







 本文展示如何使用Python和OpenCV的DNN模块进行自然图像下的目标检测、语义分割和风格转换,提供了简洁的代码示例和模型下载链接。
本文展示如何使用Python和OpenCV的DNN模块进行自然图像下的目标检测、语义分割和风格转换,提供了简洁的代码示例和模型下载链接。
前言
-
本文不介绍具体的原理,只展示Python下利用OpenCV的DNN模块进行自然图像下的目标检测,语义分割和风格转换
-
OpenCV下的测试只能是进行推理过程,也就是网络的前向过程,而不能进行网络的训练
-
目前OpenCV支持Caffe,TensorFlow,PyTorch,DarkNet,ONNX等多个框架,一些常用的深度卷积神经网络结构也支持,使用起来简单,非常方便
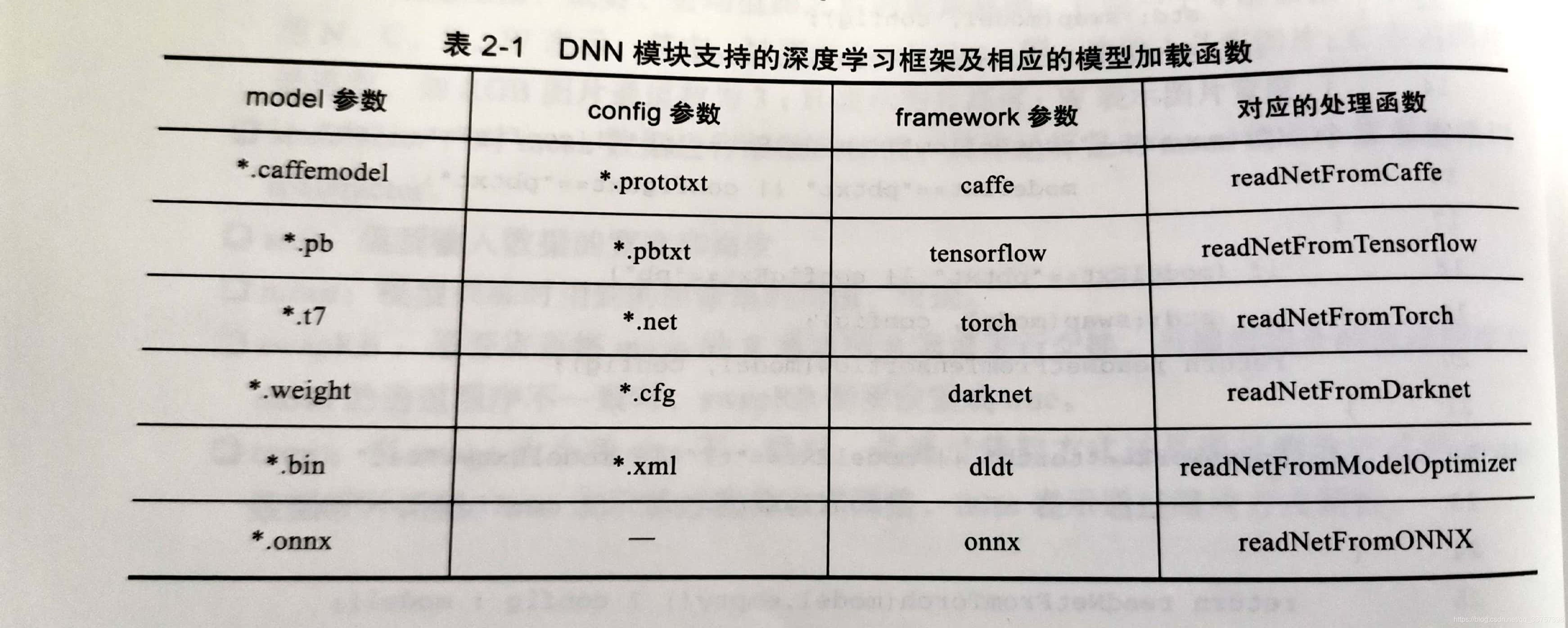
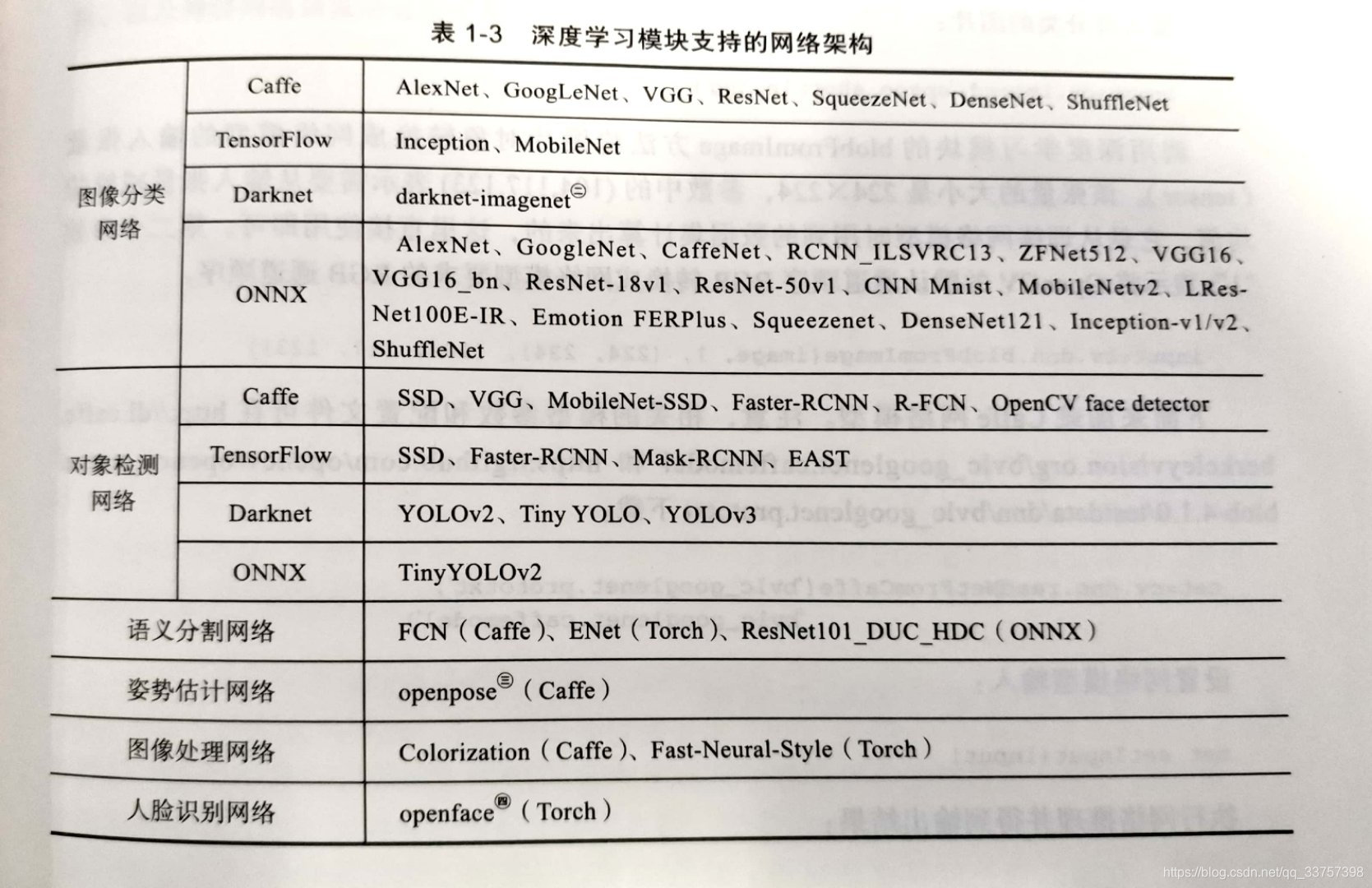
(图片从《OpenCV深度学习应用与性能优化实践》中截取)
-
但需要自己提前准备好训练好的模型,有点麻烦,只能去网上自己寻找人家公开的model,当然,自己训练一个也行~~
-
本文中的三个例子:目标检测,语义分割,风格转换也是参考上书的最后一章的例子,他们的官方代码在:
https://github.com/opencv/opencv/tree/master/samples/dnn
- 解释一下为什么有了官方代码,怎么还会有本篇博客:本篇博客借鉴于官方代码,但与官方代码有着不同。两方面:主要的特点就是简单。本博客在官方代码上删除不重要的代码,只为展示OpenCV下如何简单使用DNN。以目标检测为例,官方代码三百多行,而本博客里面,不会超过两百行,官方代码里面使用了多线程并行处理,导致初学者看起来很头疼,本博客删除那些,只为暴露真正的DNN使用方法,很友好。第二就是能直接运行,官方代码没说明该如何运行,以及去哪里找训练好的模型,本博客支持一键运行并得到结果
目标检测
准备
官方代码:
https://github.com/opencv/opencv/blob/master/samples/dnn/object_detection.py
我们使用的检测模型为MobileNet-SSD,其训练好的模型(模型参数文件)在:
https://drive.google.com/file/d/0B3gersZ2cHIxRm5PMWRoTkdHdHc/view
网络结构文件在:
https://raw.githubusercontent.com/chuanqi305/MobileNet-SSD/daef68a6c2f5fbb8c88404266aa28180646d17e0/MobileNetSSD_deploy.prototxt
模型输入类别文件:
https://github.com/opencv/opencv/blob/master/samples/data/dnn/object_detection_classes_pascal_voc.txt
测试图片在:
https://github.com/chuanqi305/MobileNet-SSD/tree/master/images
代码
import cv2 as cv
import argparse
import numpy as np
