






摘要
通用型机器人需要具备多功能的身体和智能的大脑。近年来,类人机器人的发展在构建人类世界中的通用自主性硬件平台方面展现出巨大潜力。一个经过大量多样化数据源训练的机器人基础模型,对于使机器人能够推理新情况、稳健处理现实世界的多变性以及快速学习新任务至关重要。为此,我们推出了GR00T N1,这是一个面向类人机器人的开放基础模型。GR00T N1是一个视觉-语言-行动(VLA)模型,采用双系统架构。视觉-语言模块(系统2)通过视觉和语言指令解释环境。随后的扩散变换器模块(系统1)实时生成流畅的运动动作。这两个模块紧密耦合,并且端到端联合训练。我们使用真实机器人轨迹、人类视频以及合成数据集的异构混合来训练GR00T N1。我们展示出,我们的通用型机器人模型GR00T N1在多个机器人实体上的标准仿真基准测试中,优于最先进的模仿学习基线。此外,我们将该模型部署在Fourier GR-1类人机器人上,用于受语言条件约束的双臂操作任务,在数据效率方面取得了强劲表现。
1. 引言
在人类世界中创建能够执行日常任务的自主机器人一直是一个令人着迷的目标,同时也是重要的技术挑战。机器人硬件、人工智能以及加速计算的近期进展共同为开发通用型机器人自主性奠定了基础。为了迈向人类水平的物理智能,我们倡导整合硬件、模型和数据这三大关键要素的全栈解决方案。首先,机器人是具有物理实体的代理,其硬件决定了其能力范围。这使得类人机器人成为构建机器人智能的有吸引力的形式,因为它们具有类似人类的身体和多功能性。其次,现实世界的多样性和多变性要求机器人能够处理开放性目标并执行广泛的任务。实现这一目标需要一个足够表达且能够处理各种任务的通用型机器人模型。第三,获取大规模的现实世界类人机器人数据成本高昂且耗时。我们需要有效的数据策略来训练大规模的机器人模型。
近年来,基础模型在理解和生成视觉和文本数据方面取得了重大突破。它们展示了在大规模网络数据上训练通用型模型的有效性,以实现强大的泛化能力和快速适应下游任务。人工智能邻近领域的基础模型的成功描绘了为通用型机器人构建“智能骨干”的有前景的路线图,赋予它们一系列核心能力,并使它们能够在现实世界中快速学习和适应。然而,与文字和像素的数字领域不同,目前不存在用于大规模预训练的类人机器人数据集。任何单一类人硬件可用的数据量将小得多。机器人学习社区的近期努力(Open X-Embodiment Collaboration等,2024年)探索了跨实体学习,通过汇集来自许多不同机器人的训练数据来扩大数据集。然而,机器人实体、传感器、执行器自由度、控制模式以及其他因素的巨大变异性导致形成了“数据孤岛”,而不是训练真正通用型模型所需的连贯的、互联网规模的数据集。
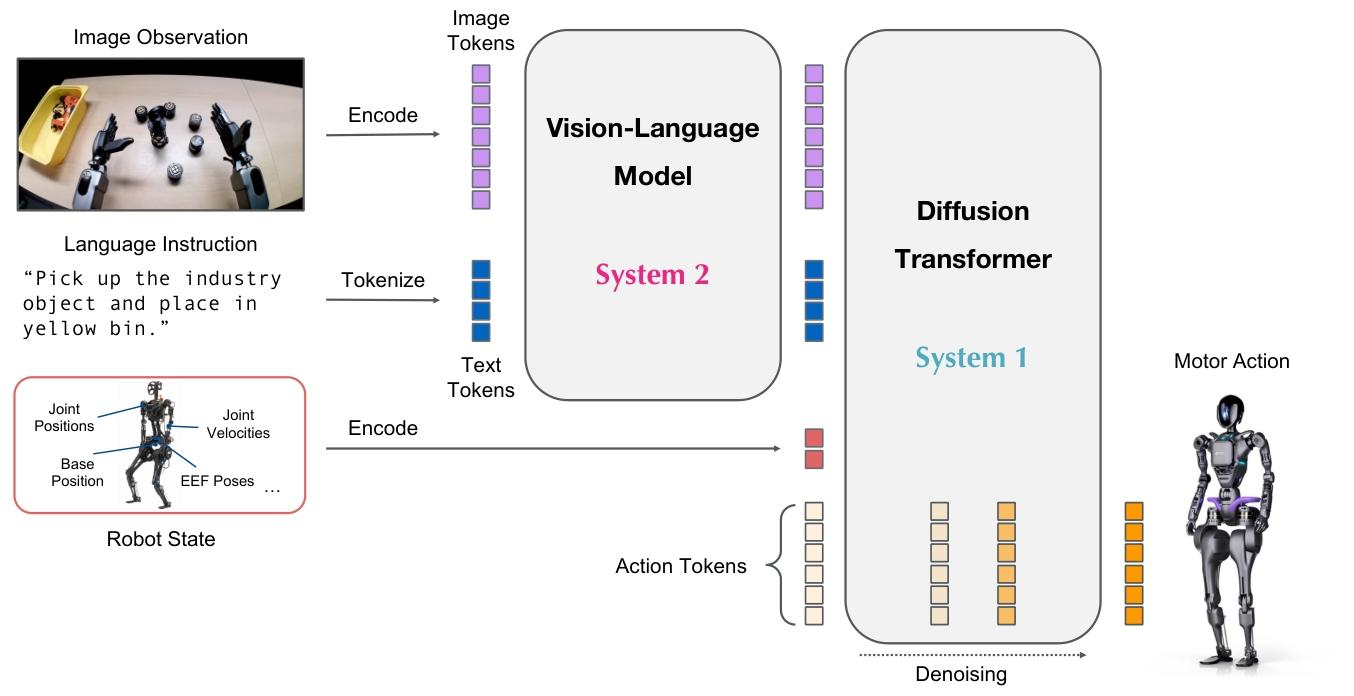
我们介绍了GR00T N1,这是一个面向通用类人机器人的开放基础模型。GR00T N1模型是一个视觉-语言-行动(VLA)模型,它从图像和语言指令输入中生成动作。它支持从桌面机器人手臂到灵巧类人机器人的跨实体功能。它采用双系统组合架构,灵感来自人类认知处理(Kahneman,2011)。系统2推理模块是一个预训练的视觉-语言模型(VLM),在NVIDIA L40 GPU上以10Hz运行。它处理机器人的视觉感知和语言指令,以解释环境并理解任务目标。随后,经过动作流匹配训练的扩散变换器作为系统1动作模块。它交叉关注VLM输出标记,并使用实体特定的编码器和解码器来处理可变的状态和动作维度以生成运动。它以更高的频率(120Hz)生成闭环运动动作。系统1和系统2模块都作为基于Transformer的神经网络实现,并且在训练过程中紧密耦合和联合优化,以促进推理和动作之间的协调。
和人类视频构成了金字塔的底层;通过物理仿真生成的合成数据以及通过现成的神经模型增强的数据构成了中间层;在物理机器人硬件上收集的真实世界数据构成了金字塔的顶层。金字塔的下层提供广泛的视觉和行为先验知识,而上层则确保在实体化的真实机器人执行中落地生根。
Figure 1: Data Pyramid for Robot Foundation Model Training. GR00T N1’s heterogeneous training corpora can be represented as a pyramid: data quantity decreases, and embodiment-specificity increases, moving from the bottom to the top.
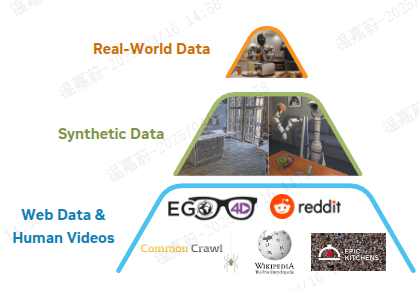
我们开发了一种有效的协同训练策略,以在预训练和后训练阶段跨整个数据金字塔进行学习。为了使用人类视频和神经生成视频等无动作数据源来训练我们的模型,我们学习了一个潜在动作码本 latent-action codebook(Ye等人,2025年),并且还使用经过训练的逆动力学模型(IDM)来推断伪动作 pseudo-actions.。这些技术使我们能够为无动作的视频标注动作,因此我们可以有效地将它们视为模型训练的额外机器人实体。通过统一数据金字塔中的所有数据源,我们构建了一个一致的数据集,其中输入包括机器人状态、视觉观察和语言指令,输出是相应的运动动作。我们在三个数据层(标注过的视频数据集、合成生成的数据集和真实机器人轨迹)中采样训练批次,进行端到端的预训练。
凭借统一的模型和单一的权重集,GR00T N1能够使用单臂、双臂和类人机器人实体生成多样化的操作行为。在标准仿真基准环境中评估时,GR00T N1取得了比最先进的模仿学习基线更优越的结果。我们还在GR-1类人机器人的现实世界实验中展示了GR00T N1的强劲表现。我们的GR00T-N1-2B模型检查点、训练数据和仿真基准在GitHub和HuggingFace数据集上公开可用。
Figure 2: GR00T N1 Model Overview. Our model is a Vision-Language-Action (VLA) model that adopts a dual-system design. We convert the image observation and language instruction into a sequence of tokens to be processed by the Vision-Language Model (VLM) backbone. The VLM outputs, together with robot state and action encodings, are passed to the Diffusion Transformer module to generate motor actions.
