







每天我们都在使用搜索引擎,比如Google,百度,Bing,通常我们搜索一个关键词,搜索引擎瞬间就能给出我们想要的页面。这实际上是一种非常棒的体验。可我们有没有想过为什么搜索引擎能够在数十亿的网页中瞬间找到我们理想的结果呢?一个很重要的原因就是:这些搜索引擎都使用了倒排索引技术(Inverted Index)。
如果没有倒排索引,搜索引擎在每次检索时,必须遍历所有的页面,然后在每个页面中查找是否包含了 我们搜索的关键词。这会导致一个巨大的工作量。
现在我们好奇倒排索引是怎么一回事?
1. 倒排索引是什么
为了便于说明问题,这里假定整个Web下有三个文档,每个文档包含一些单词。三个文档的内容如下 :
file1 : How are you
file2 : How do you do
file3 : What are you doing
下图是文档和单词之间的包含关系图,如下所示:
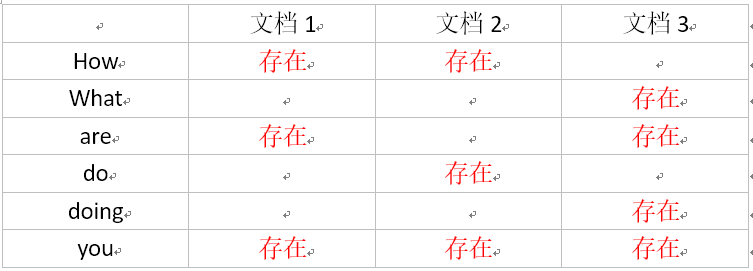
图中的“存在”表示了文档对单词的包含关系。对于这个图,可以从两个角度去分析:
- 从文档的角度来看,每列表示文档包含了哪些单词,不包含哪些单词。
- 从单词的角度来看,每行表示一个单词被哪些文档所包含,和不被哪些文档所包含。
而搜索引擎实现的就是单词–>文档的这种查找方式。要实现这种查找方式,可以有不同方式实现,比如“倒排索引”、“后缀树”等,这里主要介绍倒排索引的具体内容。
1.1 与倒排索引相关的一些概念
- 文档:一般搜索引擎的处理对象是互联网的网页,而文档的概念更加宽泛,代表以文本形似存在的存储对象。
- 文档集合:所有的文档构成的集合。例如所有Web网页就是一个文档集合 。
- 文档编号:在搜索引擎内部,会对每一个文档赋予一个唯一的内部编号,作为文档标识。
- 单词编号:与文档类似,对每一个单词赋予一个唯一的内部编号,作为单词的标识。
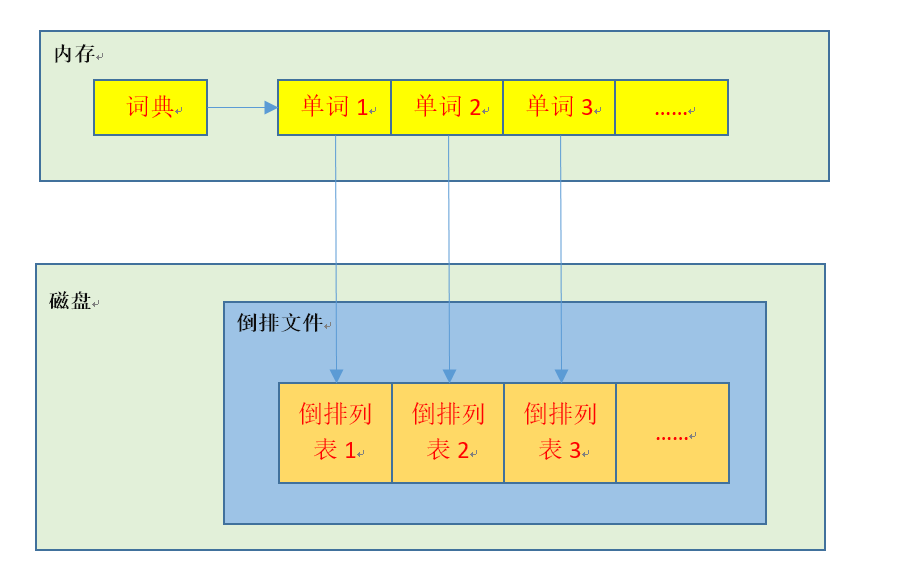
- 倒排索引:它是实现单词–>文档的具体存储形式,通过倒排索引,可以根据单词快速找到包含该单词的文档列表。倒排索引主要包含两部分:
- 1 单词字典:搜索引擎通过单词进行搜索,单词字典是文档集合中出现的所有单词构成的集合。单词字典内每条索引项记载着单词自身的一些信息和该单词所指向的倒排索引的列表。
- 2 倒排列表:它是指包含一个单词的所有文档的文档列表。
- 倒排文档:所有单词的倒排列表往往顺序的存储在磁盘的某个文档里,该文档称为倒排文档。
以上这些与倒排索引相关的概念,他们的联系可以通过下图进行表示:
1.2 倒排索引的处理
下面我们 结合最初的例子和上面介绍的概念,对倒排索引如何处理进行分析。
首先我们对三个文档给出文档编号