import sys
import time
# model:
# https://drive.google.com/file/d/0B3gersZ2cHIxRm5PMWRoTkdHdHc/view
# config:
# https://raw.githubusercontent.com/chuanqi305/MobileNet-SSD/daef68a6c2f5fbb8c88404266aa28180646d17e0/MobileNetSSD_deploy.prototxt
# classes:
# https://github.com/opencv/opencv/blob/master/samples/data/dnn/object_detection_classes_pascal_voc.txt
# images:
# https://github.com/chuanqi305/MobileNet-SSD/tree/master/images
# 支持的后端类型和目标运算设备类型
backends = (cv.dnn.DNN_BACKEND_DEFAULT, cv.dnn.DNN_BACKEND_HALIDE, cv.dnn.DNN_BACKEND_INFERENCE_ENGINE, cv.dnn.DNN_BACKEND_OPENCV)
targets = (cv.dnn.DNN_TARGET_CPU, cv.dnn.DNN_TARGET_OPENCL, cv.dnn.DNN_TARGET_OPENCL_FP16, cv.dnn.DNN_TARGET_MYRIAD)
parser = argparse.ArgumentParser(add_help=False)
parser.add_argument('--input', default='./imgs/004545.jpg')
parser.add_argument('--model', default='MobileNetSSD_deploy.caffemodel')
parser.add_argument('--config', default='MobileNetSSD_deploy.prototxt')
parser.add_argument('--classes', default='object_detection_classes_pascal_voc.txt')
parser.add_argument('--width', type=int, default=300)
parser.add_argument('--height', type=int, default=300)
parser.add_argument('--framework', default='caffe')
parser.add_argument('--mean', default=[127.5, 127.5, 127.5])
parser.add_argument('--rgb', default=False)
parser.add_argument('--colors', default=None)
parser.add_argument('--scale', type=float, default=0.007843)
