






欲修其身,先正其心。格物致知。话说千遍,不如动手一遍。
文章目录
似乎过了很久… 前些日子,我突然发现我悟了。那一刻是真的很爽,思绪不断; 也就是那一刻,我发现他人的看法,其实一点也不重要。世上所有的话语,似乎都具有某种目的。那些重要么? 重病还不是要挂!爱情,物质,婚姻,家庭? 这些概念讲的真好。 可我为什么要在乎呢? 追求这些毫无意义!追求科学才是真理!倘若科技水平高,为何不造个跟自己三观相合的人?凭什么那些所谓的普世的观点要强加在我的身上? 干活累,为什么不能压榨机器人? 空间距离远,为什么没有空间门? 明明有互联网,为什么不能搞个超大电子图书馆?繁衍后代?我想都有试管婴儿,那再研究研究…
其实,说到底就是自己不行,那就是说要从自身开始。
实验的目标是说添加系统调用。我分三个部分(思路+实践+总结)。代码跟结果在实践(12、 结果代码以及截图)处。
为了添加系统调用。我需要在include/linux/unistd.h定义系统调用号以及用户态函数名称。接着,在include/linux/sys.h这里,extern内核态函数名称, 同时将该内核态函数名称添加到了系统调用表(sys_call_table)里边。接着,在include/system_call.s这里,修改nr_system_calls数值。然后,实现在sys.h定义的内核态函数声明。最后,修改makefile文件,将我的代码编译合并进内核。运行进入linux0.11系统,我们需要修改/usr/include/unistd.h文件,让它跟我们在源码里文件保持一致。接着,创建编译iam.c,whoami.c测试文件。最后,按顺序运行iam,whoami可执行文件。
为何c语言可以写操作系统?
1、c语言---汇编语言----机器语言,三者是可以转换的。
2、cpu--内存,取指令--译指令--执行指令,说简单点其实就是从内存拿数据,然后cpu执行。
综上所说,我们只需要把代码和数据,放到内存里边就可以了。
不过,怎么放,放哪里,放了之后,又如何用。这到是个大问题。
一、思路
经过学习:我有以下四个疑问。
linux源码编译运行环境搭建?
linux源码目录跟文件大概含义?
用户态如何进入内核态?
linux源码里边系统调用逻辑?
搞清楚这几个问题,其实添加系统调用异常简单。毕竟我又不是从零去写操作系统。从这里来讲,它确实容易。
其1:linux源码编译运行环境搭建
我采用deepin20.7 + 安装gcc3.4及其配套软件 + linux0.11内核源码。注意由于是64位下编译代码,需要修改linux内核源码的
Makefile文件。怎么修改?了解里边的工具,然后尝试编译,查看编译结果,确定问题,再尝试。
比如下边这个Makefile文件中的objcopy,strip:
# 定义RAM盘,若定义了则需要指定参数DRAMDISK块大小
RAMDISK = #-DRAMDISK=512
# 8086汇编语言的汇编器与链接器
# -0表示生成8086目标程序
AS86 =as86 -0 -a
LD86 =ld86 -0
# GNU编译器与链接器
AS =as
LD =ld
# GNU链接器LD的参数
# -m elf_i386表示以elf格式输出i386的32位代码
# -Ttext 0表示代码在0处加载/对齐
# -e startup_32表示指定startup_32为入口点
LDFLAGS =-m elf_i386 -Ttext 0 -e startup_32
# 指定gcc-3.4编译时使用-i386的指令集
CC =gcc-3.4 -march=i386 $(RAMDISK)
# -m32表示在64位编译器上生成32位的代码
# -g表示生成调试文件(用于GDB调试)
# -Wall表示打印警告信息
# -O2表示使用二级优化
# -fomit-frame-pointer表示对无需帧指针的函数不把帧指针保留在寄存器中
CFLAGS =-m32 -g -Wall -O2 -fomit-frame-pointer
# 指定头文件的搜索目录为当前目录下的include(即不使用系统/usr/include目录下的头文件)
CPP =cpp -nostdinc -Iinclude
# 指定在build程序创建内核映像文件(Image)时所使用的默认根文件系统所在的设备(未指定时,使用默认值/dev/hd6)
ROOT_DEV= #FLOPPY
# 制作静态库文件(主要是与硬件交互的驱动程序)
ARCHIVES=kernel/kernel.o mm/mm.o fs/fs.o
DRIVERS =kernel/blk_drv/blk_drv.a kernel/chr_drv/chr_drv.a
MATH =kernel/math/math.a
LIBS =lib/lib.a
# 定义3条了make的隐式规则
# 当源文件是.c文件,目标文件是.s文件,则使用第1条规则
# 当源文件是.s文件,目标文件是.o文件,则使用第2条规则
# 当源文件是.c文件,目标文件是.o文件,则使用第3条规则
.c.s:
$(CC) $(CFLAGS) \
-nostdinc -Iinclude -S -o $*.s $<
.s.o:
$(AS) -o $*.o $<
.c.o:
$(CC) $(CFLAGS) \
-nostdinc -Iinclude -c -o $*.o $<
# all为当前MAkefile文件的最终目标,其依赖于Image(make基本知识)
all: Image