2. GR00T N1基础模型
GR00T N1是一个面向类人机器人的视觉-语言-行动(VLA)模型,经过多样化数据源的训练。该模型包含一个视觉-语言骨干网络,用于编码语言和图像输入,以及一个基于DiT的流匹配策略,用于输出高频动作。我们使用NVIDIA Eagle-2 VLM(Li等人,2025年)作为视觉-语言骨干网络。具体来说,我们公开发布的GR00T-N1-2B模型总共有22亿( 2.2B)个参数,其中VLM有13.4亿(1.34B)个参数。在L40 GPU上使用bf16进行采样时,生成16个动作的时间为63.9毫秒。图2提供了我们模型设计的高级概述。我们强调GR00T N1的三个关键特点:
-
我们设计了一个组合模型,将基于视觉-语言模型(VLM)的推理模块(系统2)和基于扩散变换器(DiT)的动作模块(系统1)集成到一个统一的学习框架中;
-
我们开发了一种有效的预训练策略,使用人类视频、仿真和神经生成数据以及真实机器人演示的混合(见图1),以实现泛化和鲁棒性;
-
我们训练了一个大规模多任务、受语言条件约束的策略,支持广泛的机器人实体,并通过数据高效的后训练快速适应新任务。
2.1 模型架构
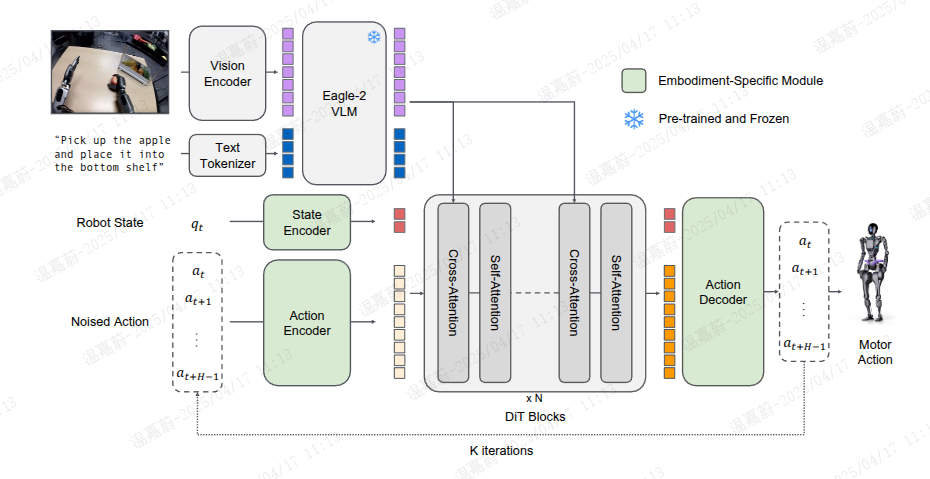
在本节中,我们将描述如图3所示的GR00T N1模型架构。GR00T N1使用流匹配(Lipman等人)来学习动作生成。一个扩散变换器(DiT)处理机器人的本体感知状态和动作,然后与Eagle-2 VLM骨干网络中的图像和文本标记进行交叉关注,以输出去噪后的运动动作。下面,我们将详细阐述每个模块。
状态和动作编码器
为了处理不同机器人实体的状态和动作,这些状态和动作的维度各不相同,我们使用每个实体的一个MLP,将它们投影到一个共享的嵌入维度,作为DiT的输入。正如Black等人(2024年)所述,动作编码器MLP还将扩散时间步与噪声动作向量一起编码。
我们使用动作流匹配,通过迭代去噪来采样动作。模型的输入除了机器人的本体感知状态的编码、图像标记和文本标记外,还包括噪声动作。动作以块的形式进行处理,正如Zhao等人(2023年)所述,这意味着在任何给定时间at,模型使用![]() ,其中包含从时间步 t到t+H−1的动作向量。在我们的实现中,我们设置H=16。
,其中包含从时间步 t到t+H−1的动作向量。在我们的实现中,我们设置H=16。
视觉-语言模块(系统2)
为了编码视觉和语言输入,GR00T N1使用了在互联网规模数据上预训练的Eagle-2(Li等人,2025年)视觉-语言模型(VLM)。Eagle-2是基于SmolLM2(Allal等人,2025年)LLM和SigLIP-2(Tschannen等人,2025年)图像编码器进行微调的。图像在224×224的分辨率下进行编码,然后通过像素洗牌(Shi等人,2016年),每帧得到64个图像标记嵌入。这些嵌入随后与文本一起通过Eagle-2 VLM的LLM组件进行进一步编码。LLM和图像编码器在广泛的视觉-语言任务上进行了对齐,遵循Li等人(2025年)提出的一般方法。
在策略训练期间,任务的文本描述以及(可能的多个)图像以聊天格式传递给VLM,就像在视觉-语言训练期间一样。然后我们从LLM中提取形状为(批量大小×序列长度×隐藏维度)的视觉-语言特征。我们发现,使用LLM中间层而不是最终层的嵌入,既加快了推理速度,又提高了下游策略的成功率。对于GR00T-N1-2B,我们使用第12层的表示。
扩散变换器模块(系统1) 为了建模动作,GR00T N1使用了DiT(Peebles和Xie,2023年Scalable diffusion models with transformers)的一个变体,这是一个具有通过自适应层归一化进行去噪步条件的变换器,记作。如图3所示,
由交替的交叉关注和自关注块组成,类似于Flamingo(Alayrac等人,2022年)和VIMA(Jiang等人,2023年)。自关注块在噪声动作标记嵌入
和状态嵌入
上进行操作,而交叉关注块允许对VLM输出的视觉-语言标记嵌入
进行条件设置。在最后一个DiT块之后,我们应用一个实体特定的动作解码器,另一个MLP,对最终的At标记进行预测,以产生动作。
图 3:GR00T N1 模型架构。GR00T N1 经过多种实例训练,涵盖单臂机械臂到双手人形灵巧手等各种机器人实例。为了处理不同机器人实例的状态观察和动作,我们使用 DiT 模块,并配备可感知实例的状态和动作编码器,以嵌入机器人的状态和动作输入。GR00T N1 模型利用 Eagle-2 模型的潜在嵌入,将机器人的视觉观察和语言指令融合在一起。然后,视觉语言标记将通过交叉注意层输入到 DiT 模块中。
假设真实动作块 𝐴𝑡、流匹配时间步 ![]() 以及采样噪声
以及采样噪声 ![]() ,则带噪动作块
,则带噪动作块 的计算公式为
![]() 。模型预测
。模型预测 ![]() 旨在通过最小化以下损失来近似去噪矢量场
旨在通过最小化以下损失来近似去噪矢量场 ![]() :
:
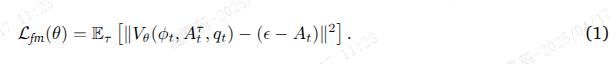
与 Black 等人 (2024 $\pi_0 $: A Vision-Language-Action Flow Model for General Robot Control) 的论文类似,我们使用 ![]() 。在推理过程中,我们采用 𝐾 步去噪生成动作块。首先,随机采样
。在推理过程中,我们采用 𝐾 步去噪生成动作块。首先,随机采样 ![]() ,然后使用前向欧拉积分迭代生成动作块,更新如下:
,然后使用前向欧拉积分迭代生成动作块,更新如下:
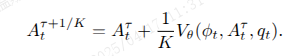
在实践中,我们发现在所有实体中,使用 𝐾 = 4 的推理步骤效果良好。
2.2 训练数据生成
为了训练 GR00T N1,我们使用了多样化数据源和目标来构建数据金字塔(如图 1 所示)。我们首先从开放数据集中获取多样化的人类第一人称视频数据,这些数据构成了基础部分,与用于 VLM 预训练的网络数据一起。接下来,我们使用预训练的视频生成模型生成合成神经轨迹。通过这种方式,我们将数据金字塔的“峰值”——即我们内部收集的 88 小时遥操作轨迹——从 88 小时扩展到 827 小时,增加了约 10 倍。我们使用多样化的反事实机器人轨迹 counterfactual robot trajectories 和新的语言指令来生成这些数据(见图 5 的示例)。我们还额外生成了多样化的仿真轨迹,以扩展数据金字塔的中间部分。
在下一段中,我们首先描述如何从视频中提取潜在动作,我们使用这些潜在动作来为大规模人类第一人称数据集提取标签。接下来,我们描述如何生成神经轨迹和仿真轨迹,以及如何为这些数据源获取动作。
潜在动作
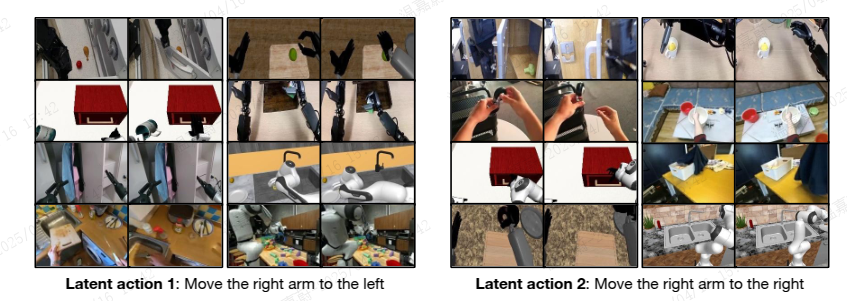
对于人类第一人称视频和神经轨迹,我们没有可以直接用于训练 GR00T N1 的动作数据。对于这些数据,我们通过训练 VQ-VAE 模型从视频的连续图像帧中提取特征来生成潜在动作(Ye 等人,2025 年)。编码器接收视频中固定窗口大小 H 的当前帧 𝑥𝑡 和未来帧 𝑥𝑡+𝐻,并输出潜在动作 𝑧𝑡。解码器被训练为接收潜在动作 𝑧𝑡 和 𝑥t,并重建 𝑥𝑡+𝐻。该模型使用 VQ-VAE 目标进行训练,其中编码器的连续嵌入被映射到码本中最近的嵌入。训练完成后,我们取编码器并将其用作逆动力学模型;给定 𝑥𝑡 和 𝑥𝑡+𝐻 对,我们提取连续的预量化嵌入,并在预训练期间将其用作潜在动作标签,使用相同的流匹配损失,但将其视为一个不同的“LAPA”实体 embodiment。在所有异构数据上一起训练 VQ-VAE 模型,使我们能够统一所有数据以共享相同的已学习潜在动作空间,这可能会改善跨实体泛化能力。图 4 显示了从 8 种不同实体(包括机器人和人类实体)中检索到的 𝑥𝑡 和 𝑥𝑡+𝐻 对,这些实体都来自相似的潜在动作;第一个潜在动作显示所有实体都将右臂向左移动,第二个潜在动作显示将右臂向右移动。
Figure 4: Latent Actions. We retrieve similar latent embeddings across various embodiments. The left images illustrate the latent action that corresponds to moving the right arm (or hand) to the left, while the right images illustrate the latent action that corresponds to moving the right arm (or hand) to the right. Note that this general latent action is not only consistent in different robot embodiments, but also in human embodiment.