parser.add_argument('--thr', type=float, default=0.5, help='Confidence threshold')
parser.add_argument('--nms', type=float, default=0.4, help='Non-maximum suppression threshold')
parser.add_argument('--backend', choices=backends, default=cv.dnn.DNN_BACKEND_DEFAULT, type=int,
help="Choose one of computation backends: "
"%d: automatically (by default), "
"%d: Halide language (http://halide-lang.org/), "
"%d: Intel's Deep Learning Inference Engine (https://software.intel.com/openvino-toolkit), "
"%d: OpenCV implementation" % backends)
parser.add_argument('--target', choices=targets, default=cv.dnn.DNN_TARGET_CPU, type=int,
help='Choose one of target computation devices: '
'%d: CPU target (by default), '
'%d: OpenCL, '
'%d: OpenCL fp16 (half-float precision), '
'%d: VPU' % targets)
args = parser.parse_args()
# 加载网络输出的类型,本文包含car,bus,people等20类
classes = None
if args.classes:
with open(args.classes, 'rt') as f:
classes = f.read().rstrip('\n').split('\n')
net = cv.dnn.readNet(cv.samples.findFile(args.model), cv.samples.findFile(args.config), args.framework) #加载模型
net.setPreferableBackend(args.backend) #设置后端类型
net.setPreferableTarget(args.target) #设置目标运算设备的类型
confThreshold = args.thr
nmsThreshold = args.nms
# 目标检测的后处理,包含非极大值抑制(NMS)
def postprocess(frame, outs):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
def drawPred(classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv.rectangle(frame, (left, top), (right, bottom), (0, 255, 0))