# 用于生成Image映像文件,其依赖于4个目标文件
# 当要素齐全时,执行命令生成Image映像文件
# -O elf32-i386 -B i386 -I binary
# -O binary
# copy是GNU Binutils中的一个工具,用于将目标文件中的某些部分复制到另一个文件中。
# strip命令主要是精简文件,削减文件大小。
# objcopy命令是将目标文件(elf文件)的一部分或者全部内容拷贝到另外一个目标文件中,也可以实现目标文件的格式转换。
# 其中,-O binary选项表示将目标文件转换为二进制文件,-R .note和-R .comment选项
# 表示从目标文件中删除.note和.comment节。因此,objcopy -O binary -R .note -R
# .comment system.tmp tools/kernel命令的作用是将system.tmp文件转换为二进制文件,
# 并将其中的.note和.comment跟.note.gnu.property节删除后保存为tools/kernel文件。
# 原本代码: objcopy -O binary -R .note -R .comment system.tmp tools/kernel
# 修改代码:objcopy -O binary -R .note.gnu.property -R .comment system.tmp tools/kernel
# 修改原因:在linux64位系统操作时,原代码命令会产生多余数据,最终导致编译后的系统过大。
# 我执行readelf -S -W system.tmp命令,发现如下几个段.note.gnu.property .text .rodata .data .bss .comment .shstrtab。
# 查找资料发现.note.gnu.property .comment,属于多余的段。最后我采用-R .comment -R .note.gnu.property来删除。
# elf格式
# .text 代码段,存放编译生成的机器码
# .rodata 只读数据段,存放只读数据,一般是程序中的只读静态变量和字符串常量
# .rodata1 只读数据段,存放字符串常量,全局const变量
# .data 数据段,保存已经初始化的全局静态变量和局部静态变量
# .bss 存储未初始化以及初始化为0的全局静态变量和局部静态变量
# .comment 存放编译器版本信息
# .debug 调试信息
# .dynamic 动态链接信息
# .hash 符号哈希表
# .line 调试时行号表,即源代码行号与编译后指令的对应表
# .note 额外的编译器信息
# .strtab 字符串表,存放elf文件中用到的各种字符串
# .rela.xxx 重定位表
# .shstrtab 字符串表,存放各个段的名称
# .symtab 符号表,可以找到文件中的各个符号
# .plt和.got 动态链接的跳转表和全局入口表
# .init和.fini 程序初始化和终结代码段
Image: boot/bootsect boot/setup tools/system tools/build
cp -f tools/system system.tmp
strip system.tmp
objcopy -O binary -R .note.gnu.property -R .comment system.tmp tools/kernel
tools/build boot/bootsect boot/setup tools/kernel $(ROOT_DEV) > Image
rm system.tmp
rm tools/kernel -f
sync
# 将映像文件Image制作为系统启动盘
disk: Image
dd bs=8192 if=Image of=/dev/fd0
# 仅使用bootsect模块与setup模块制作映像文件
BootImage: boot/bootsect boot/setup tools/build
tools/build boot/bootsect boot/setup none $(ROOT_DEV) > Image
sync
# 编译链接build.c程序
tools/build: tools/build.c
gcc $(CFLAGS) \
-o tools/build tools/build.c
# 汇编链接head.s程序
boot/head.o: boot/head.s
gcc-3.4 -m32 -g -I./include -traditional -c boot/head.s
mv head.o boot/
# 链接生成system
tools/system: boot/head.o init/main.o \
$(ARCHIVES) $(DRIVERS) $(MATH) $(LIBS)
$(LD) $(LDFLAGS) boot/head.o init/main.o \
$(ARCHIVES) \
$(DRIVERS) \
$(MATH) \
$(LIBS) \
-o tools/system
nm tools/system | grep -v '\(compiled\)\|\(\.o$$\)\|\( [aU] \)\|\(\.\.ng$$\)\|\(LASH[RL]DI\)'| sort > System.map
# 制作数学函数库文件
kernel/math/math.a: FORCE
(cd kernel/math; make)
# 制作块设备函数库文件
kernel/blk_drv/blk_drv.a: FORCE
(cd kernel/blk_drv; make)
# 制作字符设备函数库文件
kernel/chr_drv/chr_drv.a: FORCE
(cd kernel/chr_drv; make)
# 编译生成内核目标文件
kernel/kernel.o: FORCE
(cd kernel; make)
# 编译生成内存管理目标文件
mm/mm.o: FORCE
(cd mm; make)
# 编译生成文件系统目标文件
fs/fs.o: FORCE
(cd fs; make)
# 制作静态库函数
lib/lib.a: FORCE
(cd lib; make)
# 使用86的汇编器和链接器编译生成setup文件
boot/setup: boot/setup.s
$(AS86) -o boot/setup.o boot/setup.s
$(LD86) -s -o boot/setup boot/setup.o
# 使用86的汇编器和链接器编译生成bootsect文件
boot/bootsect: boot/bootsect.s
$(AS86) -o boot/bootsect.o boot/bootsect.s
$(LD86) -s -o boot/bootsect boot/bootsect.o
# 用于在boot/bootsect.s的头部添加system模块的文件长度信息,
# 现在system模块的文件长度信息直接在boot/bootsect.s的头部定义了,这一步骤已经被弃用
tmp.s: boot/bootsect.s tools/system