我们的目的是要对每个单词建立倒排索引。(这里附加说明一句,英文的单词有明显的分割,而中文的相对比较复杂,需要考虑中文的语义。所以如果对中文进行倒排索引,需要先对文档内容进行分词。)
对于英文文档,每一个词都很明确。我们只需要对所有单词赋予一个唯一编号,同时记录下哪些文档包含这些单词。如下图所示。
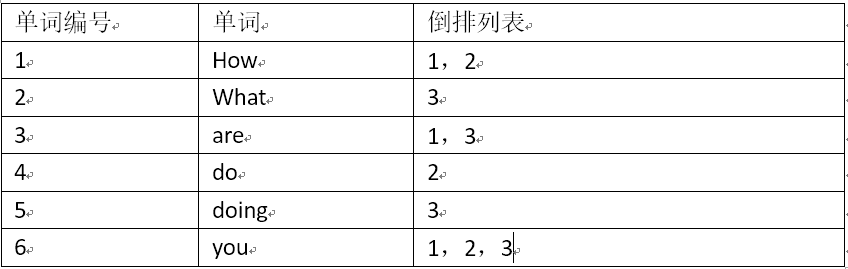
这里第一列为每个单词所对应的唯一编号,第二列为单词,第三列为单词所对应的倒排列表。显然地,这里的倒排列表十分简单,只记载了哪些文档包含了某个单词,没有其他多余的信息。实际上,我们通常还会记录一些其他的东西,比如词频。因为我们可以根据一个文档中某个单词出现次数,来对文档列表的所有文档进行排序。下图是加入词频后的倒排索引。
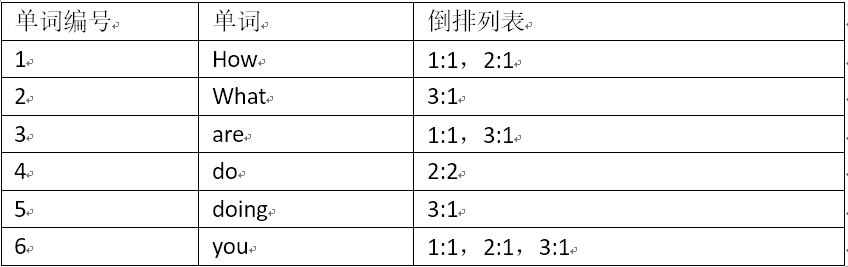
在上图中,倒排列表中”:”前是文档编号,”:”后是单词在该文档下的词频。因为这个示例比较简单,单词在每个单词中的词频为1,而现实情况通常单词在每个文档的词频相差很大,所以词频可以作为文档排序的一个依据。(需要注意的是:如果只使用词频作为排序标准,是有极大弊端的。现代搜索引擎通常使用PageRank 算法进行文档重要程度的估量)
除了词频之外,我们可以联想到还有一类信息可以记载,那就是文档频率信息。也即是说一个单词在多少个文档中出现过。它一般不放在倒排列表中,而是另外存放,只需要能被单词的倒排索引索引到即可。那么加入之后的形似如下图所示。

上面的信息基本是单词的索引系统中必需的信息,还有一类信息对于搜索引擎来说不是 必须具备的,得依据搜索引擎它自身的特性或者说是目的来决定是否添加。这类 信息指的是单词在文档中的位置信息。那么加入位置信息的倒排列表是如下结果:

到现在为止,单词的倒排索引已经基本完备了。通过这个索引系统,当用户输入一个关键词后
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