神经轨迹 Neural Trajectories
机器人数据的规模与人类劳动呈线性关系,因为通常需要人类操作员通过遥操作机器人来生成每个轨迹。最近,视频生成模型在高质量可控视频生成方面展示了显著潜力(Brooks 等人,2024 年;Lin 等人,2024 年;Ren 等人,2025 年;Wan 团队,2025 年;Xiang 等人,2024 年;Yang 等人,2024 年),这为在机器人领域构建世界模型铺平了道路。为了利用这些模型,我们在我们内部收集的所有 88 小时遥操作数据上对图像到视频生成模型(Agarwal 等人,2025 年;Wan 团队,2025 年;Yang 等人,2024 年)进行微调,并根据现有的初始帧和新的语言提示生成 827 小时的视频数据,增加了约 10 倍。这使得我们能够在不实际收集每个案例的遥操作数据的情况下,生成更多包含现实世界中反事实场景的训练数据(示例见图 5;更多梦想生成示例见图 14)。
Figure 5: Synthetically Generated Videos. We leverage off-the-shelf video generation models to create neural trajectories to increase the quantity and diversity of our training datasets. These generated data can be used for both pre- and post-training of our GR00T N1. (1) The first three rows are generated from the same initial frames but with different prompts (change left or right, the location to place the object), (2) the following two are from the same initial frames but replace the object to pick up, (3) the next row showcases the video model generating a robot trajectory which is very challenging to generate in simulation (spilling contents inside a mesh cup into a bin), and (4) the last row is generated from an initial frame from simulation data. We use thered rectangles to indicate the initial frames.

为了增加神经轨迹的多样性,我们首先使用商业级多模态 LLM 检测初始帧中的对象,并生成更多可能的“拿起 {对象} 从 {位置 A} 到 {位置 B}”的组合,同时指示模型只考虑物理上可行的组合。我们还对生成的视频应用后处理机制,包括过滤和重新标注。为此,我们还使用商业级多模态 LLM 作为评判员,并输入下采样的 8 帧以过滤掉不精确遵循语言指令的神经轨迹。然后我们对过滤掉的视频进行标注。(更多细节可以在附录 E 中找到)。
仿真轨迹
由于同时控制双臂和灵巧手的挑战,为类人机器人扩展真实世界数据收集的规模成本极高。最近的研究(Jiang 等人,2024 年;Mandlekar 等人,2023 年;Wang 等人,2024 年)表明,在仿真中生成训练数据是一种实用的替代方案。我们使用 DexMimicGen(Jiang 等人,2024 年)来合成大规模机器人操作轨迹。
从少量人类演示开始,DexMimicGen 在仿真中应用演示转换和重放,以自动扩展数据集。每个任务被分解为一系列以对象为中心的子任务。初始人类演示被分割成更小的操作序列,每个序列对应一个涉及单个对象的子任务。然后通过将这些片段与对象的位置对齐来将它们适应到新环境中,同时保持机器人末端执行器与对象之间的相对姿态。为了确保平稳执行,系统在机器人当前状态和转换后的片段之间插值运动。然后机器人逐步按照完整序列执行,每一步都验证任务的成功与否。只有成功的演示才会被保留,从而确保数据的高质量。使用 DexMimicGen,我们将有限的人类演示扩展为大规模类人操作数据集。考虑到预训练和后训练数据集,我们总共生成了 78 万个仿真轨迹——相当于 6500 小时,或连续九个月的人类演示数据——仅用了 11 小时。这些仿真数据显著补充了真实机器人数据,且几乎不需要人工成本。
2.3 训练细节
预训练 在预训练阶段,GR00T N1 在多种实体和数据源上通过流匹配损失(公式 1)进行训练,包括各种真实机器人数据集以及人类运动数据。我们参考第 3 节对数据集进行详细描述。
对于人类视频,由于缺乏真实动作,在这种情况下,我们提取了学习到的潜在动作,并将它们用作流匹配目标(见第 2.2 节)。对于机器人数据集,例如我们的 GR-1 类人数据或 Open X-Embodiment 数据,我们使用真实机器人动作以及学习到的潜在动作作为流匹配目标。在神经轨迹(第 2.2 节)用于增强机器人数据集的情况下,我们使用潜在动作以及在真实机器人数据上训练的逆动力学模型预测的动作。预训练超参数列在附录中的表 6 中。
后训练 在后训练阶段,我们在对应于每个单一实体的数据集上对预训练模型进行微调。与预训练一样,我们保持 VLM 的语言部分冻结,并微调模型的其余部分。后训练超参数在附录中的表 6 中给出。
后训练与神经轨迹 为了克服后训练期间数据稀缺的挑战,我们探索通过生成神经轨迹来增强每个下游任务的数据,类似于第 2.2 节中描述的程序。对于基于多视图的下游任务,我们对视频模型进行微调,以在网格中生成多个子图像(见图 13)。对于仿真任务,我们从随机初始化的环境中收集多样化的初始帧。对于真实机器人任务,我们手动随机初始化对象姿态,并记录机器人的初始观察。也可以通过 img2img 扩散自动创建新的初始帧(示例见图 13),但我们把进一步探索留到未来工作。我们还展示了
(1)多轮视频生成用于生成由原子任务组成的长视域轨迹的示例,以及
(2)液体和关节对象的神经轨迹示例,这些对象已知在仿真中非常难以生成,尽管我们把下游任务的定量评估留到未来工作。
图 13:更多神经生成轨迹示例。我们重点介绍神经轨迹的四个关键功能:(1)前三行展示了 RoboCasa 训练后生成的多视角轨迹示例;我们通过在训练期间将视角连接成一个四格视频来实现这一点。(2)接下来的两行展示了两个连续的序列,其中后者的初始帧来自前者的末尾,这突显了生成需要组合原子任务的任务轨迹的可能性。(3)接下来的两行展示了我们的模型能够生成带有关节运动物体和液体的轨迹,而这些在模拟中是非常具有挑战性的。(4)最后一行是从已绘制的初始帧生成的,这表明我们可以生成更加多样化的视频,而无需在现实世界中收集新的初始帧,也无需受人工劳动的约束。我们使用红色矩形表示初始帧。

对于我们的后训练流程与神经轨迹,我们将自己限制在仅对仿真任务的人类收集轨迹对视频生成模型进行微调,以及仅对后训练收集的真实世界基准数据的 10% 的数据进行微调,以匹配我们只有有限数量的遥操作数据的现实场景。由于生成的视频没有动作标签,我们使用潜在动作或逆动力学模型(IDM)标记的动作(Baker 等人,2022 年),并训练策略模型将这些伪动作视为不同实体的动作标签。在低数据场景中,我们也将自己限制在仅对低数据进行 IDM 模型训练,以促进现实场景