(echo -n "SYSSIZE = (";ls -l tools/system | grep system \
| cut -c25-31 | tr '\012' ' '; echo "+ 15 ) / 16") > tmp.s
cat boot/bootsect.s >> tmp.s
# 用于清除make执行过程中生成的中间文件
clean:
rm -f Image System.map tmp_make core boot/bootsect boot/setup
rm -f init/*.o tools/system tools/build boot/*.o
(cd mm;make clean)
(cd fs;make clean)
(cd kernel;make clean)
(cd lib;make clean)
rm -f system.tmp
rm -f tools/kernel
# 先调用clean清除中间文件,然后对整个操作系统代码进行压缩生成.Z文件
backup: clean
(cd .. ; tar cf - linux | compress16 - > backup.Z)
sync
# 用于产生文件之间的依赖关系
dep:
sed '/\#\#\# Dependencies/q' < Makefile > tmp_make
(for i in init/*.c;do echo -n "init/";$(CPP) -M $$i;done) >> tmp_make
cp tmp_make Makefile
(cd fs; make dep)
(cd kernel; make dep)
(cd mm; make dep)
# Force make run into subdirectories even no changes on source
FORCE:
# 利用隐式规则生成main.o
### Dependencies:
init/main.o: init/main.c include/unistd.h include/sys/stat.h \
include/sys/types.h include/sys/times.h include/sys/utsname.h \
include/utime.h include/time.h include/linux/tty.h include/termios.h \
include/linux/sched.h include/linux/head.h include/linux/fs.h \
include/linux/mm.h include/signal.h include/asm/system.h \
include/asm/io.h include/stddef.h include/stdarg.h include/fcntl.h
其2:linux源码目录跟文件大概含义
我参考《LINUX内核完全剖析:基于0.12内核》,制作了一个linux0.11内核源码目录文件说明的思维导图。针对某个目标,这里我建好了环境,那我应该需要知道自己具体要修改哪些文件。
可能需要修改或查看的文件:
include/linux/sys.h: 该头文件列出了内核中所有系统调用函数的原型,以及系统调用函数指针表。
include/unistd.h: 标准符号常数和类型头文件。该文件中定义了很多各种各样的常数和类型,以及一些函数声明。
kernel/sys.c: 该程序含有很多调用功能的实现函数。
kernel/system_call.s: 本程序主要实现系统调用(system_call)中断int 0x80的入口处理过程以及信息检测处理,同时给出了两个系统功能的底层接口,分别是sys_execve和sys_fork。还列出了处理过程类似的协处理器出错(int 16)、设备不存在(int 7)、时钟中断(int 32)、硬盘中断(int 46)、软盘中断(int 38)的中断处理程序。
lib目录:内核库函数,这里可以也看到一些系统调用函数。
其3:用户态如何进入内核态?
linux系统分为用户态跟内核态,用户程序通过系统调用来进入内核态。在学习中,我得出以下顺序:
用户程序 —> C函数库 ----> 系统调用 ----> 内核函数如sys_write ----> 驱动程序 ----> 具体硬件
为什么要了解这个?在第二点,我知道了我大概要修改什么文件。这些文件多了还是少了,我并不清楚。
用户程序,我用fork()函数创建进程,可到了内核就变为sys_fork()。
在include/linux/unistd.h定义系统调用号“#define __NR_fork 2”以及函数名称”int fork(void);“,且该函数名称与其定义的宏结合(形成其函数实现)。
这里的意思应该是“用户态程序触发系统调用的逻辑“。
在include/linux/sys.h这里,extern了sys_fork, 同时将sys_fork添加到了系统调用表(sys_call_table)里边。从这里开始,它跟内核态有关了。
在kernel/sys.c这里,它里边有内核系统调用实现,可是sys_fork的实现是在system_call.s里边。sys.c并没有包含sys.h?
sys.s sys.o: sys.c ../include/errno.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/sys/types.h \
../include/linux/mm.h ../include/signal.h ../include/linux/tty.h \
../include/termios.h ../include/linux/kernel.h ../include/asm/segment.h \
../include/sys/times.h ../include/sys/utsname.h
虽说这里没包含,可makefile链接合并时却包含了。看到sys.h只出现了一次,而head.h却出现很多次。
这两者有何区别? 两者都出现了extern。不过head.h增加了“#ifndef _HEAD_H #define _HEAD_H”
这类语句。
查看lib目录下文件,它似乎就是include/linux/unistd.h里边的套路。
其4:linux源码里边系统调用逻辑?