label = '%.2f' % conf
# Print a label of class.
if classes:
assert(classId < len(classes))
label = '%s: %s' % (classes[classId], label)
labelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
cv.rectangle(frame, (left, top - labelSize[1]), (left + labelSize[0], top + baseLine), (255, 255, 255), cv.FILLED)
cv.putText(frame, label, (left, top), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
layerNames = net.getLayerNames()
lastLayerId = net.getLayerId(layerNames[-1])
lastLayer = net.getLayer(lastLayerId)
classIds = []
confidences = []
boxes = []
if lastLayer.type == 'DetectionOutput':
# Network produces output blob with a shape 1x1xNx7 where N is a number of
# detections and an every detection is a vector of values
# [batchId, classId, confidence, left, top, right, bottom]
for out in outs:
for detection in out[0, 0]:
confidence = detection[2]
if confidence > confThreshold:
left = int(detection[3])
top = int(detection[4])
right = int(detection[5])
bottom = int(detection[6])
width = right - left + 1
height = bottom - top + 1
if width <= 2 or height <= 2:
left = int(detection[3] * frameWidth)
top = int(detection[4] * frameHeight)
right = int(detection[5] * frameWidth)
bottom = int(detection[6] * frameHeight)
width = right - left + 1
height = bottom - top + 1
classIds.append(int(detection[1]) - 1) # Skip background label
confidences.append(float(confidence))
boxes.append([left, top, width, height])
elif lastLayer.type == 'Region':
# Network produces output blob with a shape NxC where N is a number of
# detected objects and C is a number of classes + 4 where the first 4
# numbers are [center_x, center_y, width, height]
classIds = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = int(center_x - width / 2)
top = int(center_y - height / 2)
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
else:
print('Unknown output layer type: ' + lastLayer.type)
exit()
indices = cv.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold)
for i in indices:
i = i[0]
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
drawPred(classIds[i], confidences[i], left, top, left + width, top + height)
# 加载输入图像
frame = cv.imread(args.input)
# 设置长宽
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
inpWidth = args.width if args.width else frameWidth
inpHeight = args.height if args.height else frameHeight
# 图像格式转换,包含减均值,缩放,resize,通道交换等等操作
# 具体细节可以参考博客:https://blog.csdn.net/baidu_38505667/article/details/100168965
blob = cv.dnn.blobFromImage(frame, args.scale, (inpWidth, inpHeight), args.mean, args.rgb, crop=False)
# 设置网络输入
net.setInput(blob)
# 为Faster-RCNN和R-FCN网络设计的,本文可以不用考虑
if net.getLayer(0).outputNameToIndex('im_info') != -1: # Faster-RCNN or R-FCN
frame = cv.resize(frame, (inpWidth, inpHeight))
net.setInput(np.array([[inpHeight, inpWidth, 1.6]], dtype=np.float32), 'im_info')
# 前向推理
outs = []
outs.append(net.forward())
# 后处理
postprocess(frame, outs)
# 保存图像
pos = args.input.rfind('/')
if pos == -1:
out_path = './detection_' + args.input
else:
out_path = args.input[:pos+1] + 'detection_' + args.input[pos+1:]
cv.imwrite(out_path, frame)
# 显示检测结果
winName = 'Detection'
cv.namedWindow(winName, cv.WINDOW_NORMAL)
def callback(pos):
global confThreshold
confThreshold = pos / 100.0
cv.createTrackbar('Confidence threshold, %', winName, int(confThreshold * 100), 99, callback)
cv.resizeWindow(winName, (800, int(frameHeight/frameWidth * 800)))
cv.imshow(winName, frame)
cv.waitKey(0)
cv.destroyAllWindows()
运行结果:
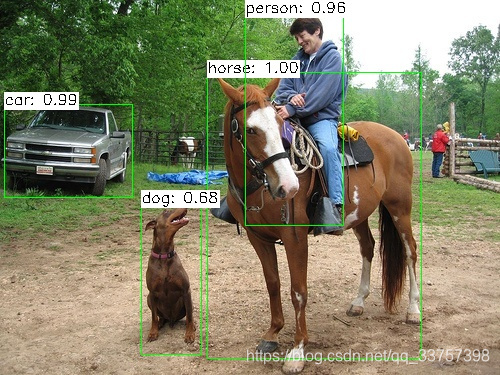
语义分割
准备
官方代码:
https://github.com/opencv/opencv/blob/master/samples/dnn/segmentation.py
