







Hadoop版本:1.1.2
集成开发平台:Eclipse SDK 3.5.1
原创作品:http://blog.csdn.net/yming0221/article/details/9024419
倒排索引(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引。
Hadoop代码:
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- public class InversedIndex {
- /**
- * 将输入文件拆分,
- * 将关键字和关键字所在的文件名作为map的key输出,
- * 该组合的频率作为value输出
- * */
- public static class InversedIndexMapper extends Mapper<Object, Text, Text, Text> {
- private Text outKey = new Text();
- private Text outVal = new Text();
- @Override
- public void map (Object key,Text value,Context context) {
- StringTokenizer tokens = new StringTokenizer(value.toString());
- FileSplit split = (FileSplit) context.getInputSplit();
- while(tokens.hasMoreTokens()) {
- String token = tokens.nextToken();
- try {
- outKey.set(token + ":" + split.getPath());
- outVal.set("1");
- context.write(outKey, outVal);
- } catch (IOException e) {
- e.printStackTrace();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
- /**
- * map的输出进入到combiner阶段,此时来自同一个文件的相同关键字进行一次reduce处理,
- * 将输入的key拆分成关键字和文件名,然后关键字作为输出key,
- * 将文件名与词频拼接,作为输出value,
- * 这样就形成了一个关键字,在某一文件中出现的频率的 key--value 对
- * */
- public static class InversedIndexCombiner extends Reducer<Text, Text, Text, Text> {
- private Text outKey = new Text();
- private Text outVal = new Text();
- @Override
- public void reduce(Text key,Iterable<Text> values,Context context) {
- String[] keys = key.toString().split(":");
- int sum = 0;
- for(Text val : values) {
- sum += Integer.parseInt(val.toString());
- }
- try {
- outKey.set(keys[0]);
- int index = keys[keys.length-1].lastIndexOf('/');
- outVal.set(keys[keys.length-1].substring(index+1) + ":" + sum);
- context.write(outKey, outVal);
- } catch (IOException e) {
- e.printStackTrace();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- /**
- * 将combiner后的key value对进行reduce,
- * 由于combiner之后,一个关键字可能对应了多个value,故需要将这些value进行合并输出
- * */