这里的话,其实就是阅读部分源码。在学习中,我得出以下逻辑:
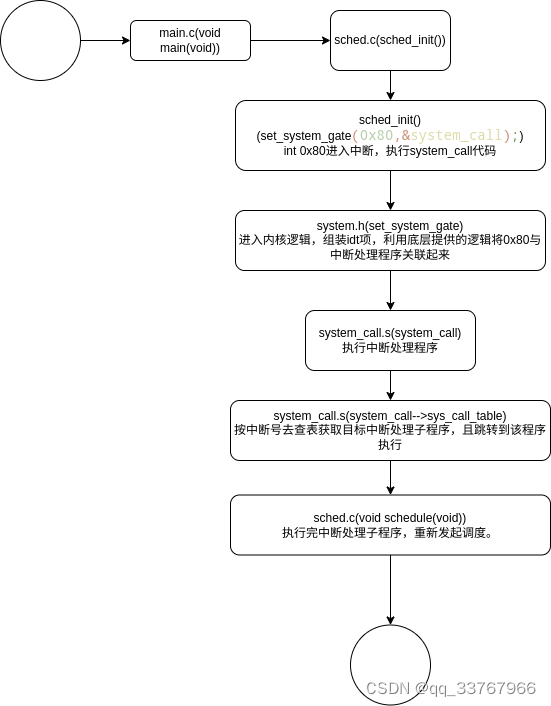
虽说我记不清idt与中断的联系,但我有点印象。按我看到的书籍跟视频,在我的大脑里边这可以说是比较合理的解释了。
中断处理逻辑核心程序:system_call代码
system_call:
cmpl $nr_system_calls-1,%eax # 判断调用号是否超范围
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs points to local data space
mov %dx,%fs
call sys_call_table(,%eax,4) # 根据调用号查表,确定目标中断子程序位置,并调用该程序
pushl %eax
movl current,%eax
cmpl $0,state(%eax) # state
jne reschedule
cmpl $0,counter(%eax) # counter
je reschedule
init/main.c: 首先确定如何分配使用系统物理内存,然后调用内核各部分的初始化函数分别对内存管理、中断处理、块设备和字符设备、进程管理以及硬盘和软盘等硬件进行初始化处理。系统各部分已经处于可运行状态。此后它将自己“手工“移动到任务0(进程0)中运行,并使用fork()调用首次创建出进程1(init进程),并在其中调用init()函数。该函数中程序将继续进行应用环境初始化并执行shell登陆程序。而原进程0则会在系统空闲时被调度执行,因此进程0通常也被成为idle进程。此时进程0仅执行pause()系统调用,并又会调用调度函数。
kernel/sched.c: 它是内核中有关任务(进程)调度管理的程序,其中包括有关调度的基本函数以及一些简单的系统调用函数。系统时钟中断处理过程中调用的定时函数do_timer()也被放置在本程序中。另外,为了便于软盘驱动器定时处理的编程,Linus也将有关软盘定时操作的几个函数放到了这里。
小结:
为了添加系统调用。我需要在include/linux/unistd.h定义系统调用号以及用户态函数名称。接着,在include/linux/sys.h这里,extern了内核态函数名称, 同时将该内核态函数名称添加到了系统调用表(sys_call_table)里边。接着,在include/system_call.s这里,修改nr_system_calls数值。然后,实现在sys.h定义的内核态函数声明。最后,修改makefile文件,将我的代码编译合并进内核。
二、实践
1、实验内容
此次实验的基本内容是:在 Linux 0.11 上添加两个系统调用,并编写两个
简单的应用程序测试它们。
(1)iam()
第一个系统调用是 iam(),其原型为:
int iam(const char * name);
完成的功能是将字符串参数 name 的内容拷贝到内核中保存下来。要求
name 的长度不能超过 23 个字符。返回值是拷贝的字符数。如果 name 的
字符个数超过了 23,则返回 “-1”,并置 errno 为 EINVAL。
在 kernal/who.c 中实现此系统调用。
(2)whoami()
第二个系统调用是 whoami(),其原型为:
int whoami(char* name, unsigned int size);
它将内核中由 iam() 保存的名字拷贝到 name 指向的用户地址空间中,同
时确保不会对 name 越界访存(name 的大小由 size 说明)。返回值是拷
贝的字符数。如果 size 小于需要的空间,则返回“-1”,并置 errno 为
EINVAL。
也是在 kernal/who.c 中实现。
(3)测试程序
运行添加过新系统调用的 Linux 0.11,在其环境下编写两个测试程序
iam.c 和 whoami.c。最终的运行结果是:
$ ./iam lizhijun
$ ./whoami
lizhijun
2、实验报告
在实验报告中回答如下问题:
从 Linux 0.11 现在的机制看,它的系统调用最多能传递几个参数?你能想
出办法来扩大这个限制吗?