我们使用的检测模型为FCN8s,其训练好的模型(模型参数文件)在:
http://dl.caffe.berkeleyvision.org/fcn-8s-pascal.caffemodel
网络结构文件在:
https://github.com/opencv/opencv_extra/blob/master/testdata/dnn/fcn8s-heavy-pascal.prototxt
模型输入类别文件:
https://github.com/opencv/opencv/blob/master/samples/data/dnn/object_detection_classes_pascal_voc.txt
测试图片在:
https://github.com/shelhamer/fcn.berkeleyvision.org/tree/master/demo
代码
import cv2 as cv
import argparse
import numpy as np
import sys
import os
# model:
# http://dl.caffe.berkeleyvision.org/fcn-8s-pascal.caffemodel
# config:
# https://github.com/opencv/opencv_extra/blob/master/testdata/dnn/fcn8s-heavy-pascal.prototxt
# classes:
# https://github.com/opencv/opencv/blob/master/samples/data/dnn/object_detection_classes_pascal_voc.txt
# 注意:在下载的object_detection_classes_pascal_voc.txt的第一行添加background,不然会报错
# images:
# https://github.com/shelhamer/fcn.berkeleyvision.org/tree/master/demo
backends = (cv.dnn.DNN_BACKEND_DEFAULT, cv.dnn.DNN_BACKEND_HALIDE, cv.dnn.DNN_BACKEND_INFERENCE_ENGINE, cv.dnn.DNN_BACKEND_OPENCV)
targets = (cv.dnn.DNN_TARGET_CPU, cv.dnn.DNN_TARGET_OPENCL, cv.dnn.DNN_TARGET_OPENCL_FP16, cv.dnn.DNN_TARGET_MYRIAD)
parser = argparse.ArgumentParser(add_help=False)
parser.add_argument('--input', default='./imgs/image.jpg')
parser.add_argument('--model', default='fcn8s-heavy-pascal.caffemodel')
parser.add_argument('--config', default='fcn8s-heavy-pascal.prototxt')
parser.add_argument('--classes', default='object_detection_classes_pascal_voc.txt')
parser.add_argument('--width', type=int, default=500)
parser.add_argument('--height', type=int, default=500)
parser.add_argument('--framework', default='caffe')
parser.add_argument('--mean', default=[0, 0, 0])
parser.add_argument('--rgb', default=False)
parser.add_argument('--colors', default=None)
parser.add_argument('--scale', type=float, default=1.0)
parser.add_argument('--backend', choices=backends, default=cv.dnn.DNN_BACKEND_DEFAULT, type=int,
help="Choose one of computation backends: "
"%d: automatically (by default), "
"%d: Halide language (http://halide-lang.org/), "
"%d: Intel's Deep Learning Inference Engine (https://software.intel.com/openvino-toolkit), "
"%d: OpenCV implementation" % backends)
parser.add_argument('--target', choices=targets, default=cv.dnn.DNN_TARGET_CPU, type=int,
help='Choose one of target computation devices: '
'%d: CPU target (by default), '
'%d: OpenCL, '
'%d: OpenCL fp16 (half-float precision), '
'%d: VPU' % targets)
args = parser.parse_args()
np.random.seed(324)
# Load names of classes
classes = None
if args.classes:
with open(args.classes, 'rt') as f:
classes = f.read().rstrip('\n').split('\n')
# Load colors
colors = None
if args.colors:
with open(args.colors, 'rt') as f:
colors = [np.array(color.split(' '), np.uint8) for color in f.read().rstrip('\n').split('\n')]
legend = None
def showLegend(classes):
global legend
if not classes is None and legend is None:
blockHeight = 30
assert(len(classes) == len(colors))
legend = np.zeros((blockHeight * len(colors), 200, 3), np.uint8)
for i in range(len(classes)):
block = legend[i * blockHeight:(i + 1) * blockHeight]
block[:,:] = colors[i]
cv.putText(block, classes[i], (0, blockHeight//2), cv.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
cv.namedWindow('Legend', cv.WINDOW_NORMAL)
cv.imshow('Legend', legend)
# Load a network
net = cv.dnn.readNet(args.model, args.config, args.framework)
net.setPreferableBackend(args.backend)
net.setPreferableTarget(args.target)
legend = None
frame = cv.imread(args.input)
