






无附录 58页 2万字 11页纯图 无文字


城市韧性与可持续发展能力评估
摘要
中国人口老龄化趋势加剧,2022年首次出现了人口负增长,这表明未来中国将长期面临人口减少的趋势。这一趋势必然会对许多城市,特别是二线和三线城市的高质量与可持续发展产生深远影响。同时,全球极端气候事件的频繁发生和当前经济下行压力将对城市发展的韧性提出前所未有的挑战。
针对问题1,首先最重要的是对数据进行正确的缺失值处理,并采用四种模型(线性回归、决策树、随机森林和梯度提升)进行模型预测,然后训练模型并选取效果最好的模型作为最终模型进行区域房价预测,最后可视化并计算住房总量的估算。
针对问题2,我们需要对城市1(长春)和城市2(呼和浩特)的十五个不同部门的服务水平进行定量分析,提取两城市的共性和独特性,并分析它们各自的优缺点。可以看出这是一个统计分析的问题,采用数量统计分析与图像可视化来进行比较。
针对问题3,,目标是评估两座城市在极端天气和突发事件方面的韧性,以及其可持续发展的能力。根据提供的十五个文件(服务指标),我们可以初步
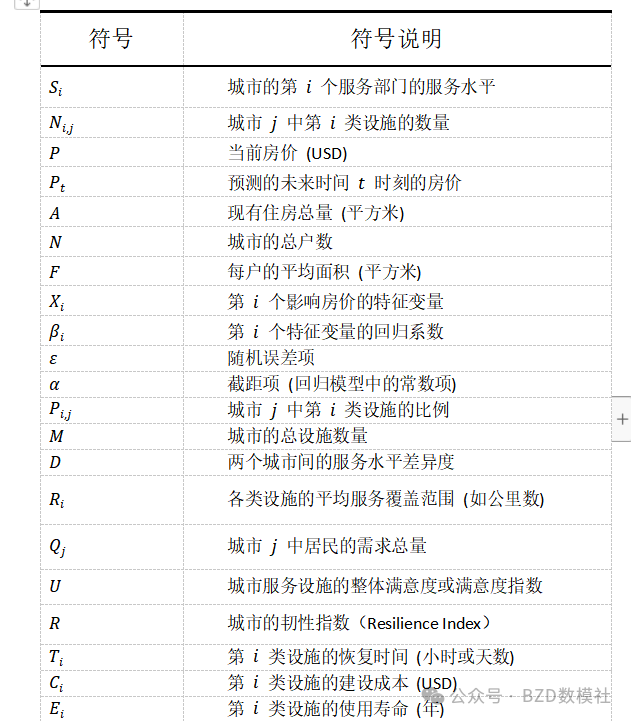
一、符号说明
为了方便我们模型的建立与求解过程 ,我们这里对使用到的关键符号进行以下说明
一、问题求解与分析
4.1 问题1求解与分析
4.1.1 问题1分析
针对问题1,首先最重要的是对数据进行正确的缺失值处理,并采用四种模型(线性回归、决策树、随机森林和梯度提升)进行模型预测,然后训练模型并选取效果最好的模型作为最终模型进行区域房价预测,最后可视化并计算住房总量的估算。
4.1.2 问题1建模与求解
问题1的目标是对城市1和城市2的未来房价进行具体预测,并对现有住房总量进行具体估计。为了实现这一目标,我们采用了多种机器学习回归模型来进行房价预测。具体的步骤包括数据预处理、特征选择、模型构建与训练、模型预测、结果评价和分析。
1、数据预处理
(1)缺失值处理
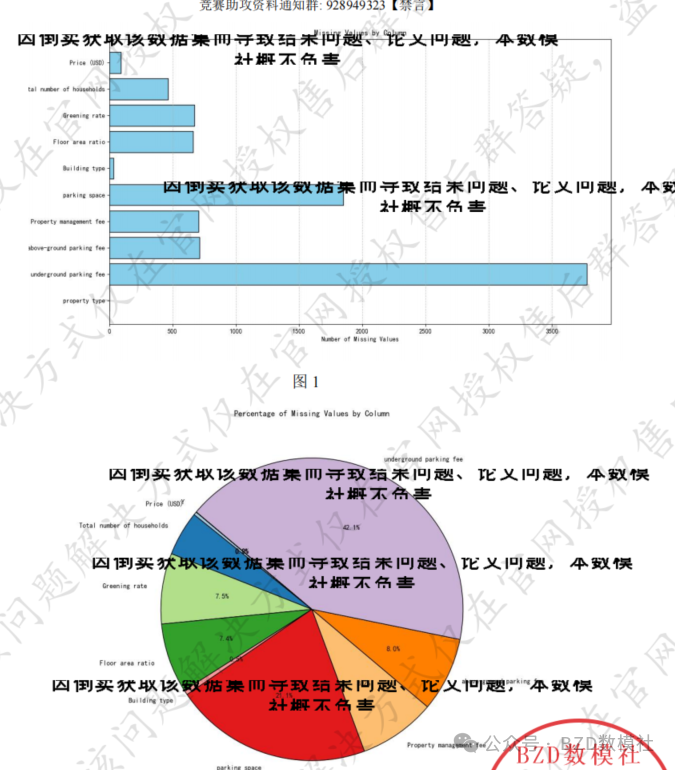
从Appendix 1与Appendix 2给出的某日城市1和城市2在58同城上出售房产的基本信息可以看到有很多N/A值,缺失值可视化的特征变量情况如图1和图2所示。其中,图1的柱形图是城市1变量缺失情况统计,图2的饼图是城市2变量缺失情况统计。假如将城市1的Appendix 1里面的空值全部进行删除的操作,那么原有的4600多条数据就会缩减成900多条,这种缺失值的处理方式是不太合理的。因此本文采用缺失值替换与填补的操作进行处理。
对于数值型变量,采用随机森林来进行预测填补,对于数值型变量,使用众数列进行填补。
| Community Number | 0 |
| Price (USD) | 0 |
| Total number of households | 0 |
| Greening rate | 0 |
| Floor area ratio | 0 |
| Building type | 0 |
| parking space | 0 |
| Property management fee (/m²/month USD) | 0 |
| above-ground parking fee (/month USD) | 0 |
| underground parking fee (/month USD) | 0 |
| property type | 0 |
| citycode | 0 |
| adcode | 0 |
| lon | 0 |
| lat | 0 |
| X | 0 |
| Y | 0 |
可以看到,缺失值已被全部处理。
(2)数据编码与标准化
Label Encoding:对于类别型变量(例如Building type),使用LabelEncoder将其转换为数值。
Min-Max标准化:对特征和目标变量进行标准化,将所有数值缩放到 [0, 1] 的区间。这样可以使得模型在训练时更加稳定,避免特征取值差异过大对结果的影响。
1、模型结果
(1)城市1
各模型预测的房价数值:
表3 模型Linear Regression结果
| Citycode | Adcode | Predicted Average Price (USD) | |
| 0 | 431 | 220104 | 6764.782218 |
| 1 | 431 | 220173 | 7825.148383 |
| 2 | 431 | 220103 | 7395.310954 |
| 3 | 431 | 220106 | 6301.285135 |
| 4 | 431 | 220183 | 5778.481958 |
| 5 | 431 | 220105 | 7177.316057 |
| 6 | 431 | 220171 | 7700.144560 |
| 7 | 431 | 220172 | 9983.853414 |
| 8 | 431 | 220113 | 6273.302201 |
| 9 | 431 | 220174 | 6645.492549 |
| 10 | 431 | 220102 | 7949.806720 |
| 11 | 431 | 220122 | 6249.736509 |
| 12 | 431 | 220112 | 6984.504301 |
| 13 | 431 | 220182 | 5993.360766 |
表4 模型Decision Tree结果
| Citycode | Adcode | Predicted Average Price (USD) | |
| 14 | 431 | 220104 | 8980.339255 |
| 15 | 431 | 220173 | 8566.413527 |
| 16 | 431 | 220103 | 6248.714788 |
| 17 | 431 | 220106 | 6948.823878 |
| 18 | 431 | 220183 | 3696.665550 |
| 19 | 431 | 220105 | 7226.104817 |