用文字简要描述向 Linux 0.11 添加一个系统调用 foo() 的步骤。
3、操作系统实现系统调用的基本过程
(1)、应用程序调用库函数(API);
(2)、API 将系统调用号存入 EAX,然后通过中断调用使系统进入内核态;
(3)、内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
(4)、系统调用完成相应功能,将返回值存入 EAX,返回到中断处理函数;
(5)、中断处理函数返回到 API 中;
(6)、API 将 EAX 返回给应用程序
4、应用程序如何调用系统调用
在通常情况下,调用系统调用和调用一个普通的自定义函数在代码上并没有什么区
别,但调用后发生的事情有很大不同。
调用自定义函数是通过 call 指令直接跳转到该函数的地址,继续运行。
而调用系统调用,是调用系统库中为该系统调用编写的一个接口函数,叫 API
(Application Programming Interface)。API 并不能完成系统调用的
真正功能,它要做的是去调用真正的系统调用,过程是:
(1)、把系统调用的编号存入 EAX;
(2)、把函数参数存入其它通用寄存器;
(3)、触发 0x80 号中断(int 0x80)。
linux-0.11 的 lib 目录下有一些已经实现的 API。Linus 编写它们的原因
是在内核加载完毕后,会切换到用户模式下,做一些初始化工作,然后启动
shell。而用户模式下的很多工作需要依赖一些系统调用才能完成,因此在内核中
实现了这些系统调用的 API。
后面的目录如果没有特殊说明,都是指在linux-0.11 中。比如下面的 lib/close.c,是指 linux-0.11/lib/close.c。
我们不妨看看 lib/close.c,研究一下 close() 的 API:
#define __LIBRARY__
#include <unistd.h>
_syscall1(int, close, int, fd)
其中 _syscall1 是一个宏,在 include/unistd.h 中定义。
#define _syscall1(type,name,atype,a) \
type name(atype a) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a))); \
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
将 _syscall1(int,close,int,fd) 进行宏展开,可以得到:
int close(int fd)
{
long __res;
__asm__ volatile ("int $0x80"
: "=a" (__res)
: "0" (__NR_close),"b" ((long)(fd)));
if (__res >= 0)
return (int) __res;
errno = -__res;
return -1;
}
这就是 API 的定义。它先将宏 __NR_close 存入 EAX,将参数 fd 存入
EBX,然后进行 0x80 中断调用。调用返回后,从 EAX 取出返回值,存入
__res,再通过对 __res 的判断决定传给 API 的调用者什么样的返回值。
其中 __NR_close 就是系统调用的编号,在 include/unistd.h 中定义:
#define __NR_close 6
/*
所以添加系统调用时需要修改include/unistd.h文件,
使其包含__NR_whoami和__NR_iam。
*/
/*
而在应用程序中,要有:
*/
/* 有它,_syscall1 等才有效。详见unistd.h */
#define __LIBRARY__
/* 有它,编译器才能获知自定义的系统调用的编号 */
#include "unistd.h"
/* iam()在用户空间的接口函数 */
_syscall1(int, iam, const char*, name);
/* whoami()在用户空间的接口函数 */
_syscall2(int, whoami,char*,name,unsigned int,size);
在 0.11 环境下编译 C 程序,包含的头文件都在 /usr/include 目录下。
该目录下的 unistd.h 是标准头文件(它和 0.11 源码树中的 unistd.h 并
不是同一个文件,虽然内容可能相同),没有 __NR_whoami 和 __NR_iam 两
个宏,需要手工加上它们,也可以直接从修改过的 0.11 源码树中拷贝新的
unistd.h 过来。
5、从“int 0x80”进入内核函数
int 0x80 触发后,接下来就是内核的中断处理了。先了解一下 0.11 处理
0x80 号中断的过程。
在内核初始化时,主函数(在 init/main.c 中,Linux 实验环境下是 main
(),Windows 下因编译器兼容性问题被换名为 start())调用了 sched_init() 初始化函数:
void main(void)
{
// ……
time_init();
sched_init();
buffer_init(buffer_memory_end);
// ……
}
sched_init() 在 kernel/sched.c 中定义为:
void sched_init(void)
{
// ……
set_system_gate(0x80,&system_call);
}
set_system_gate 是个宏,在 include/asm/system.h 中定义为:
#define set_system_gate(n,addr) \
_set_gate(&idt[n],15,3,addr)
_set_gate 的定义是:
#define _set_gate(gate_addr,type,dpl,addr) \
__asm__ ("movw %%dx,%%ax\n\t" \
"movw %0,%%dx\n\t" \
"movl %%eax,%1\n\t" \
"movl %%edx,%2" \
: \
: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \
"o" (*((char *) (gate_addr))), \
"o" (*(4+(char *) (gate_addr))), \
"d" ((char *) (addr)),"a" (0x00080000))
虽然看起来挺麻烦,但实际上很简单,就是填写 IDT(中断描述符表),将
system_call 函数地址写到 0x80 对应的中断描述符中,也就是在中断
0x80 发生后,自动调用函数 system_call。具体细节请参考《注释》的第 4
章。
接下来看 system_call。该函数纯汇编打造,定义在 kernel/system_call.s 中:
!……
