,因为所有的树节点遍历以及相应的方法都是自动进行的。然而,在某些场合下,当我们需要控制遍历的过程的时候,就不能用自动遍历这个方法了。例如,我们需要遍历一个C程序的语法树,希望跳过函数体语法子树,即忽略函数的函数体部分。此外,监听器无法使用函数返回值来传递数据。要解决以上问题,我们需要使用到访问者模式。下面,让我们建立一个基于访问者模式的属性加载器,进而对比这两种方式的优缺点。
7.3 使用访问器来实现语言程序
要使用访问器来取代监听器,我们需要让ANTLR生成访问器接口,实现这个接口,然后再创建一个测试程序调用visit()方法来访问语法树。这一节中,我们并不需要修改语法的任何信息。
在命令行中使用-visitor参数,ANTLR就会生成PropertyFileVisitor接口和一个默认实现了所有方法的PropertyFileBaseVisitor类:
public class PropertyFileBaseVisitor<T>extends AbstractParseTreeVisitor<T>
implements PropertyFileVisitor<T>
{
@Overridepublic T visitFile(PropertyFileParser.FileContextctx) { ... }
@Overridepublic T visitProp(PropertyFileParser.PropContextctx) { ... }
}
我们可以将监听器中的exitProp()函数体拷贝到visitor中关于prop规则的方法中。
listeners/TestPropertyFileVisitor.java
public static class PropertyFileVisitorextends
PropertyFileBaseVisitor<Void>
{
Map<String,String> props = new OrderedHashMap<String, String>();
public Void visitProp(PropertyFileParser.PropContext ctx){
String id = ctx.ID().getText(); // prop : ID '=' STRING '\n' ;
String value = ctx.STRING().getText();
props.put(id,value);
return null; // Java says must return something evenwhen Void
}
}
(译者注:这段代码所属的java文件名可能不对,我觉得文件名应该是PropertyFileVisitor.java)。
为了更好地和上一节所讲的监听器版本做比较,下面列出了访问器接口和类的继承关系:
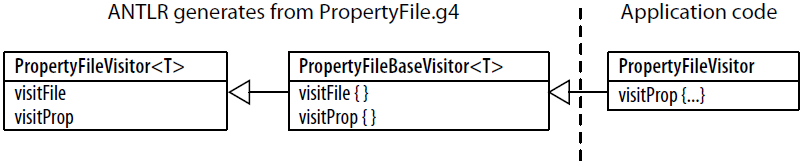
访问器通过明确调用ParseTreeVisitor接口中子节点的visit()方法来遍历语法树。visit方法是从AbstractParseTreeVisitor中实现的。在这个例子中,prop节点的调用中并没有包含任何子节点,所以visitProp()方法并不需要调用visit()方法。我们将在后面看到访问器的泛型类型参数。
监听器和访问器的测试代码中,最大的差距在于访问器不需要一个ParseTreeWalker。它们直接使用访问器自身来遍历解析器创建的树。
listeners/TestPropertyFileVisitor.java
PropertyFileVisitor loader = new PropertyFileVisitor();
loader.visit(tree);
System.out.println(loader.props);// print results
一切都准备就绪之后,下面是建立和测试的结果:
$ antlr4 -visitor PropertyFile.g4 # create visitor as well this time
$ ls PropertyFile*.java
PropertyFileBaseListener.java PropertyFileListener.java
PropertyFileBaseVisitor.java PropertyFileParser.java
PropertyFileLexer.java PropertyFileVisitor.java
$ javac TestPropertyFileVisitor.java
$ cat t.properties
user="parrt"
machine="maniac"
$ java TestPropertyFileVisitor t.properties
{user="parrt", machine="maniac"}
使用访问器和监听器,我们几乎能完成所有事情了。当我们进入Java的空间的时候,就已经和ANTLR没有半毛钱关系了。我们需要知道的仅仅是语法间的关系,生成的语法树,以及访问器和监听器的事件方法。除了这些,剩下的就是你的代码编写能力了。为了响应我们识别到的输入短语,我们可以生成输出,并收集信息(就像我们之前做的那样),并通过特定方法激活短语,或进行计算。
这个读取属性文件的例子非常的简单,所以我们不用考虑到带有选项分支的规则。默认情况下,不管解析器匹配到一条规则的哪一个选项,ANTLR都只是会给一条规则只生成单一的一个事件方法。这样是十分不方便的,因为绝大多数情况下,访问器或监听器都必须知道解析器匹配的是哪条规则。在下一节,我们将要更细致地讨论下事件方法。
7.4 通过标记规则选项来指定事件方法
为了更好地说明问题,让我们试着用监听器去根据下面的表达式语法来实现一个简单的计算器程序:
listeners/Expr.g4
grammar Expr;
s : e ;
e : e op=MULT e // MULT is '*'
| e op=ADD e // ADD is '+'
| INT
;
显然,e规则会产生一个相当无用的监听器,因为所有e规则的选项只会在树遍历器中引发同样的方法enterE()和exitE()。
public interface ExprListenerextends ParseTreeListener {
void enterE(ExprParser.EContext ctx);
void exitE(ExprParser.EContext ctx);
...
