






一句话总结为,自注意力机制可以让模型在处理每个词的时候,动态地关注序列中其他所有词的信息,从而捕捉长距离依赖。
假设要处理一句话:“小明打了篮球,因为他很喜欢运动。”
在这句话中,“他”指的是“小明”。如果模型要理解“他”的意思,就需要知道“他”和“小明”之间是有关系的,虽然它们在句子中相隔了几个词。即需要引出自注意力机制会在处理“他”这个词时,自动计算出它与句子中其他词(比如“小明”)的关系权重,决定该关注哪些词。
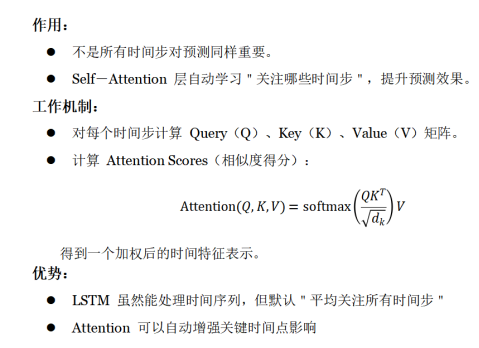
“自注意力机制” (Self-Attention Mechanism)是一种用于神经网络中的机制。核心思想是:在处理一个序列时,模型可以自动学习序列中不同位置之间的关联关系,并且根据这些关系动态调整对不同部分的关注程度。
文末代码为双套代码(python或matlab均可实现),使用LSTM进行时序预测,但是LSTM默认“平均关注所有时间步”是不合理的在很多情况下。引入Self-Attention 层自动学习“关注哪些时间步”。
注释:使用随机数模拟了1000个数据点,18步时间步长,7个维度的数据数组。因此,结果展示中不太理想并不是模型问题,而是选择数据问题。
工作流程(大白话版本)
1、输入嵌入(Embedding)
每个词会被转成一个向量。
2、计算注意力权重
对每对词之间,模型计算它们的“相似度”或“相关性”。
公式上,通常通过“查询(Query)”、“键(Key)”、“值(Value)”向量来计算注意力分数。
3、加权求和
每个词的新表示是它对所有其他词的加权平均(根据注意力权重)。
4、输出
得到一个融合了全局信息的新序列表示。
自 Transformer (Vaswani et al., 2017)开始,各种自注意力机制层出不穷,具体的体现为复杂度越来越低、长依赖捕捉越来越好、逐渐 适用于各种领域。下表为自行收集的近年来不同的“变种”或“优化版本”的自注意力机制
| 名称 | 概述 | 适用范围 | 代表(发布年份) |
| 标准自注意力 (Vanilla Self-Attention / Full Attention) | 每个 token 对所有 token 做 attention,使用 Scaled Dot-Product 公式,复杂度 O(N²) | NLP、CV | Transformer (Vaswani et al., 2017) |
| 多头自注意力 (Multi-Head Self-Attention) | 多头并行学习不同注意力模式,增强表达能力 | NLP、CV、语音 | Transformer, BERT (Devlin et al., 2018), GPT (2018-2020) |
| 稀疏注意力 (Sparse Attention) | 只计算一部分注意力,减少计算复杂度 | 长序列 NLP、DNA分析 | Sparse Transformer (2019), Longformer (2020), Big Bird (2020) |
| 线性注意力 (Linear Attention) | 把复杂度降到 O(N),适合超长序列 | 超长序列 NLP、日志分析 | Performer (2020), Linformer (2020) |
| 卷积式注意力 (Convolutional Attention) | 部分 attention 用卷积代替,提升速度 | 语音、实时系统 | Synthesizer (2020), Conformer (2020) |
| 记忆增强注意力 (Memory-Augmented Attention) | 引入外部记忆,增强长期依赖建模 | 超长文本、视频理解 | Transformer-XL (2019), Compressive Transformer (2020) |
| 图注意力 (Graph Attention, GAT) | 在图结构上使用注意力机制 | 图神经网络 (GNN)、社交网络 | GAT (Velickovic et al., 2018) |
| 视觉自注意力 (Vision Self-Attention) | 把图像划分成 patch,做自注意力建模 | 图像识别、检测 | Vision Transformer (ViT, 2020), Swin Transformer (2021) |
| 交叉注意力 (Cross Attention) | 一个序列对另一个序列做 attention,跨模态 | Encoder-Decoder、跨模态 | Transformer Encoder-Decoder (2017), Diffusion Models (2021-2022) |
实际操作
LSTM → Self-Attention → Dense

%% 1️⃣ 生成随机时间序列输入特征
clc; clear;
numSamples = 1000; % 样本数量
timeSteps = 18; % 时间步 n
numFeatures = 7; % 特征数
% 模拟输入特征 [numSamples x timeSteps x numFeatures]
X = rand(numSamples, timeSteps, numFeatures);
% 模拟目标输出(比如SWH)
Y = rand(numSamples,1); % SWH,标量
%% 2️⃣ 构建 LSTM + Self-Attention + Dense 网络
layers = [ ...