! # 这是系统调用总数。如果增删了系统调用,必须做相应修改
nr_system_calls = 72
!……
.globl system_call
.align 2
system_call:
! # 检查系统调用编号是否在合法范围内
cmpl \$nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx
! # push %ebx,%ecx,%edx,是传递给系统调用的参数
pushl %ebx
! # 让ds, es指向GDT,内核地址空间
movl $0x10,%edx
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx
! # 让fs指向LDT,用户地址空间
mov %dx,%fs
call sys_call_table(,%eax,4)
pushl %eax
movl current,%eax
cmpl $0,state(%eax)
jne reschedule
cmpl $0,counter(%eax)
je reschedule
system_call 用 .globl 修饰为其他函数可见。
Windows 实验环境下会看到它有一个下划线前缀,这是不同版本编译器的特质决
定的,没有实质区别。
call sys_call_table(,%eax,4) 之前是一些压栈保护,修改段选择子为内
核段,call sys_call_table(,%eax,4) 之后是看看是否需要重新调度,这
些都与本实验没有直接关系,此处只关心 call sys_call_table(,%eax,4)
这一句。
根据汇编寻址方法它实际上是:call sys_call_table + 4 * %eax,其中
eax 中放的是系统调用号,即 __NR_xxxxxx。
显然,sys_call_table 一定是一个函数指针数组的起始地址,它定义在
include/linux/sys.h 中:
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,…
增加实验要求的系统调用,需要在这个函数表中增加两个函数引用 ——sys_iam 和 sys_whoami。当然该函数在 sys_call_table 数组中的位置必须和 __NR_xxxxxx 的值对应上。
同时还要仿照此文件中前面各个系统调用的写法,加上:
extern int sys_whoami();
extern int sys_iam();
不然,编译会出错的。
6、实现 sys_iam() 和 sys_whoami()
添加系统调用的最后一步,是在内核中实现函数 sys_iam() 和 sys_whoami()。
每个系统调用都有一个 sys_xxxxxx() 与之对应,它们都是我们学习和模仿的好对象。
比如在 fs/open.c 中的 sys_close(int fd):
int sys_close(unsigned int fd)
{
// ……
return (0);
}
它没有什么特别的,都是实实在在地做 close() 该做的事情。
所以只要自己创建一个文件:kernel/who.c,然后实现两个函数就万事大吉了。
7、修改 Makefile
要想让我们添加的 kernel/who.c 可以和其它 Linux 代码编译链接到一起,
必须要修改 Makefile 文件。
Makefile 里记录的是所有源程序文件的编译、链接规则,《注释》3.6 节有简
略介绍。我们之所以简单地运行 make 就可以编译整个代码树,是因为 make
完全按照 Makefile 里的指示工作。
如果想要深入学习 Makefile,可以选择实验楼的课程: 《Makefile 基础教
程》、《跟我一起来玩转 Makefile》。
Makefile 在代码树中有很多,分别负责不同模块的编译工作。我们要修改的是
kernel/Makefile。需要修改两处。
(1)第一处
OBJS = sched.o system_call.o traps.o asm.o fork.o \
panic.o printk.o vsprintf.o sys.o exit.o \
signal.o mktime.o
改为:
OBJS = sched.o system_call.o traps.o asm.o fork.o \
panic.o printk.o vsprintf.o sys.o exit.o \
signal.o mktime.o who.o
添加了 who.o。
(2)第二处
### Dependencies:
exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \
../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \
../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \
../include/asm/segment.h
改为:
### Dependencies:
who.s who.o: who.c ../include/linux/kernel.h ../include/unistd.h
exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \
../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \
../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \
../include/asm/segment.h
添加了 who.s who.o: who.c …/include/linux/kernel.h …/include/unistd.h。
Makefile 修改后,和往常一样 make all 就能自动把 who.c 加入到内核中
了。
如果编译时提示 who.c 有错误,就说明修改生效了。所以,有意或无意地制造
一两个错误也不完全是坏事,至少能证明 Makefile 是对的。
8、用 printk() 调试内核
oslab 实验环境提供了基于 C 语言和汇编语言的两种调试手段。除此之外,适
当地向屏幕输出一些程序运行状态的信息,也是一种很高效、便捷的调试方法,有
时甚至是唯一的方法,被称为“printf 法”。
要知道到,printf() 是一个只能在用户模式下执行的函数,而系统调用是在内
核模式中运行,所以 printf() 不可用,要用 printk()。
printk() 和 printf() 的接口和功能基本相同,只是代码上有一点点不同。
printk() 需要特别处理一下 fs 寄存器,它是专用于用户模式的段寄存器。
看一看 printk 的代码(在 kernel/printk.c 中)就知道了:
int printk(const char *fmt, ...)