训练。在后训练过程中,我们以 1:1 的采样比例共同训练策略模型,使其同时学习真实世界轨迹和神经轨迹。
训练基础设施 我们在由 NVIDIA OSMO(NVIDIA,2025)管理的计算集群上训练 GR00T N1,OSMO 是一个用于扩展复杂机器人工作负载的编排平台。训练集群配备了通过 NVIDIA Quantum-2 InfiniBand 以胖树拓扑结构连接的 H100 NVIDIA GPU。我们通过在 Ray 分布式计算库(Moritz 等人,2018 年)的基础上构建的自定义库,实现了容错的多节点训练和数据摄取。我们为单一模型使用了多达 1024 个 GPU。GR00T-N1-2B 大约使用了 50000 个 H100 GPU 小时进行预训练。
在计算受限的微调环境中,我们在单个 A6000 GPU 上进行了测试。如果只调整适配器层(动作和状态编码器 + 动作解码器) (action and state encoders + action decoder) 和 DiT,可以使用高达 200 的批量大小。当调整视觉编码器时,可以使用的批量大小为 16。
3. 预训练数据集
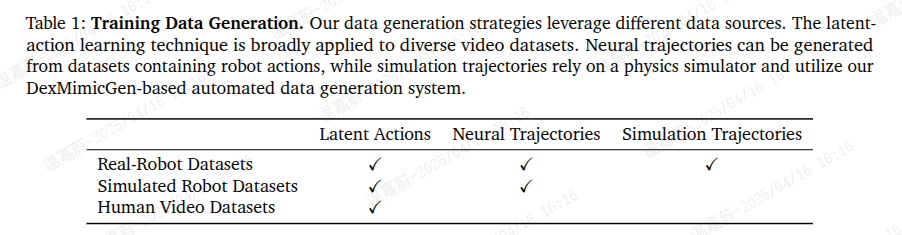
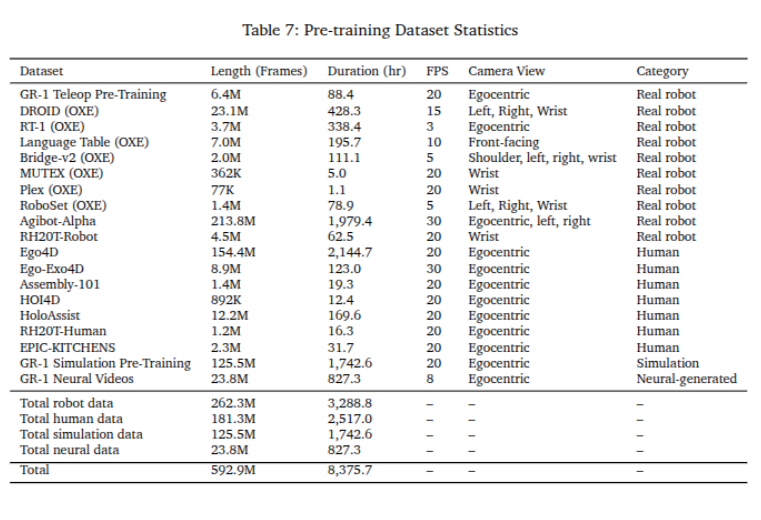
我们将预训练语料库分为三个主要类别:真实机器人数据集(第 3.1 节)、合成数据集(第 3.2 节)和人类视频数据集(第 3.3 节)。这些分别对应于数据金字塔(图 1)的顶端、中间和底部。合成数据集包括仿真轨迹和神经轨迹。表 1 总结了我们在第 2.2 节中描述的训练数据生成策略及其适用的数据源。我们在表 7 中提供了预训练数据集的完整统计数据(帧数、小时数和相机视角)。
表 1:训练数据生成。我们的数据生成策略利用了不同类型的数据源。潜在动作学习技术广泛应用于各种视频数据集。可以从包含机器人动作的数据集中生成神经轨迹,而仿真轨迹则依赖于物理仿真器,并利用我们基于 DexMimicGen 的自动化数据生成系统。
3.1 真实世界数据集
我们使用了以下真实世界机器人数据集:
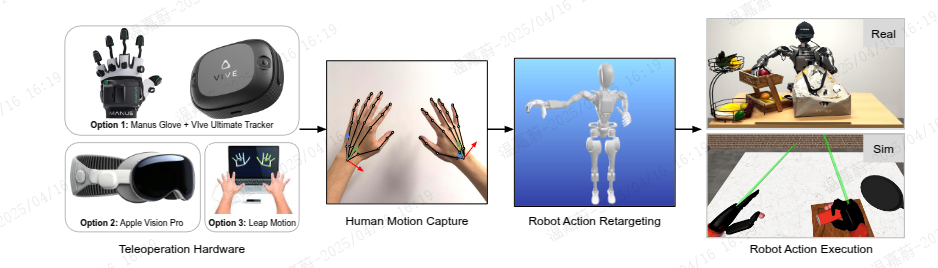
Figure 6: Data Collection via Teleoperation. Our teleoperation infrastructure supports multiple devices to capture human hand motion, including 6-DoF wrist poses and hand skeletons. Robot actions are produced through retargeting and executed on robots in real and simulation environments.
-
GR00T N1 类人预训练数据集 我们内部收集的数据集涵盖了广泛的通用操作任务,专注于通过遥操作控制 Fourier GR1。我们利用 VIVE Ultimate Tracker 捕获遥操作员的手腕姿态,同时使用 Xsens Metagloves 跟踪手指运动。我们还探索了其他遥操作硬件选项,包括 Apple Vision Pro 和 Leap Motion(见图 6)。记录的人类运动随后通过逆运动学重新定位到类人动作。实时遥操作的控制频率为 20Hz。除了机器人的动作外,我们还在每一步捕获头戴式摄像机的图像,以及人类的低维本体感知和动作。该数据集包含细粒度注释,详细描述了抓取、移动和放置等原子动作,以及粗粒度注释,将细粒度动作序列聚合成更高级别的任务表示。这种层次结构支持学习精确的运动控制和高级别的任务推理。
-
Open X-Embodiment Open X-Embodiment Collaboration 等人(2024 年)是一个广泛使用的跨实体机器人操作数据集。我们包括了 RT-1(Brohan 等人,2022 年)、Bridge-v2(Walke 等人,2023 年)、Language Table(Lynch 等人,2022 年)、DROID(Khazatsky 等人,2024 年)、MUTEX(Shah 等人,2023 年)、RoboSet(Bharadhwaj 等人,2024 年)和 Plex(Thomas 等人,2023 年),提供涵盖各种操作任务、基于语言的控制和机器人 - 环境交互的多样化数据集。
-
AgiBot-Alpha AgiBot-World-Contributors 等人(2025 年)是一个包含 100 个机器人轨迹的大规模数据集。我们在启动训练运行时使用了当时可用的 140000 个轨迹。该数据集涵盖了精细操作、工具使用和多机器人协作。
3.2 合成数据集
我们的合成数据集包括
1)在物理仿真器中从少量人类演示中自动生成的仿真轨迹,以及
2)从现成的神经生成模型生成的视频中衍生的神经轨迹。
仿真轨迹 除了真实世界数据集外,我们还如第 2.2 节所述,在仿真中生成了大规模合成数据集。我们的仿真任务包括类人机器人在仿真环境中执行各种桌面重新排列任务,并使用大量现实的 3D 资产。我们在 RoboCasa 仿真框架(Nasiriany 等人,2024 年)下构建了这些任务。总体而言,我们的任务遵循“将 A 从 B 重新排列到 C”的行为,其中 A 对应于一个对象,而 B 和 C 分别代表环境中的源和目标位置。源和目标位置是如盘子、篮子、餐垫和架子等容器,机器人必须在不同组合的源和目标容器之间重新排列对象。总体而言,我们的预训练仿真数据集涵盖了 54 种独特的源和目标容器类别组合。我们在桌子上随机放置对象和容器,并且在场景中还加入了干扰对象和容器。这些干扰项要求模型关注任务语言以执行所需的行为。
我们使用 DexMimicGen 生成大规模、高质量的训练数据集。我们的数据集以 GR-1 类人机器人为特色,但我们可以将该系统应用于广泛的机器人。我们首先通过 Leap Motion 设备收集几十个源演示进行遥操作。Leap Motion 设备跟踪 6 自由度手腕姿态和手指姿态,我们将这些值重新定位并通过基于 mink(Zakka,2024 年)的全身逆运动学控制器发送。鉴于人类演示,DexMimicGen 将演示处理成以对象为中心的片段,然后转换和组合这些片段以生成新的演示。使用该系统,我们为预训练任务体制中的每对(源,目标)容器生成 10000 个新演示,总共生成 540k 个演示。
神经轨迹 为了生成神经轨迹,我们在第 2.2 节描述的我们的真实世界 GR00T N1 类人预训练数据集上对开源的图像到视频模型进行微调。我们在包含 3000 个真实世界机器人数据样本的数据集上训练了 100 个周期,每个样本都带有语言注释,以 480P 分辨率记录,包含 81 帧。如图 5 所示,我们的模型可以根据新的语言提示生成高质量的反事实轨迹。此外,该模型在互联网规模的视频数据上进行训练,展示了在处理未见初始帧、新对象和新的运动模式方面的强大泛化能力。这些视频进一步用潜在动作和基于 IDM 的伪动作进行标记,以供模型训练。我们总共生成了大约 827 小时的视频;在 L40 GPU 上生成 1 秒视频需要 2 分钟,大约需要 105k L40 GPU 小时(约 1.5 天),在 3600 个 L40 GPU 上。
3.3 人类视频数据集