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
# Create a 4D blob from a frame.
inpWidth = args.width if args.width else frameWidth
inpHeight = args.height if args.height else frameHeight
blob = cv.dnn.blobFromImage(frame, args.scale, (inpWidth, inpHeight), args.mean, args.rgb, crop=False)
# Run a model
net.setInput(blob)
score = net.forward()
numClasses = score.shape[1]
height = score.shape[2]
width = score.shape[3]
# Draw segmentation
if not colors:
# Generate colors
colors = [np.array([0, 0, 0], np.uint8)]
for i in range(1, numClasses):
colors.append((colors[i - 1] + np.random.randint(0, 256, [3], np.uint8)) / 2)
classIds = np.argmax(score[0], axis=0)
segm = np.stack([colors[idx] for idx in classIds.flatten()])
segm = segm.reshape(height, width, 3)
segm = cv.resize(segm, (frameWidth, frameHeight), interpolation=cv.INTER_NEAREST)
frame = (0.1 * frame + 0.9 * segm).astype(np.uint8)
# Put efficiency information.
t, _ = net.getPerfProfile()
label = 'Inference time: %.2f ms' % (t * 1000.0 / cv.getTickFrequency())
cv.putText(frame, label, (0, 15), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0))
pos = args.input.rfind('/')
if pos == -1:
out_path = './seg_' + args.input
else:
out_path = args.input[:pos+1] + 'seg_' + args.input[pos+1:]
cv.imwrite(out_path, frame)
showLegend(classes)
cv.namedWindow('segmentation', cv.WINDOW_NORMAL)
cv.resizeWindow('segmentation', (800, int(frameHeight/frameWidth * 800)))
cv.imshow('segmentation', frame)
cv.waitKey(0)
cv.destroyAllWindows()
运行结果:

风格转换
准备
官方代码:
https://github.com/opencv/opencv/blob/master/samples/dnn/fast_neural_style.py
训练好的模型(模型参数文件)在:
https://cs.stanford.edu/people/jcjohns/fast-neural-style/models/eccv16/starry_night.t7
测试图片在:
https://github.com/jcjohnson/fast-neural-style/tree/master/images/content
代码
from __future__ import print_function
import cv2 as cv
import numpy as np
import argparse
# model:
# https://cs.stanford.edu/people/jcjohns/fast-neural-style/models/eccv16/starry_night.t7
# images:
# https://github.com/jcjohnson/fast-neural-style/tree/master/images/content
parser = argparse.ArgumentParser(
description='This script is used to run style transfer models from '
'https://github.com/jcjohnson/fast-neural-style using OpenCV')
parser.add_argument('--input', default='./imgs/ustc.jpg', help='Path to image or video. Skip to capture frames from camera')
parser.add_argument('--model', default='./starry_night.t7', help='Path to .t7 model')
parser.add_argument('--width', default=-1, type=int, help='Resize input to specific width.')
parser.add_argument('--height', default=-1, type=int, help='Resize input to specific height.')
parser.add_argument('--median_filter', default=0, type=int, help='Kernel size of postprocessing blurring.')
args = parser.parse_args()
net = cv.dnn.readNetFromTorch(cv.samples.findFile(args.model))
net.setPreferableBackend(cv.dnn.DNN_BACKEND_OPENCV)
img = cv.imread(args.input, cv.IMREAD_UNCHANGED)
inWidth = args.width if args.width != -1 else img.shape[1]
inHeight = args.height if args.height != -1 else img.shape[0]
inp = cv.dnn.blobFromImage(img, 1.0, (inWidth, inHeight),
(103.939, 116.779, 123.68), swapRB=False, crop=False)
net.setInput(inp)
out = net.forward()
out = out.reshape(3, out.shape[2], out.shape[3])
out[0] += 103.939
out[1] += 116.779
out[2] += 123.68
out /= 255
out = out.transpose(1, 2, 0)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
print(t / freq, 'ms')
if args.median_filter:
out = cv.medianBlur(out, args.median_filter)
out_convert = out.copy()
out_convert[out_convert < 0] = 0
out_convert[out_convert > 1] = 1
out_convert = (out_convert * 255).astype(np.uint8)
pos = args.input.rfind('/')
if pos == -1:
out_path = './style_' + args.input
else:
out_path = args.input[:pos+1] + 'style_' + args.input[pos+1:]
cv.imwrite(out_path, out_convert)
cv.namedWindow('Raw image', cv.WINDOW_NORMAL)
cv.resizeWindow('Raw image', (800, int(inHeight/inWidth * 800)))
cv.imshow('Raw image', img)
cv.namedWindow('Style image', cv.WINDOW_NORMAL)
cv.resizeWindow('Style image', (800, int(inHeight/inWidth * 800)))
cv.imshow('Style image', out)
cv.waitKey(0)
cv.destroyAllWindows()
输入原图:

运行结果:



















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