sequenceInputLayer(numFeatures)
% LSTM层
lstmLayer(64,'OutputMode','last')
% Self-Attention 层 (用 multiHeadAttentionLayer 或自己实现,简化这里写 fullyConnected)
% 如果有较新版本Matlab可以用 multiHeadAttentionLayer
fullyConnectedLayer(64) % 代替 attention 层,核心思想是聚合
% Dense层
fullyConnectedLayer(32)
reluLayer
fullyConnectedLayer(1) % 输出 SWH (标量)
regressionLayer
];
%% 3️⃣ 配置训练选项
options = trainingOptions('adam', ...
'MaxEpochs',30, ...
'MiniBatchSize', 32, ...
'InitialLearnRate',1e-3, ...
'GradientThreshold',1, ...
'Shuffle','every-epoch', ...
'Plots','training-progress', ...
'Verbose',false);
%% 4️⃣ 转换数据格式 → cell array(sequenceInput需要 cell 格式)
XCell = cell(numSamples,1);
for i = 1:numSamples
XCell{i} = squeeze(X(i,:,:))'; % 转置成 [numFeatures x timeSteps]
end
%% 5️⃣ 训练网络
net = trainNetwork(XCell,Y,layers,options);
%% 6️⃣ 提取 LSTM 中间特征用于 Random Forest 特征重要性评估
% 这里用 activations 函数提取 LSTM 层的输出
featureLayer = 'lstm'; % LSTM 层名字 (你可以改名或用 layerGraph)
% 提取 LSTM 层的输出(取最后一个时间步的状态作为整体特征)
features = zeros(numSamples,64);
for i = 1:numSamples
lstmOut = activations(net,XCell{i},'lstm','OutputAs','channels');
% 取最后时间步
features(i,:) = lstmOut(:,end);
end
%% 7️⃣ 用 Random Forest 评估特征重要性
% 用 LSTM 输出特征预测 SWH,评估特征重要性
numTrees = 100;
RF = TreeBagger(numTrees,features,Y,'Method','regression','OOBPrediction','on','OOBPredictorImportance','on');
% 画特征重要性
figure;
bar(RF.OOBPermutedPredictorDeltaError);
xlabel('LSTM 特征维度');
ylabel('特征重要性');
title('Random Forest 评估特征重要性');
grid on;
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 1️⃣ 数据准备
num_samples = 1000
time_steps = 18
num_features = 7
# 生成随机输入 [num_samples, time_steps, num_features]
X = np.random.rand(num_samples, time_steps, num_features).astype(np.float32)
# 生成随机目标 SWH
Y = np.random.rand(num_samples, 1).astype(np.float32)
# 转成 PyTorch Tensor
X_tensor = torch.tensor(X)
Y_tensor = torch.tensor(Y)
# 2️⃣ 定义 LSTM + Self-Attention + Dense 网络
class LSTM_Attention_Net(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(LSTM_Attention_Net, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True)
# Self-Attention 参数
self.attention = nn.Linear(hidden_dim, 1)
# Dense 层
self.fc1 = nn.Linear(hidden_dim, 32)
self.fc2 = nn.Linear(32, output_dim)
def forward(self, x):
# LSTM
lstm_out, _ = self.lstm(x) # [batch, time_steps, hidden_dim]
# Attention 权重
attn_weights = torch.softmax(self.attention(lstm_out), dim=1) # [batch, time_steps, 1]
# 加权求和
attn_output = torch.sum(attn_weights * lstm_out, dim=1) # [batch, hidden_dim]
