






输入参数:当前时间步的采样,时间步 t,模型预测量(取决于使用哪一种预测类型)
1、得到上一个去噪时间步
这里的上一个时间步是按照当前时间步的数值减去扩散时间步除以去噪时间步得到的间隔数
而输入的当前时间步是step的输入参数,是通过scheduler的time_spacing指定产生的一个数值从大到小的列表
2、得到、
、
3、计算预测值,
这里有三种计算方式,与训练的模型的结果类型有关:
- 模型直接预测
- 模型直接预测
- 模型预测速度 v
4、对进行clip
5、计算方差
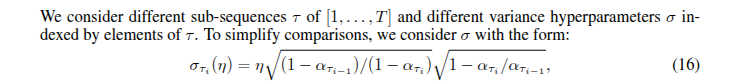
6、计算 "direction pointing to x_t"
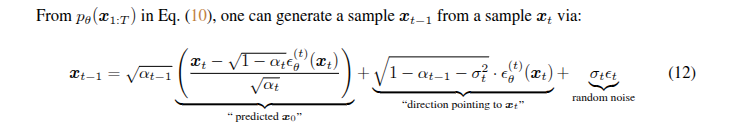
也就是计算上式中的第二项,根号系数没什么可说的,后面乘上的就是与模型有关的 由上面步骤得到
7、计算前两项和
12式第一项括号中的部分在第三步得到,直接乘根号再与第二项相加即可
8、是否引入最后一项random noise
如果eta不为零
该式不为零,即乘上一个噪声加到第7步结果上
step函数计算完毕
在训练时使用v_prediction要用get_v得到监督v值
训练过程中,通过在 0 到最大正向扩散步骤 T 之间进行随机采样加噪,不仅能够使模型学会对各种噪声水平进行准确的预测,还能确保在逆向过程中,无论处于哪一段噪声水平,模型都能有效地还原出干净数据。
正向扩散有闭合形式,直接指定t即可计算扩散后的样本x_t
速度v可视为x0与noise的线性组合,这种重新参数化使得目标函数从单纯去噪转化为了对“变化率”或“方向”的预测,这在一些实践中能够提升模型性能


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