我们包含了多样化的人类视频数据集。这些数据集不包含明确的动作标签,但包含了大量的人类 - 对象交互序列,捕捉了可操作性、任务语义和自然运动模式。这些数据集涵盖了广泛的真实世界人类行为,包括在自然环境中执行的抓取、工具使用、烹饪、组装和其他任务导向活动,并提供了手 - 对象交互的第一人称视角(示例见图 11)。我们的人类视频数据集包括以下内容:
-
Ego4D 是一个大规模的第一人称视频数据集,包含了多样化日常活动的记录(Grauman 等人,2022 年);
-
Ego-Exo4D 在第一人称记录的基础上增加了互补的第三人称(外部)视角(Grauman 等人,2024 年);
-
Assembly-101 专注于复杂组装任务,通过提供逐步组装对象的详细视频(Sener 等人,2022 年);
-
EPIC-KITCHENS 包含了烹饪活动的第一人称镜头(Damen 等人,2018 年);
-
HOI4D 捕捉了人类 -对象交互,并提供了逐帧注释,包括分割、手部和对象姿态以及动作(Liu 等人,2022 年);
-
HoloAssist 捕捉了在增强现实环境中进行的协作和辅助任务(Wang 等人,2023 年);
-
RH20T-Human 包含了在多样化真实场景中进行精细操作任务的记录,重点是自然的手 - 对象交互(Fang 等人,2023 年)。
4. 评估
我们在多种仿真和现实世界基准测试中评估了 GR00T N1 模型。仿真实验涵盖了三个不同的基准测试,旨在系统地评估我们模型在不同机器人实体和操作任务中的有效性。在现实世界实验中,我们研究了该模型在 GR-1 类人机器人上进行桌面操作任务的能力。这些实验旨在展示 GR00T N1 在从有限数量的人类演示中获取新技能方面的能力。
4.1 仿真基准测试
我们的仿真实验包括来自先前工作(Jiang 等人,2024 年;Nasiriany 等人,2024 年)的两个开源基准测试,以及一个新开发的桌面操作任务套件,旨在紧密模拟我们的现实世界任务设置。我们精心选择这些基准测试,以在不同机器人实体和多样化操作任务中评估我们的模型。我们公开发布的模型检查点以及仿真环境和数据集,确保了我们关键结果的可重复性。图 7 展示了这些三个基准测试中的一些示例任务。
RoboCasa 厨房(24 个任务,RoboCasa) RoboCasa(Nasiriany 等人,2024 年)包含了一系列在仿真厨房环境中的任务。我们专注于 24 个“原子”任务,涉及基础的感观运动技能,例如抓取 - 放置、开门和关门、按按钮、拧水龙头等。对于每个任务,我们使用公开可用的数据集,其中包含 3000 个演示,这些演示均使用 MimicGen(Mandlekar 等人,2023 年)生成,涉及 Franka Emika Panda 机械臂。观察空间包括从左、右和腕部位置的摄像机捕获的三张 RGB 图像。状态表示包括末端执行器和机器人基座的位置与旋转,以及夹爪的状态。动作空间由末端执行器的相对位置和旋转以及夹爪状态定义。我们遵循 Nasiriany 等人(2024 年)概述的相同训练和评估协议。
DexMimicGen 跨实体套件(9 个任务,DexMG) DexMimicGen(Jiang 等人,2024 年)包含了一系列需要精确双臂协调的九个双臂灵巧操作任务。这些任务涵盖了三种双臂机器人实体:(1)双臂 Panda 机械臂配备平行夹爪:任务包括穿线、部件组装和运输。状态 / 动作空间包括双臂末端执行器的位置和旋转以及夹爪状态;(2)双臂 Panda 机械臂配备灵巧手:任务包括清理盒子、清理抽屉和托盘提升。状态 / 动作空间包括双臂和手部的末端执行器位置和旋转;(3)GR-1 类人机器人配备灵巧手:任务包括倒水、咖啡准备和罐头分类。状态 / 动作空间包括双臂和手部的关节位置和旋转,以及腰部和颈部。我们使用 DexMimicGen 数据生成系统为每个任务生成 1000 个演示,并评估模型对新对象配置的泛化能力。
GR-1 桌面任务(24 个任务,GR-1) 该数据集作为现实世界类人数据集的数字对应物,使我们能够进行系统评估,从而为现实机器人的部署提供信息。该基准测试专注于使用 GR-1 类人机器人配备 Fourier 灵巧手进行灵巧手控制。与 DexMG 相比,该基准测试涉及更多样化的对象和不同的放置方式。我们总共模拟了 18 个重新排列任务,其结构与第 3.2 节中概述的预训练任务类似,即从源容器重新排列对象到目标容器。每个任务都涉及独特的容器组合,这些组合在我们的预训练数据中未曾出现过。与预训练任务一样,大多数任务都涉及干扰对象和容器,这些干扰项要求模型关注任务语言。我们还额外增加了六个涉及将对象放入关节对象(例如橱柜、抽屉和微波炉)并关闭它们的任务。观察空间包括从机器人头部的自我中心摄像机捕获的一张 RGB 图像。状态 / 动作空间包括双臂和手部的关节位置和旋转,以及腰部和颈部。我们可选地在数据集中包含基于末端执行器的动作,以控制手臂,因为控制全身逆运动学控制器的原生动作空间是基于末端执行器的。我们使用 DexMimicGen 系统为每个任务生成 1000 个演示。
这些精心设计的基准测试引入了结构化、目标驱动的交互,以测试模型是否能够无缝适应现实世界应用。为了构建高质量的后训练数据集,我们让人类操作员根据任务复杂性收集特定任务的数据,时间从 15 分钟到 3 小时不等。然后我们过滤掉低质量轨迹,以保持数据的完整性。通过纳入多样化任务需求——从精确的单智能体操作到复杂的多智能体协作——我们的基准测试为评估人类操作任务中的泛化能力、适应性和精细控制能力提供了一个严格的测试平台。
4.2 现实世界基准测试
我们引入了一套多样化且精心设计的桌面操作任务,旨在评估和利用人类演示对模型进行后训练。这些任务强调了现实世界灵巧性的关键方面,包括精确的对象操作、空间推理、双臂协调和多智能体协作。我们仔细将基准测试分为四种不同类型,以确保对模型性能进行严格的评估。我们在图 8 中展示了一些现实世界基准测试中的示例任务。
-
对象 - 容器抓取 - 放置(5 个任务,抓取 - 放置) 该类别评估模型抓取对象并将它们放入指定容器的能力,这是机器人操作的基本能力。任务包括在常见家庭容器(如托盘、盘子、切菜板、篮子、餐垫、碗和锅)之间转移对象。这些场景测试了精细运动技能、空间对齐以及对不同对象几何形状的适应性。为了严格评估泛化能力,我们在见过和未见过的对象上评估模型。
-
关节对象操作(3 个任务,关节对象) 这些任务评估模型操作关节存储部件的能力。模型必须抓取一个对象,将其放入诸如木箱、深色橱柜或白色抽屉等存储单元中,然后关闭该部件。这些任务引入了在有限空间内进行受约束运动控制和精确放置的挑战。使用见过和未见过的对象进行泛化测试。
-
工业对象操作(3 个任务,工业) 我们为工业场景设计了这一类别,涉及三个结构化的流程和基于工具的交互:1)机械包装:抓取各种机械部件和工具,并将它们放入指定的黄色垃圾桶中;2)网眼杯倒水:抓取一个装有小工业部件(例如螺丝和螺栓)的网眼杯,并将其内容物倒入塑料垃圾桶中;3)圆柱体交接:抓取一个圆柱形对象,将其从一只手转移到另一只手,并将其放入黄色垃圾桶中。这些任务紧密模拟了现实世界中的工业应用,使其成为评估结构化环境中灵巧性的高度相关基准测试。
-
多智能体协调(2 个任务,协调) 协作任务需要多个智能体之间的同步,强调角色协调和自适应决策制定:1)协调第一部分:抓取一个圆柱体,将其放入网眼杯中,并将其交给另一个机器人;2)协调第二部分:接收机器人将圆柱体放入一个黄色垃圾桶中,然后将网眼杯中的剩余内容物倒入另一个黄色垃圾桶。