}
为了知道监听器方法中匹配的是e子树中的哪条规则,我们不得借助ctx对象中的op标签来进行判断。
listeners/TestEvaluator.java
public void exitE(ExprParser.EContextctx) {
if ( ctx.getChildCount()==3 ) { // operations have 3 children
int left = values.get(ctx.e(0));
int right = values.get(ctx.e(1));
if ( ctx.op.getType()==ExprParser.MULT ) {
values.put(ctx,left * right);
}
else {
values.put(ctx,left + right);
}
}
else {
values.put(ctx,values.get(ctx.getChild(0))); // an INT
}
}
exitE()方法中出现的MULT字段是由ANTLR在ExprParser中自动生成的:
public class ExprParserextends Parser {
public static final int MULT=1, ADD=2, INT=3, WS=4;
...
}
观察下ExprParser类中的EContext子类,我们可以发现ANTLR将e规则中三个选项中的所有元素都收集起来放到同一个上下文对象中。
public static class EContextextends ParserRuleContext {
public Token op; // derived fromlabel op
public List<EContext> e() { ... } // get all e subtrees
public EContext e(int i) {... } // get ith e subtree
public TerminalNode INT() { ... } // get INT node if alt 3 of e
...
}
在ANTLR中,我们可以使用#运算符来给一个规则最外层的选项命名,从而生成监听器中更多的事件方法。我们从Expr引申出新语法LExpr,并用这种方法给e的选项命名。下面是修改后的e规则:
listeners/LExpr.g4
e : e MULT e # Mult
| e ADD e # Add
| INT # Int
;
现在,ANTLR会根据e的不同的选项生成不同的监听器方法。这样之后,我们就不再需要op这个标签了。对于每个选项标签X,ANTLR都会生成enterX()和exit()两个方法。
public interface LExprListenerextends ParseTreeListener {
void enterMult(LExprParser.MultContext ctx);
void exitMult(LExprParser.MultContext ctx);
void enterAdd(LExprParser.AddContext ctx);
void exitAdd(LExprParser.AddContext ctx);
void enterInt(LExprParser.IntContext ctx);
void exitInt(LExprParser.IntContext ctx);
...
}
需要注意的是,ANTLR同时也会根据每个选项的标签名生成特定的上下文对象(EContext的子类)。这些特定的上下文对象只能访问其对应语法选项中特定的元素。比如,IntContext仅仅只有一个INT()方法。我们能够在enterInt()中调用ctx.INT(),但是在enterAdd()中却无法调用这个方法。
监听器和访问器是十分不错的工具,借助它们,我们可以让我们的语法有着很高的可重用性和可重定向性,甚至实现封装语言的应用,而我们要做的仅仅是更新下事件方法的代码。ANTLR同时也会给我们生成框架代码。事实上,到目前为止,我们建立的应用程序都还没有遇到需要共同实现的问题,也即,事件方法有时候需要彼此之间传递一些部分结果或其他信息。
7.5 在事件方法之间共享信息
不管是收集信息还是计算数值,通过参数和返回值进行信息共享,对比于通过全局变量的形式而言,即方便,又能体现出良好的编程习惯。现在问题来了,ANTLR自动生成的函数签名是不包含参数和返回值类型的。同样,ANTLR生成的访问器方法也是不带特定参数的。
在这一节中,我们要继续在不修改事件方法签名的前提下在事件方法之间传递参数的方案。基于上一节的LExpr语法,我们要建立三种不同的实现方法。第一种实现方法使用了访问器方法的返回值,第二种方法定义了一个共享事件方法的字段,第三种方法通过标记语法树节点来贮存感兴趣的值。
利用访问器遍历语法树
要建立一个基于访问器的计算器,最简单的方法就是通过返回子表达式的值来联系expr下的各个规则元素。例如,visitAdd()应该返回两个子表达式的和。visitInt()应该返回整数的值。传统的访问器并不指定它们访问方法的返回值。给访问器添加返回值类型并不难,只需要扩展LExprBaseVisitor<T>,并把T参数指定为我们需要的Integer就可以了。下面是我们的访问器的代码:
listeners/TestLEvalVisitor.java
public static class EvalVisitorextends LExprBaseVisitor<Integer> {