{
// ……
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $buf\n\t"
"pushl $0\n\t"
"call tty_write\n\t"
"addl $8,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (i):"ax","cx","dx");
// ……
}
显然,printk() 首先 push %fs 保存这个指向用户段的寄存器,在最后
pop %fs 将其恢复,printk() 的核心仍然是调用 tty_write()。查看
printf() 可以看到,它最终也要落实到这个函数上。
9、编写测试程序
激动地运行一下由你亲手修改过的 “Linux 0.11 pro++”!然后编写一个简单
的应用程序进行测试。
比如在 sys_iam() 中向终端 printk() 一些信息,让应用程序调用 iam
(),从结果可以看出系统调用是否被真的调用到了。
可以直接在 Linux 0.11 环境下用 vi 编写(别忘了经常执行“sync”以确保
内存缓冲区的数据写入磁盘),也可以在 Ubuntu 或 Windows 下编完后再传
到 Linux 0.11 下。无论如何,最终都必须在 Linux 0.11 下编译。编译命
令是:
$ gcc -o iam iam.c -Wall
gcc 的 “-Wall” 参数是给出所有的编译警告信息,“-o” 参数指定生成的执行
文件名是 iam,用下面命令运行它:
$ ./iam
如果如愿输出了你的信息,就说明你添加的系统调用生效了。否则,就还要继续调
试,祝你好运!
10、在用户态和核心态之间传递数据
指针参数传递的是应用程序所在地址空间的逻辑地址,在内核中如果直接访问这个地址,访问到的
是内核空间中的数据,不会是用户空间的。所以这里还需要一点儿特殊工作,才能在内核中从用户
空间得到数据。
要实现的两个系统调用参数中都有字符串指针,非常像 open(char *filename, ……),所以我
们看一下 open() 系统调用是如何处理的。
int open(const char * filename, int flag, ...)
{
// ……
__asm__("int $0x80"
:"=a" (res)
:"0" (__NR_open),"b" (filename),"c" (flag),
"d" (va_arg(arg,int)));
// ……
}
可以看出,系统调用是用 eax、ebx、ecx、edx 寄存器来传递参数的。
其中 eax 传递了系统调用号,而 ebx、ecx、edx 是用来传递函数的参数的
ebx 对应第一个参数,ecx 对应第二个参数,依此类推。
如 open 所传递的文件名指针是由 ebx 传递的,也即进入内核后,通过 ebx 取出文件名字符
串。open 的 ebx 指向的数据在用户空间,而当前执行的是内核空间的代码,如何在用户态和核
心态之间传递数据?
接下来我们继续看看 open 的处理:
system_call: //所有的系统调用都从system_call开始
! ……
pushl %edx
pushl %ecx
pushl %ebx # push %ebx,%ecx,%edx,这是传递给系统调用的参数
movl $0x10,%edx # 让ds,es指向GDT,指向核心地址空间
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # 让fs指向的是LDT,指向用户地址空间
mov %dx,%fs
call sys_call_table(,%eax,4) # 即call sys_open
由上面的代码可以看出,获取用户地址空间(用户数据段)中的数据依靠的就是段寄存器 fs,下面
该转到 sys_open 执行了,在 fs/open.c 文件中:
int sys_open(const char * filename,int flag,int mode) //filename这些参数从哪里来?
/*是否记得上面的pushl %edx, pushl %ecx, pushl %ebx?
实际上一个C语言函数调用另一个C语言函数时,编译时就是将要
传递的参数压入栈中(第一个参数最后压,…),然后call …,
所以汇编程序调用C函数时,需要自己编写这些参数压栈的代码…*/
{
……
if ((i=open_namei(filename,flag,mode,&inode))<0) {
……
}
……
}
它将参数传给了 open_namei()。
再沿着 open_namei() 继续查找,文件名先后又被传给dir_namei()、get_dir()。
在 get_dir() 中可以看到:
static struct m_inode * get_dir(const char * pathname)
{
……
if ((c=get_fs_byte(pathname))=='/') {
……
}
……
}
处理方法就很显然了:用 get_fs_byte() 获得一个字节的用户空间中的数据。
所以,在实现 iam() 时,调用 get_fs_byte() 即可。
但如何实现 whoami() 呢?即如何实现从核心态拷贝数据到用心态内存空间中
呢?