4.3 实验设置
我们的评估实验包括在数据受限环境中进行后训练的 GR00T N1 和基线模型(如第 2.3 节所述),并在第 4.1 和 4.2 节中描述的仿真和现实世界基准测试中评估策略成功率。默认情况下,我们使用 1024 的全局批量大小,并训练 60k 步。对于 DexMimicGen 跨实体套件,由于每个实体包含的任务相对较少,且总体训练数据有限,我们为 GR00T-N1-2B 使用了 128 的较小批量大小。
基线
为了展示 GR00T N1 多样化预训练的有效性,我们与两个已确立的基线模型进行比较,即 BC-Transformer(Mandlekar 等人,2021 年)和扩散策略(Diffusion Policy)(Chi 等人,2024 年)。以下是这两种方法的详细描述:
这些精心设计的基准测试引入了结构化、目标驱动的交互,以测试模型是否能够无缝适应现实世界应用。为了构建高质量的后训练数据集,我们让人类操作员根据任务复杂性收集特定任务的数据,时间从 15 分钟到 3 小时不等。然后我们过滤掉低质量轨迹,以保持数据的完整性。通过纳入多样化任务需求——从精确的单智能体操作到复杂的多智能体协作——我们的基准测试为评估人类操作任务中的泛化能力、适应性和精细控制能力提供了一个严格的测试平台。(Mandlekar 等人,2021 年)和扩散策略(Diffusion Policy)(Chi 等人,2024 年)。以下是这两种方法的详细描述:
- BC-Transformer 是 RoboMimic(Mandlekar 等人,2021 年)中的基于 Transformer 的行为克隆策略。它由一个 Transformer 架构组成,用于处理观测序列,以及一个高斯混合模型(GMM)模块,用于建模动作分布。该策略以 10 帧观测作为输入,并预测接下来的 10 个动作。
- 扩散策略(Diffusion Policy)(Chi 等人,2024 年)通过基于扩散的生成过程建模动作分布。它采用 U-Net 架构,逐步从随机样本中去除噪声,以生成基于观测序列的精确机器人动作。它以单帧观测作为输入,并在一次推理过程中产生 16 个动作步骤。
评估协议 Evaluation Protocol
对于仿真基准测试评估,我们报告 100 次试验的平均成功率,并取最后 5 个检查点的最大分数,这些检查点每 500 个训练步骤写入一次,遵循 RoboCasa(Nasiriany 等人,2024 年)的协议。
对于现实世界机器人的评估,我们采用部分评分系统,以捕捉模型在不同执行阶段的行为,确保对性能进行细致的评估。我们报告每个任务 10 次试验的平均成功率,但“机械包装”任务除外;对于该任务,我们在 30 秒的时间限制内报告 5 个机械部件和工具中有多少个被放入垃圾桶的成功率。
由于时间限制,我们仅进行 5 次试验。此外,为了评估模型在数据受限环境中的效率,我们对每个任务采样 10% 的完整数据集,并评估模型是否仍能学习有效行为。
4.4 定量结果
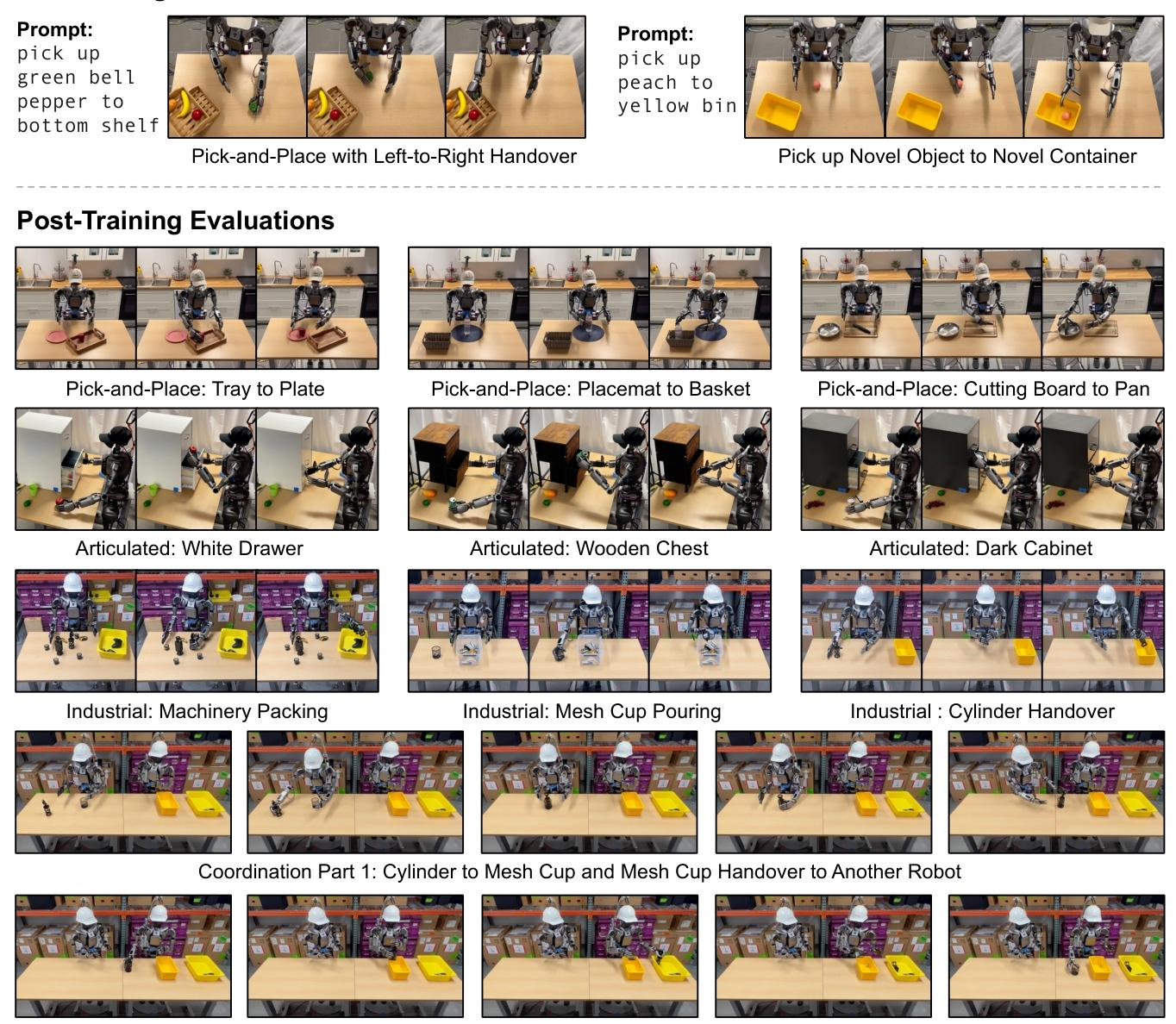
Figure 8: Real-World Tasks. All images are captured from policy rollouts of GR00T-N1-2B and models posttrained from GR00T-N1-2B. (Top) Pre-training evaluations. We design two manipulation tasks to assess
our pretrained models. The left image shows a left-to-right handover, while the right image illustrates the placement of novel objects into an unseen target container. (Bottom) Post-training evaluations. We introduce four distinct task categories. From top to bottom, we present examples of object-to-container pick-and-place, articulated object manipulation, industrial object manipulation, and multi-agent coordination.
预训练评估
为了评估我们预训练检查点的泛化能力,我们在真实的 GR-1 类人机器人上设计了两个任务(见图 8)。在第一个任务中,机器人被指示将一个对象放置在最低层架子上。然而,该对象被故意放置在机器人左臂的左侧,这需要协调的双臂策略。机器人必须首先用左臂抓取对象,将其传递到右臂的范围内,然后完成将其放置到架子上的动作。在第二个任务中,机器人被指示将一个新对象放入一个未见过的目标容器中。对于每个任务,我们使用五个不同的对象对预训练的 GR00T-N1-2B 模型进行评估,每个对象进行三次试验。GR00T-N1-2B 在第一个协调设置中实现了 76.6%(11.5/15)的成功率,在涉及新对象操作的第二个设置中实现了 73.3%(11/15)的成功率。0.5 表示正确抓取了对象,但未能将对象放入容器中。在这两个评估设置下取得的高绩效表明了大规模预训练的有效性。
后训练评估
在仿真环境中,我们将我们后训练的 GR00T N1 模型的定量结果与从头开始的基线模型在三个仿真基准测试中进行了比较(见表 2)。对于每个基准测试,我们使用每个任务 30、100 和 300 个演示进行后训练(RoboCasa 有 24 个任务,DexMG 有 9 个任务,GR-1 有 24 个任务)。我们观察到 GR00T N1 在所有基准测试任务和数据集大小中始终优于基线模型。在附录 B 中,我们包含了完整的比较结果和条形图(图 10)。
在现实机器人上,我们将 GR00T-N1-2B 与扩散策略进行了比较,分别在 10% 的人类遥操作数据集和完整数据集上进行训练(见表 3 和图 9)。
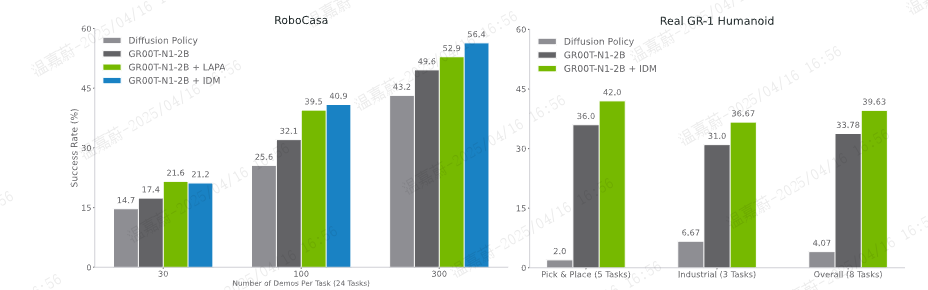
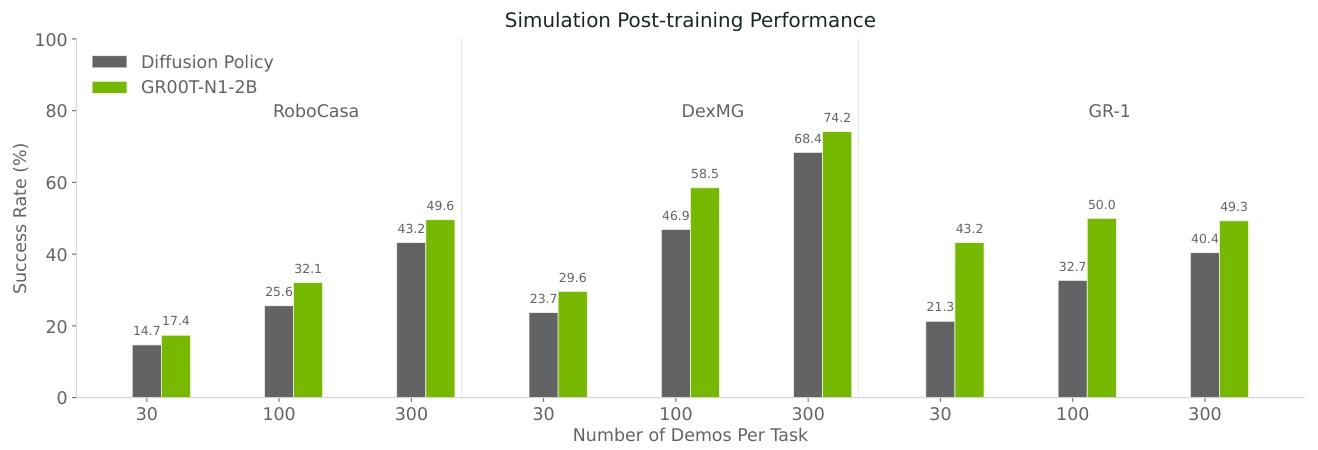
Figure 9: Neural Trajectories Ablations. In the RoboCasa simulation, we show using neural trajectories for post-training across 3 data regimes (30, 100, and 300 per task). In the real world, we show results only on the low-data regime (10% of the demonstrations). We co-train with 3k neural trajectories per task for RoboCasa and 100 neural trajectories per task for real-world tasks. We explore using both latent and IDM-labeled actions in simulation and only IDM-labeled actions for the real robot.
