







1、RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
时间:2022/12/13
团队:robotics at google
会议:RSS2
摘要
通过从大型、多样化的任务识别数据集转移知识,现代机器学习模型可以解决特定的下游任务,无论是零样本还是使用小型任务特定数据集,都可以达到高性能水平 。zero-shot or with small task-specific datasets to a high level of performance
虽然这种能力已经在计算机视觉、自然语言处理或语音识别等其他领域得到了证明,但它仍有待于机器人领域的展示,因为难以收集真实世界的机器人数据,因此模型的泛化能力尤其关键 the generalization capabilities of the models are particularly critical。
我们认为,这种通用机器人模型成功的关键之一在于开放式任务无关训练,以及能够吸收所有不同机器人数据的高容量架构。
我们提出了一个模型类,称为Robotics Transformer,它具有很好的可扩展模型特性。
我们在一项研究中验证了我们的结论,研究了不同的模型类别,以及它们作为数据大小、模型大小和数据多样性的函数的泛化能力,该研究基于执行现实世界任务的真实机器人的大规模数据收集。
思路
这种模型(NLP等领域)成功的关键在于开放式的任务不可知训练,结合可以吸收大规模数据集中所有知识的高容量架构。如果一个模型可以“吸收”经验来学习语言或感知的一般模式,那么它就可以更有效地将它们用于单个任务。
The keys to the success of such models lie with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the knowledge present in large-scale datasets. If a model can "sponge up" experience to learn general patterns in language or perception, then it can bring them to bear on individual tasks more efficiently.
旨在训练一种可以用在各类机器人任务上的通用模型:a single, capable, large multi-task backbone model on data consisting of a wide variety of robotic tasks
这样的模型是否享有在其他领域观察到的好处,表现出对新任务、环境和对象的零概率泛化 zero-shot generalization?
当前大型多任务机器人policies存在的问题:
- have limited breadth of real-world tasks
- focus on training tasks rather than generalization to new tasks,as with recent instruction following methods
- attain comparatively lower performance on new tasks
two main challenges:
- assembling the right dataset
- 我们使用了一个数据集,该数据集是我们在17个月的时间里收集的,由13个机器人组成,包含约130k次发作和700多个任务
- 良好的泛化需要结合规模和广度的数据集,涵盖各种任务和设置
- the tasks in the dataset should be sufficiently well-connected to enable generalization
- designing the right model
- transformer模型在高容量方面突出
- 我们设计了RT-1的架构,高维输入camera images, instructions and motor commands转变为transformer所用的compact token representations
- 高效推理实现实时控制
研究结果:
- RT-1可以以97%的成功率执行700多个训练指令,并且可以推广到新任务、干扰源和背景
- RT-1可以结合来自模拟甚至其他机器人类型的数据,保留原始任务的性能并提高对新场景的泛化
We aim to learn robot policies to solve language-conditioned tasks from vision.
方法
硬件:We use mobile manipulators from Everyday Robots, which have a 7 degree-of-freedom arm, a two-fingered gripper, and a mobile base
environments:use three kitchen-based environments,一个训练厨房环境,两个真实厨房环境

训练数据:由人类提供的演示组成并对每个episode用机器人执行指令的文本描述进行标注;指令instruction包含一个动词和多个名词;最大的数据集包含超过130k个单独的演示,包括使用各种各样的对象的700多个不同的任务指令
RT-1:
- 输入:一个简短的图像序列和一个自然语言指令
- 输出:在每个时间步为机器人动作
- 架构
- 图像:an ImageNet pretrained convolutional network conditioned on a pretrained embedding of the instruction via FiLM
- text:Token Learner (Ryoo et al., 2021) to compute a compact set of tokens
- 最后Transformer (Vaswani et al., 2017)来处理这些tokens并生成离散的动作tokens
- action组成
- seven dimensions for the arm movement (x, y, z, roll, pitch, yaw, opening of the gripper)
- three dimensions for base movement (x, y, yaw)
- a discrete dimension to switch between three modes: controlling the arm, the base, or terminating the episode.
RT-1执行闭环控制,并以3hz的频率命令动作
模型结构
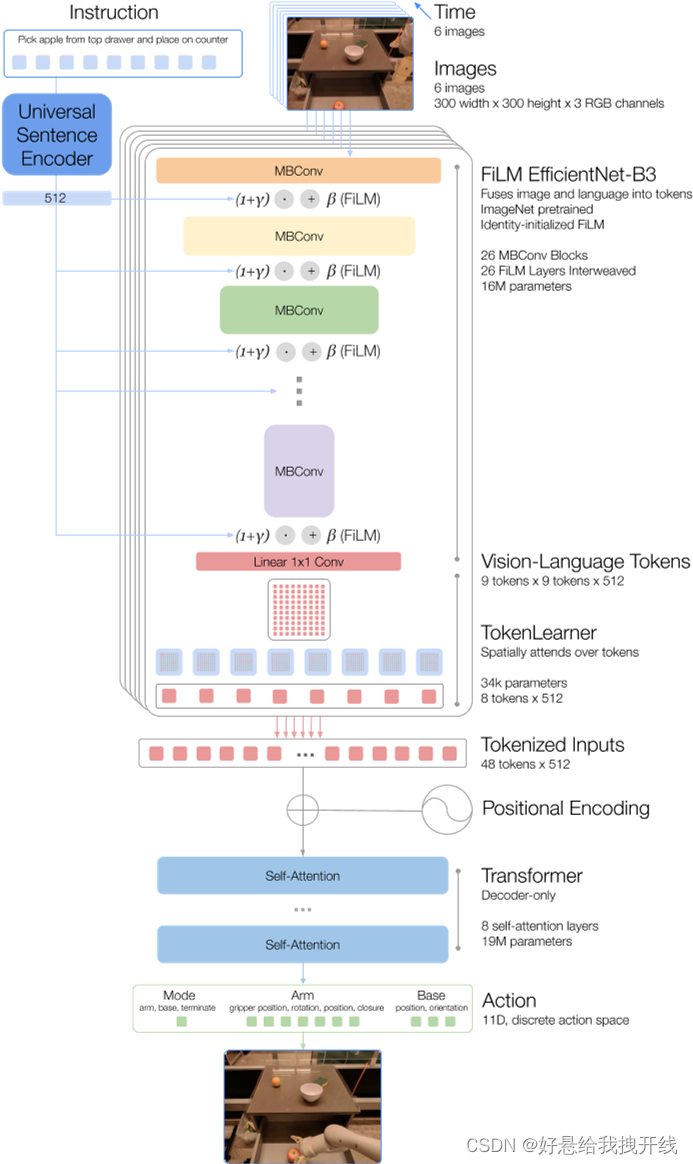
整体结构
图像处理 image tokenization
- a history of 6 images
- an ImageNet pretrained EfficientNet-B3 model
- outputs a spatial feature map of shape 9 × 9 × 512
- flatten the output feature map from the EfficientNet into 81 visual tokens
文本信息
- condition the image tokenizer on the natural lang
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