问题2求解与分析
4.2.1 问题2分析
根据问题2的描述,我们需要对城市1(长春)和城市2(呼和浩特)的十五个不同部门的服务水平进行定量分析,提取两城市的共性和独特性,并分析它们各自的优缺点。可以看出这是一个统计分析的问题,采用数量统计分析与图像可视化来进行比较。
4.2.2 问题2分析与求解
1、数据预处理与整合
(1)加载数据:读取所有十五个服务数据表,包括住宿服务、商业住宅、医疗与健康、公共设施等。
(2)清洗数据:检查并处理缺失值、重复值等异常数据,统一数据格式和单位。
15个服务水平表11所示。
表11 服务水平
| Accommodation service data | 住宿服务数据 |
| Business-residential data | 商住数据 |
| Car data | 汽车数据 |
| Finance and insurance data | 金融保险数据 |
| Food and beverage service data | 餐饮服务数据 |
| Geographical name and address information data | 地理名称及地址信息数据 |
| Government and social organizations data | 政府及社会组织数据 |
| Interior amenities data | 室内设施数据 |
| Lifestyle service data | 生活服务数据 |
| Medical and health data | 医疗健康数据 |
| Motorbike data | 摩托车数据 |
| Public facilities data | 公共设施数据 |
| Retail service data | 零售服务数据 |
| Science, education, and culture data | 科教文化数据 |
| Transportation facilities data | 交通设施数据 |
2、指标量化与标准化
(1)定义关键指标:针对每个服务类别,定义量化服务水平的关键指标。住宿服务:酒店和旅馆的数量、高级酒店的比例等。商业住宅:居民区数量、商业区面积等。医疗与健康:医院和诊所的数量、每千人拥有的医生数等。公共设施:公园、图书馆、社区中心数量等。
(2)标准化:将每个服务指标标准化(例如通过 Z-score 或 Min-Max 标准化),确保不同服务指标在同一尺度上进行比较。
3、定量分析法
(1)区域平均值计算:计算每个城市各服务类别在不同区域的平均水平,用于代表该城市在该服务类别中的服务水平。
(2)可视化比较:使用图像展示两城市在各服务类别上的服务水平,以直观显示它们的强项和弱项。
4、共性与独特性分析
找出两城市在各服务类别中的相似之处,例如若两城市的基本公共服务(如医疗、教育)都有一定覆盖率,则可以归纳为共性。将每个服务类别的差异系数绘制成柱状图或条形图,直观展示两城市在各服务类别中的差异程度。
5、优缺点分析
根据得到的比例结果进行定量分析,针对不同服务水平来分析城市1与城市2的优势与劣势。
4.2.3 问题2结果分析
1、住宿服务数据
针对两个城市的住宿服务数据,首先将其进行可视化操作观察不同类型住宿设施的数量分布情况。图5和图7是城市1的22种住宿设施,图6和图8是城市2的19种住宿服务数据统计。由于种类比较多,难以量化,因此采用将小类细分成大类的形式对数据重新进行统计并进行量化分析,来观察城市1和城市2的住宿服务水平。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