图9:神经轨迹消融实验。在RoboCasa模拟实验中,我们展示了在三种数据规模(每个任务分别有30、100和300个数据)下将神经轨迹用于后训练的情况。在真实世界中,我们仅展示了在低数据规模(演示数据的10%)下的实验结果。对于RoboCasa实验,我们每个任务使用3000条神经轨迹进行共同训练,对于真实世界的任务,每个任务使用100条神经轨迹进行共同训练。我们在模拟实验中探索使用基于潜在空间的动作和标注为IDM的动作,而对于真实机器人则仅使用标注为IDM的动作。
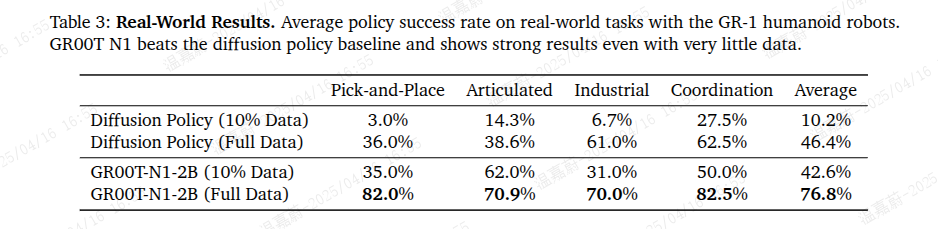
GR00T-N1-2B 在所有任务中均实现了显著更高的成功率,比扩散策略在 10% 数据设置中高出 32.4%,在完整数据设置中高出 30.4%。值得注意的是,仅在 10% 数据上训练的 GR00T-N1-2B 的表现仅比在完整数据上训练的扩散策略低 3.8%,这突显了其数据效率。
Post-training w/ Neural Trajectories Evaluations
我们在图9中展示了一些初步结果,这些结果是关于在后训练阶段使用神经轨迹,在模拟评估的RoboCasa基准测试以及在真实世界评估的拾取与放置(已知任务)和工业任务中的应用情况。我们观察到,与仅在真实世界轨迹上进行训练的GR00T N1相比,与神经轨迹共同训练的GR00T N1始终能带来显著的提升:在RoboCasa基准测试中,在30、100和300个数据规模下,平均分别提升4.2%、8.8%和6.8%;在GR-1人形机器人的8个任务中,平均提升5.8%。
在对比RoboCasa基准测试中的LAPA标签和IDM标签时,出现了一个有趣的现象:在数据量相对较少的情况下(30个数据),LAPA的表现略优于IDM,但随着可用数据增多(达到100个和300个数据时),LAPA和IDM之间的性能差距就会拉大。这一趋势是符合直觉的——随着用于IDM训练的数据增多,伪动作标签会越来越接近真实世界的动作,从而产生更强的正向迁移效果。由于对于我们来说,GR-1人形机器人的训练属于相对 “高数据量” 的情况,因此在真实世界中进行神经轨迹的共同训练时,我们仅使用IDM动作。
4.5 定性结果
这种行为在定性上看起来如何?为了回答这个问题,我们考虑 RoboCasa 中的“拧水龙头”任务——在 100 个样本的环境中,DP 基线的成功率为 11.8%,而 GR00T N1 的成功率为 42.2%。DP 基线经常对任务的语义感到困惑。从表 2 可以看出,GR00T N1 在数据受限环境中表现出色。当使用预训练的 GR00T N1 模型提示任务指令“拿起红苹果并将其放入篮子”时,这是我们在后训练基准测试中的一个任务,我们观察到一些有趣的行为模式。在这种情况下,我们故意将苹果放置在类人机器人手的左侧。尽管在预训练期间很少看到类似的任务,并且表现出更生硬的动作,但预训练的检查点使用其左臂抓取苹果,将其传递给右臂,然后将其放入篮子中。我们在图 12 中提供了这种行为的可视化。相比之下,后训练的检查点在这种情况下失败了。由于所有后训练数据仅涉及右臂,而没有双手之间的传递,因此后训练的策略失去了执行这种行为的能力。
对于后训练的 GR00T N1,与基线扩散策略相比,其动作通常更流畅,抓取精度显著更高。相比之下,扩散策略基线在初始帧中经常出现运动不灵,频繁出现抓取不准确的情况,导致我们在现实世界基准测试中的成功率较低。我们在图 13 中提供了两个策略展开示例的可视化。
4.6 限制
目前,我们的 GR00T N1 模型主要专注于短视域桌面操作任务。在未来的工作中,我们计划将其能力扩展到处理长视域的行走 - 操作任务,这将需要在类人机器人硬件、模型架构和训练语料库方面取得进展。我们预计,一个更强大的视觉 - 语言骨干网络将增强模型的空间推理能力、语言理解和适应性。我们用于合成数据生成的技术——利用视频生成模型和自动化轨迹合成系统——已经展现出巨大潜力。然而,现有方法在生成多样化和反事实数据时仍面临挑战,同时还需要遵循物理定律,这限制了合成数据集的质量和多样性。我们计划改进我们的合成数据生成技术,以进一步丰富用于模型训练的数据金字塔。此外,我们还计划探索新的模型架构和预训练策略,以提高通用型机器人模型的鲁棒性和泛化能力。
附录
B. Detailed Experiment Results
表4和表5分别详细展示了我们的GR00T-N1-2B模型与扩散策略基线模型在模拟基准测试和真实世界基准测试中各任务的对比情况。我们在不同规模的数据集上训练这两个模型——对于模拟基准测试,数据集分别包含30个、100个和300个演示数据;对于真实世界基准测试,数据集分别为演示数据的10%和全部数据。正如预期的那样,随着数据集规模的增大,两个模型的性能都稳步提升。同时,在所有基准测试和各种数据集规模下,我们的模型始终优于基线模型,这表明我们的模型具有更好的泛化能力和样本效率。
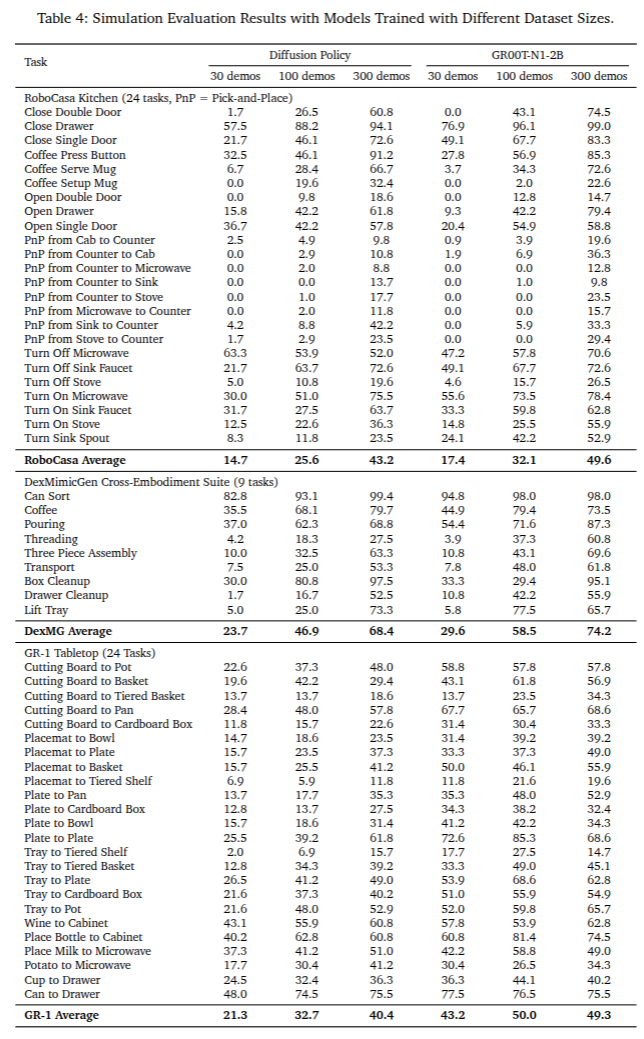
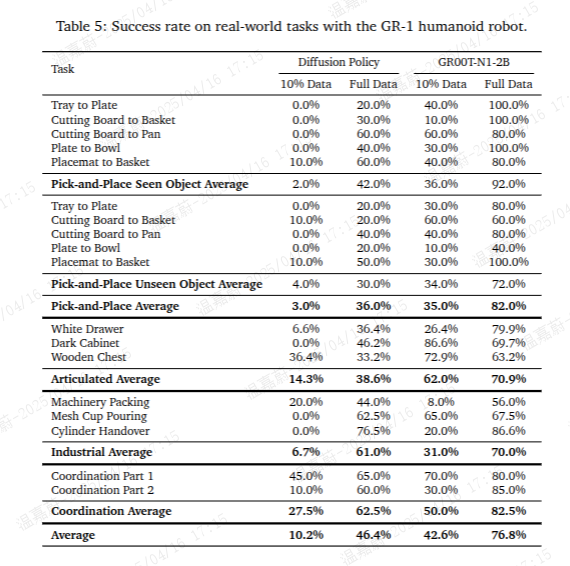
图10:在不同数量演示数据下,模拟操作任务中策略的平均成功率。
C. Additional Qualitative Results
我们在图11和图12中展示了经过预训练和后训练的GR00T-N1-2B模型的定性展示示例。我们的模型在双手操作任务中展现出了强大的语言跟随能力,以及对未见过情况的泛化能力。
图11:预训练定性示例。当用后训练任务指令来驱动预训练的GR00T-N1-2B模型时,我们甚至加大了难度,把苹果放置在两只手的左侧。尽管在训练过程中没有遇到过这种设置,该模型还是成功地通过双手传递将红苹果放进了篮子里,不过动作有些不流畅。
图12:后训练定性示例。(上)经过后训练的GR00T-N1-2B成功地将黄瓜放进了篮子里,而扩散策略模型由于抓取不准确而失败。(下)后训练模型成功地从砧板上拿起柠檬并将其放入锅中,而扩散策略模型则卡在了原处。??


