







XPath与lxml库介绍及爬虫案例
XPath介绍
XPath(XML Path Language)是一门在XML文档中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。
XPath的节点
XPath的节点有7种类型:文档节点,元素节点,属性节点,文本节点,命名空间节点,处理指令节点,注释节点。对于我们需要关注的是前面4个节点。下面看xml文档。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
<bookstore> # 文档节点
<book> # 元素节点,属于<bookstore>的子节点
<title>/<author>/<year>/<price> # 元素节点,属于<book>节点的子节点
<title lang="en">Harry Potter</title>
lang # 属性节点,是<title>节点的属性
Harry Potter # 文本节点,是<title>节点的文本
XPath选取节点
XPath使用路径表达式在XML文档中选取节点。节点是通过沿着路径或者step来选取的。
路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |

谓语
谓语用来查找某个特定的节点或者包含某个指定的值节点。
谓语被嵌在方括号[]中。
在下面表格中,列出带有谓语的一些路径表达式,以及结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于bookstore子元素的第一个book元素 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素 |
| //title[@lang] | 选取所有拥有名为lang属性的title元素 |
| //title[@lang=’en’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00 |
选取未知节点
XPath通配符可用来选取未知的XML元素
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
选取若干路径
通过在路径表达式中使用”|”运算符,可以选取若干路径。
| 路径表达式 | 描述 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素 |
| //title | // price | 选取文档中的所有 title 和 price 元素 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素 |
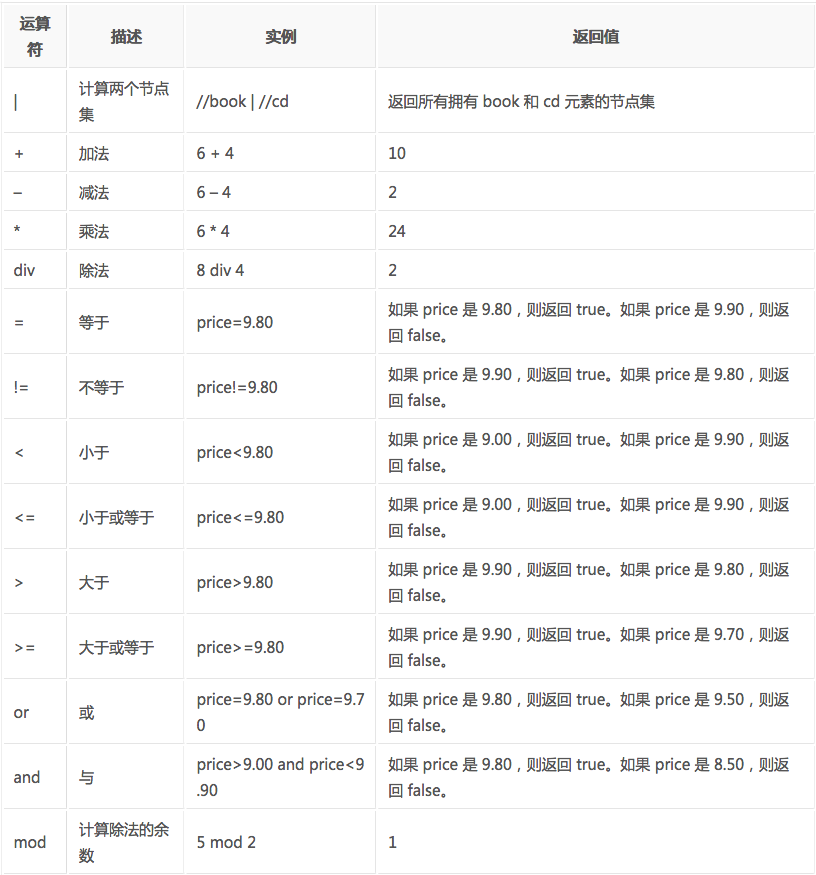
XPath运算符
lxml类库介绍
lxml类库是一个Html/XML的解析器,主要功能是如何解析和提取HTML/XML数据。
lxml的安装
pip install lxmllxml的简单使用
etree将文本转成html:
# 将文本转成html对象
html = etree.HTML(text)
# 将html对象转成html的文本信息
etree.tostring(html)示例:
from lxml import etree
if __name__ == '__main__':
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
# 将文本转成html对象
html = etree.HTML(text)
# 将对象转成html文本
result = etree.tostring(html)
# 打印输出
print(result.decode('utf-8'))输出结果:会自动添加,标签,补齐缺少的标签。
<html>
<body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> </li>
</ul>
</div>
</body>
</html>解析html转成文本
新建一个text.html文件,文件内容:
<html>
<body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body>
</html>解析文本输出:
from lxml import etree
if __name__ == '__main__':
# 解析text.html文件
html = etree.parse('text.html')
# 将html对象转成str
result = etree.tostring(html)
# 输出
print(result.decode('utf-8'))
输出结果:
<html>
<body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body>
</html>XPath与lxml联合使用
获取所有\
- 标签
-
from lxml import etree if __name__ == '__main__': # 解析text.html文件,返回一个html对象 html = etree.parse('text.html') print(type(html)) # 输出html对象类型 <class 'lxml.etree._ElementTree'> # xpath解析语法解析,获取所有的<li>标签的内容 result = html.xpath('//li') print(type(result)) # 输出结果的类型 <class 'list'> for item in result: print(type(item)) # 输出每个item对象的类型 <class 'lxml.etree._Element'> print(etree.tostring(item).decode('utf-8')) # 输出<li>标签的文本内容 如:<li class="item-0"><a href="link1.html">first item</a></li>输出结果:

获取\
- 标签的class=’item-1’属性
-
from lxml import etree if __name__ == '__main__': html = etree.parse('text.html') result = html.xpath('//li[@class="item-1"]') for item in result: print(etree.tostring(item).decode('utf-8'))输出结果:
<li class="item-1"><a href="link2.html">second item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li>获取\
- 标签下的href为link1.html的标签
-
if __name__ == '__main__': html = etree.parse('text.html') result = html.xpath('//li/a[@href="link1.html"]') for item in result: print(etree.tostring(item).decode('utf-8')) # 输出 匹配的信息 <a href="link1.html">first item</a> print(item.text) # 输出标签的<a>文本信息 first item输出结果:
<a href="link1.html">first item</a> first item
XPath爬虫案例
#!/usr/bin/env python # encoding: utf-8 """ __author__: Widsom Zhang __time__: 2017/11/13 18:32 """ import json import random import urllib.request from lxml import etree def download_image(url, headers): """ 下载图片 :param url: 图片的url :param headers: http的请求头 :return: """ # 截取图片的url lists = url.split('/') # 拼接图片保存的地址路径 filename = 'image/' + lists[-1] # 将请求到的数据写入文件 with open(filename, 'wb')as f: f.write(get_response(url, headers)) def write_image_url(url): """ 将图片的url写入文件 :param url: :return: """ # 以拼接的方式写入 with open("image/imageurl.txt", 'a')as f: # 每写入一个换行 f.write(url + "\n") def get_response(url, headers): """ 获取响应对象 :param url: 请求的url :param headers: 请求头信息 :return: 返回服务器的响应信息 """ req = urllib.request.Request(url, headers=headers) resp = urllib.request.urlopen(req) return resp.read() def parse_image(result): """ 解析html信息,获取image的url的策略 :param result: html信息 :return: """ # 通过etree库将html信息转成对象 html = etree.HTML(result) # 通过xpath解析规则,获取需要的图片url信息 images = html.xpath('//li[@class="box"]/a/img/@src') for image in images: print(image) # 下载图片 # download_image(image, headers) # 下载图片太慢,这里注释了 # 将图片的url写入文件 write_image_url(image) if __name__ == '__main__': """ xpath爬虫示例: 爬取的网站是:http://tu.duowan.com/m/bxgif 使用fiddler软件抓包分析: 在浏览器中输入上面的url,加载到30条需要的数据,随着滚动条往下拖动,数据再次加载且浏览器的url没有变化 初步判断采用的是ajax框架加载数据,通过抓包工具找到加载的url。 ajax加载的url: http://tu.duowan.com/m/bxgif?offset=30&order=created&math=0.2097926790117744 url返回的json数据格式: { "html": "...", "more": true, "offset": 60, "enabled": true } http://tu.duowan.com/m/bxgif?offset=60&order=created&math=0.9387482944610999 { "html": "...", "more": true, "offset": 90, "enabled": true } 注:html字段是html中的"<li>..."的html数据,可以使用lxml和xpath解析,具体看代码 通过查看html页面的源码,可以发现,offset是json数据返回的offset,order字段是固定的,math字段是一个(0,1)的随机数。 """ # 需要爬取的url url = 'http://tu.duowan.com/m/bxgif' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36' } # 将请求url的响应信息,通过xpath解析规则解析 parse_image(get_response(url, headers)) # 每次请求30条数据 offset = 30 more = True # 循环遍历30次,获取需要的数据(为什么是30,因为该网站数据不多,也就1000多) while more: # 拼接url url2 = 'http://tu.duowan.com/m/bxgif?offset=' + str(offset) + '&order=created&math=' + str(random.random()) print(url2) result2 = get_response(url2, headers) # 解析json数据 dict = json.loads(result2) # 获取html的value值 result = dict['html'] # offset的值 offset = dict['offset'] print(type(offset)) print(str(offset)) # 获取more的value值 more = dict['more'] # 如果more为true,表示有更多 if more: # 解析image的url parse_image(result)















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