- public static class InversedIndexReducer extends Reducer<Text, Text, Text, Text> {
- @Override
- public void reduce (Text key,Iterable<Text> values,Context context) {
- StringBuffer sb = new StringBuffer();
- for(Text text : values) {
- sb.append(text.toString() + " ,");
- }
- try {
- context.write(key, new Text(sb.toString()));
- } catch (IOException e) {
- e.printStackTrace();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
- Configuration conf = new Configuration();
- Job job = new Job(conf,"index inversed");
- job.setJarByClass(InversedIndex.class);
- job.setMapperClass(InversedIndexMapper.class);
- job.setCombinerClass(InversedIndexCombiner.class);
- job.setReducerClass(InversedIndexReducer.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(Text.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- job.setNumReduceTasks(3);
- FileInputFormat.addInputPath(job, new Path("input"));
- FileOutputFormat.setOutputPath(job, new Path("output"));
- System.exit(job.waitForCompletion(true)?0:1);
- }
- }
原文本文件:
text1.txt
- MapReduce is sample
- MapReduce is powerful is sample
- Hello MapReduce hello world
运行结果文件:
- Hello text3.txt:1 ,
- MapReduce text3.txt:1 ,text1.txt:1 ,text2.txt:1 ,
- hello text3.txt:1 ,
- is text2.txt:2 ,text1.txt:1 ,
- powerful text2.txt:1 ,
- sample text2.txt:1 ,text1.txt:1 ,
- world text3.txt:1 ,
过程分析:
1、Map过程:
首先是使用默认的TextInputFormat类对文本进行处理,得到每行的偏移量和每行的内容<key,value>,然后Map对每行进行单词分割并设置value为1,得到<key1,value1>,这里key1是单词以及该单词所在的这个文件的URI,value1就是1,表示这个单词出现过1次。
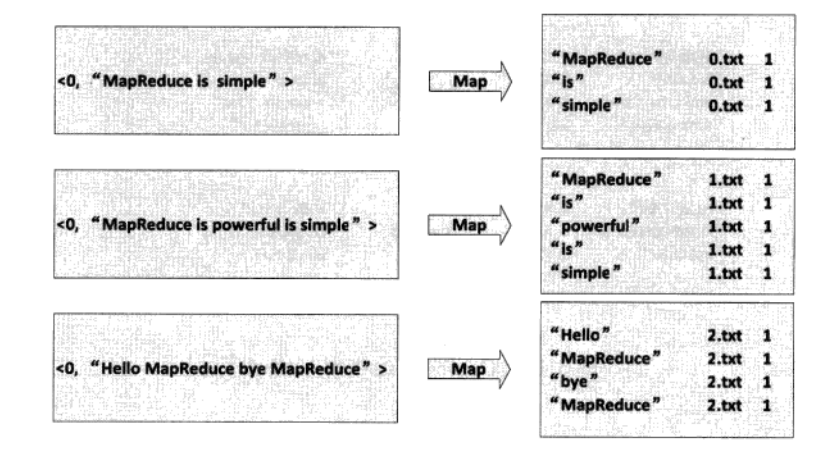
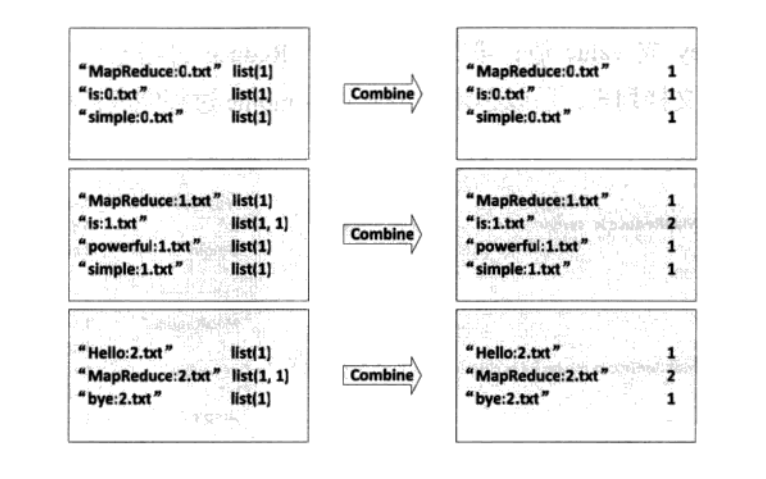
2、Combine过程,完成词频的统计。
该过程对Mapper输出的信息先对每个文档的单词排序<key2,list(value2)>,并对相同的单词计数进行累加,得到<key3,value3>,完成同文档的词频的统计。然后将key和value进行拆分,将单词作为key,将单词所在文档的URI和在本文档中出现的次数作为value,得到<key4,value4>。
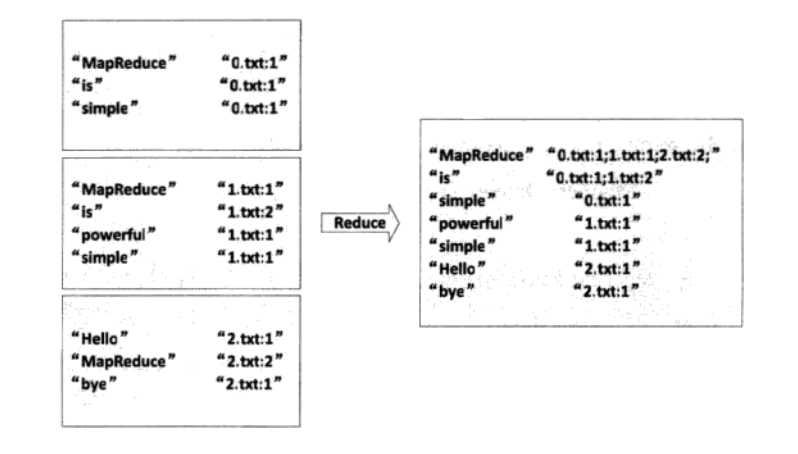
3、Reduce过程,完成对不同文档中的相同的单词以及value值进行输出。















 1996
1996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