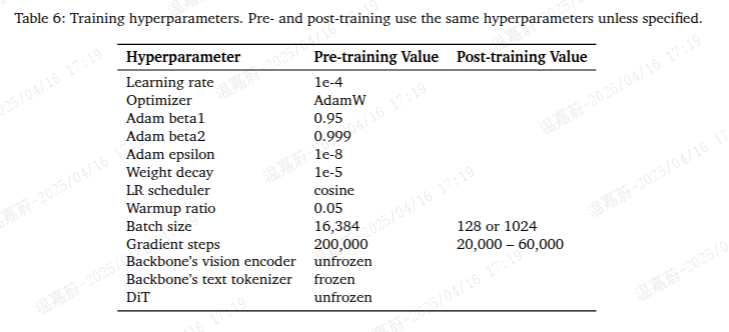
D. Hyperparameters
我们在表6中列出了预训练和后训练阶段所使用的重要超参数。总体而言,这两个阶段的大多数超参数取值是相同的。在后训练阶段,我们使用较小的批量大小,以避免在数据有限的情况下进行微调时出现过拟合问题。
E. System Design
E.1. Dataset Formats
我们的训练语料库是基于LeRobot数据集格式(Cadene等人,2024年)构建的,该格式是开源机器人领域中被广泛采用的标准。LeRobot由Hugging Face开发,旨在通过提供一种用于存储、共享和利用机器人演示数据的标准化格式,降低机器人研究的入门门槛。由于其灵活性,以及可通过Hugging Face中心获取的大量预训练模型和数据集,这种格式已受到广泛关注。
从本质上来说,LeRobot数据集格式采用了多种已有的文件格式相结合的方式,以实现高效的存储和访问:
1. 表格数据:机器人的状态、动作以及元数据都存储在parquet文件(Parquet文件)中,这种文件提供了高效的列式存储方式,并且能实现快速的数据检索。这种格式支持快速的筛选和切片操作,而这些操作对于训练深度学习模型来说至关重要。
2. 图像和视频数据:视觉观测数据被编码为MP4视频文件(或者也可以是PNG图像序列),相关引用信息存储在Parquet文件中。这种方法在保持数据可访问性的同时,大幅降低了存储需求。
3. 元数据:数据集统计信息、片段索引以及其他元数据都存储在结构化的JSON文件中,这些文件提供了关于数据集特征的机器可读信息。
这种格式将演示数据组织成多个片段,每一帧都包含同步的观测数据与动作数据对。每个观测数据通常包括摄像头图像(observation.images.*)和机器人状态信息(observation.state),而动作数据则代表发送给机器人的控制指令。这种数据组织方式既有利于模仿学习(模型通过学习根据观测数据来预测动作),也有利于强化学习(模型学习针对特定结果进行优化)。
虽然LeRobot格式提供了坚实的基础,但我们在处理跨实体数据的工作中,需要额外的结构来支持更丰富的模态信息以及更复杂的训练体系。因此,我们在LeRobot格式的基础上增加了以下限制条件:
1. 模态配置文件:我们要求在元数据目录中存在一个modality.json配置文件,该文件需明确界定状态向量和动作向量的结构,将每个维度映射到一个语义含义,并提供额外的特定于模态的信息。
2. 细粒度的模态规范:与标准的LeRobot格式不同,标准格式将状态和动作视为整体的向量,而我们的扩展将这些向量拆分成具有语义意义的字段(例如,末端执行器的位置、方向、夹爪状态),每个字段都有其自身的元数据,包括数据类型、范围以及变换规范。
3. 多种注释支持:我们对该格式进行了扩展,以便在单个数据集中支持多种注释类型(例如,任务描述、有效性标志、成功指标)。这遵循了LeRobot的惯例,即在Parquet文件中存储索引,而将实际内容存储在单独的JSON文件中。
4. 旋转类型规范:我们的格式明确规定了用于表示旋转数据的方式(例如,四元数、欧拉角、轴角),以便在训练过程中正确处理旋转变换。
我们扩展后的格式在训练视觉语言动作(VLA)模型方面具有几个关键优势:
1. 语义清晰性:通过明确界定状态向量和动作向量中每个维度的结构和含义,我们的格式增强了可解释性,并减少了数据预处理和模型训练过程中的错误。
2. 灵活的变换:细粒度的模态规范使得在训练过程中能够进行复杂的、针对特定字段的归一化和变换操作。例如,旋转数据可以根据其特定的表示方式进行适当的归一化和增强处理。
3. 多模态学习支持:这种扩展格式能够自然地容纳视觉语言动作(VLA)模型所需的各种数据类型,包括视觉观测数据、状态信息、动作指令以及语言注释,同时还能保持这些不同模态数据之间清晰的关联关系。
4. 增强的数据验证:这种明确的结构能够对数据集进行更全面的验证,降低了使用格式错误或不一致的数据进行训练的风险。
5. 增强的互操作性:尽管我们的格式添加了一些限制条件,但它仍与LeRobot生态系统保持向后兼容,这使我们能够利用现有的工具和数据集,同时也支持更复杂的建模方法。
这种扩展格式在标准化和灵活性之间取得了平衡,为常见的机器人数据提供了清晰的结构,同时也满足了视觉语言动作(VLA)模型的特定需求。实践证明,这种方法在我们的工作中颇具价值,它在与更广泛的机器人研究群体保持兼容的同时,实现了更高效的训练,并提升了模型的性能。
E.2. Standardized Action Spaces
Auxiliary Object Detection Loss 辅助目标检测损失
为了增强模型的空间理解能力,我们在训练过程中引入了一个辅助的目标检测损失函数。除了预测动作之外,该模型还必须根据给定的语言指令对感兴趣的目标进行定位。具体来说,对于轨迹片段中的每一帧,我们使用OWL-v2目标检测器(明德勒等人,2023年)标注目标物体的边界框。然后,我们通过将边界框的x坐标和y坐标分别除以图像的宽度和高度,来计算边界框归一化后的中心坐标![]() 。为了预测二维坐标,我们在最终的视觉-语言嵌入标记之上添加一个线性层,并使用均方损失进行优化:
。为了预测二维坐标,我们在最终的视觉-语言嵌入标记之上添加一个线性层,并使用均方损失进行优化:![]() 。因此,最终的损失函数为:
。因此,最终的损失函数为:![]() 。
。
Neural Trajectory Generation
我们使用低秩自适应(LoRA)方法(胡等人,2022年),在收集到的远程操作轨迹数据上对 WAN2.1-I2V-14B 模型(万团队,2025年)进行微调。为了进行微调,这些轨迹数据被统一降采样至 81 帧,分辨率为 480P。由此得到的图像转视频模型会生成神经轨迹,这些轨迹捕捉了现实世界中所有可能的 “反事实场景”。为了确保质量,我们会剔除那些没有准确遵循给定语言指令的生成视频。具体来说,我们从每个视频中采样 8 帧,并促使一个商业级的多模态大语言模型(LLM)来评估该视频是否符合指令。未通过这一标准的视频会进行重新标注字幕,在此过程中,这些视频会被降采样至 16 帧,分辨率为 256P。
IDM Model Training
我们通过以轨迹中的两张图像(当前帧和未来帧)为条件来训练一个逆动力学模型(IDM),并训练该模型以生成这两帧图像之间的动作块。从初步实验中我们观察到,添加状态信息或更多的图像帧并没有显著提高验证集上的动作预测性能。对于逆动力学模型架构,我们使用带有SigLIP-2视觉嵌入的扩散变换器模块(系统1),并以流匹配为目标进行训练。我们针对每个实体训练逆动力学模型30000步或60000步,具体取决于训练集的大小。训练完成后,对于神经轨迹的每一步,我们根据这两张图像(动作时间跨度与训练时相同)对动作进行伪标注。


















 1397
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