public Integer visitMult(LExprParser.MultContext ctx) {
return visit(ctx.e(0)) * visit(ctx.e(1));
}
public Integer visitAdd(LExprParser.AddContext ctx) {
return visit(ctx.e(0)) + visit(ctx.e(1));
}
public Integer visitInt(LExprParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
}
EvalVisitor继承了ANTLR中AbstractParseTreeVisitor类的visit()方法,我们在访问器中将会使用这个方法来访问子树。
你可能注意到了EvalVisitor中并没有关于规则s的访问器方法。在LExprBaseVisitor中默认实现的visitS()方法会调用预定义的ParseTreeVisitor.visitChildren()方法。visitChildren()方法会返回最后一个访问的子节点的返回值。在我们的例子当中,visitS()会返回它惟一一个子节点(e节点)所计算的表达式的返回值。就此而言,我们可以直接使用其默认实现。
在测试文件TestLEvalVisitor.java中,我们使用常规代码来启动LExprParser,并输出语法树。然后,我们需要写代码来启动EvalVisitor,并在访问树的时候将计算到的表达式的值输出。
listeners/TestLEvalVisitor.java
EvalVisitor evalVisitor = new EvalVisitor();
int result= evalVisitor.visit(tree);
System.out.println("visitor result = "+result);
建立我们的计算器的时候,我们通知ANTLR生成访问器,我们可以像在属性文件解析时那样使用-visitor选项。(如果我们希望不要生成监听器的话,可以使用-no-listener选项。)下面是完整的建立和测试命令:
➾$ antlr4 -visitor LExpr.g4
➾$ javac LExpr*.java TestLEvalVisitor.java
➾$ java TestLEvalVisitor
➾1+2*3
➾EOF
<(s (e (e 1) + (e (e 2) * (e 3))))
visitorresult = 7
如果我们使用Java内建的返回值机制来传递信息,我们的访问器工作得非常好。如果我们希望不去手动访问子节点的话,我们可以选择监听器机制。不幸的是,这也同时意味着我们不能使用Java方法的返回值。
用栈来模拟返回值
ANTLR生成的监听器事件方法是没有返回值的(返回值类型是void)。我们要想在监听器的节点方法上实现访问值的话,我们可以将部分结果存在监听器的一个字段中。这个时候很容易就想到了栈结构,就类似于Java运行时使用CPU栈来临时保存方法的返回值。我们的想法就是,将子表达式的值压入栈中,而子表达式上层的方法从栈顶取结果。下面是完整的Evaluator计算器的监听器代码(位于文件TestLEvaluator.java中):
listeners/TestLEvaluator.java
public static class Evaluatorextends LExprBaseListener {
Stack<Integer>stack = new Stack<Integer>();
public void exitMult(LExprParser.MultContext ctx) {
int right= stack.pop();
int left =stack.pop();
stack.push( left * right );
}
public void exitAdd(LExprParser.AddContext ctx) {
int right= stack.pop();
int left =stack.pop();
stack.push(left + right);
}
public void exitInt(LExprParser.IntContext ctx) {
stack.push( Integer.valueOf(ctx.INT().getText()) );
}
}
要测试这段代码,我们可以在TestLEvaluator测试代码中使用ParseTreeWalker,就像我们在TestPropertyFile中那样做。
➾$ antlr4 LExpr.g4
➾$ javac LExpr*.java TestLEvaluator.java
➾$ java TestLEvaluator
➾1+2*3
➾EOF
<(s (e (e 1) + (e (e 2) * (e 3))))
stackresult = 7
虽然使用栈有点不方便,但是也能很好工作。我们在监听器方法中就必须小心压栈和入栈的操作是否都是正确的。使用访问器可以避免使用栈,但是却需要我们手动访问树的节点。解决这个问题的第三个方法就是捕获并存储部分结果到树节点中。
To be continued...















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