# Dense
out = torch.relu(self.fc1(attn_output))
out = self.fc2(out)
return out, attn_weights
# 超参数
input_dim = num_features
hidden_dim = 64
output_dim = 1
# 实例化模型
model = LSTM_Attention_Net(input_dim, hidden_dim, output_dim)
# 损失函数 & 优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 3️⃣ 训练模型
num_epochs = 50
batch_size = 32
loss_list = []
for epoch in range(num_epochs):
permutation = torch.randperm(num_samples)
for i in range(0, num_samples, batch_size):
indices = permutation[i:i + batch_size]
batch_X = X_tensor[indices]
batch_Y = Y_tensor[indices]
optimizer.zero_grad()
outputs, _ = model(batch_X)
loss = criterion(outputs, batch_Y)
loss.backward()
optimizer.step()
loss_list.append(loss.item())
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}")
# 4️⃣ 可视化训练过程
plt.figure(figsize=(8, 5))
sns.lineplot(x=range(num_epochs), y=loss_list)
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.grid(True)
plt.show()
# 5️⃣ 用 LSTM 特征喂给 RF 评估特征重要性
# 提取 LSTM 最后时间步的输出
with torch.no_grad():
lstm_out, _ = model.lstm(X_tensor)
# 取最后时间步
lstm_features = lstm_out[:, -1, :].numpy()
# 用 RF 评估
rf = RandomForestRegressor(n_estimators=100)
rf.fit(lstm_features, Y)
# 画特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x=np.arange(hidden_dim), y=rf.feature_importances_)
plt.title("Random Forest Feature Importance (LSTM features)")
plt.xlabel("LSTM hidden unit")
plt.ylabel("Importance")
plt.grid(True)
plt.show()
# 6️⃣ 可视化 Attention 权重 (对一个 batch 画 heatmap)
with torch.no_grad():
_, attn_weights = model(X_tensor)
attn_weights_np = attn_weights.squeeze(-1).numpy() # [batch, time_steps]
# 取前 10 个样本画 attention heatmap
plt.figure(figsize=(12, 6))
sns.heatmap(attn_weights_np[:10], cmap="viridis", annot=True, cbar=True)
plt.title("Self-Attention Weights (First 10 samples)")
plt.xlabel("Time Steps")
plt.ylabel("Samples")
plt.show()
# 7️⃣ 预测效果可视化
with torch.no_grad():
Y_pred, _ = model(X_tensor)
Y_pred_np = Y_pred.numpy()
Y_true_np = Y
plt.figure(figsize=(6, 6))
sns.scatterplot(x=Y_true_np.squeeze(), y=Y_pred_np.squeeze())
plt.plot([0, 1], [0, 1], 'r--')
plt.title("Predicted vs True SWH")
plt.xlabel("True SWH")
plt.ylabel("Predicted SWH")
plt.grid(True)
plt.show()
# 8️⃣ 打印 R2 和 MSE
mse = mean_squared_error(Y_true_np, Y_pred_np)
r2 = r2_score(Y_true_np, Y_pred_np)
print(f"MSE: {mse:.4f}, R2: {r2:.4f}")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