猜一猜,是否有 put_fs_byte()?有!看一看 include/asm/segment.h :
extern inline unsigned char get_fs_byte(const char * addr)
{
unsigned register char _v;
__asm__ ("movb %%fs:%1,%0":"=r" (_v):"m" (*addr));
return _v;
}
extern inline void put_fs_byte(char val,char *addr)
{
__asm__ ("movb %0,%%fs:%1"::"r" (val),"m" (*addr));
}
他俩以及所有 put_fs_xxx() 和 get_fs_xxx() 都是用户空间和内核空间之
间的桥梁,在后面的实验中还要经常用到。
11、运行脚本程序
Linux 的一大特色是可以编写功能强大的 shell 脚本,提高工作效率。本实验的部分评分工作由
脚本 testlab2.sh 完成。它的功能是测试 iam.c 和 whoami.c。
首先将 iam.c 和 whoami.c 分别编译成 iam 和 whoami,然后将 testlab2.sh(在 /
home/teacher 目录下) 拷贝到同一目录下。
用下面命令为此脚本增加执行权限:
$ chmod +x testlab2.sh
然后运行之:
$ ./testlab2.sh
根据输出,可知 iam.c 和 whoami.c 的得分。
errno
errno 是一种传统的错误代码返回机制。
当一个函数调用出错时,通常会返回 -1 给调用者。但 -1 只能说明出错,不能说明错是什么。为
解决此问题,全局变量 errno 登场了。错误值被存放到 errno 中,于是调用者就可以通过判
断 errno 来决定如何应对错误了。
各种系统对 errno 的值的含义都有标准定义。Linux 下用“man errno”可以看到这些定义。
12、 结果代码以及截图
12.1、打开include/linux/unistd.h,添加代码
// 在__NR_setregid后面添加iam系统调用号
#define __NR_iam 72
#define __NR_whoami 73
// 在pid_t setsid(void);后面添加用户接口函数定义
int iam(const char * name);
int whoami(char* name, unsigned int size);
12.2、进入lib目录,在其下创建iam.c,whoami.c文件
// iam.c内容
#define __LIBRARY__
#include <unistd.h>
/**
* 返回类型
* 函数名称
* 参数1类型
* 参数1名称
*/
_syscall1(int,iam,const char *,name);
// whoami.c内容
#define __LIBRARY__
#include <unistd.h>
/**
* 返回类型
* 函数名称
* 参数1类型
* 参数1名称
* 参数2类型
* 参数2名称
*/
_syscall2(int,whoami,char *,name,unsigned int,size);
12.3、修改lib/Makefile
AR =ar
AS =as
LD =ld
LDFLAGS =-m elf_i386 -x
CC =gcc-3.4 -march=i386
CFLAGS =-m32 -g -Wall -O -fstrength-reduce -fomit-frame-pointer \
-finline-functions -nostdinc -I../include
CPP =gcc-3.4 -E -nostdinc -I../include
.c.s:
$(CC) $(CFLAGS) \
-S -o $*.s $<
.s.o:
$(AS) -o $*.o $<
.c.o:
$(CC) $(CFLAGS) \
-c -o $*.o $<
OBJS = ctype.o _exit.o open.o close.o errno.o write.o dup.o setsid.o \
execve.o wait.o string.o malloc.o iam.o whoami.o
lib.a: $(OBJS)
$(AR) rcs lib.a $(OBJS)
sync
clean:
rm -f core *.o *.a tmp_make
for i in *.c;do rm -f `basename $$i .c`.s;done
dep:
sed '/\#\#\# Dependencies/q' < Makefile > tmp_make
(for i in *.c;do echo -n `echo $$i | sed 's,\.c,\.s,'`" "; \
$(CPP) -M $$i;done) >> tmp_make
cp tmp_make Makefile
### Dependencies:
_exit.s _exit.o : _exit.c ../include/unistd.h ../include/sys/stat.h \
../include/sys/types.h ../include/sys/times.h ../include/sys/utsname.h \
../include/utime.h
close.s close.o : close.c ../include/unistd.h ../include/sys/stat.h \
../include/sys/types.h ../include/sys/times.h ../include/sys/utsname.h \
../include/utime.h
ctype.s ctype.o : ctype.c ../include/ctype.h
dup.s dup.o : dup.c ../include/unistd.h ../include/sys/stat.h \
../include/sys/types.h ../include/sys/times.h ../include/sys/utsname.h \
../include/utime.h
errno.s errno.o : errno.c
execve.s execve.o : execve.c ../include/unistd.h ../include/sys/stat.h \
../include/sys/types.h ../include/sys/times.h ../include/sys/utsname.h \
../include/utime.h
malloc.s malloc.o : malloc.c ../include/linux/kernel.h ../include/linux/mm.h \
../include/asm/system.h
open.s open.o : open.c ../include/unistd.h ../include/sys/stat.h \
../include/sys/types.h ../include/sys/times.h ../include/sys/utsname.h \
../include/utime.h ../include/stdarg.h
setsid.s setsid.o : setsid.c ../include/unistd.h ../include/sys/stat.h \
../include/sys/types.h ../include/sys/times.h ../include/sys/utsname.h \
../include/utime.h
string.s string.o : string.c ../include/string.h
wait.s wait.o : wait.c ../include/unistd.h ../include/sys/stat.h \
../include/sys/types.h ../include/sys/times.h ../include/sys/utsname.h \
../include/utime.h ../include/sys/wait.h
write.s write.o : write.c ../include/unistd.h ../include/sys/stat.h \
../include/sys/types.h ../include/sys/times.h ../include/sys/utsname.h \
../include/utime.h
iam.s iam.o : iam.c ../include/unistd.h
whoami.s whoami.o : whoami.c ../include/unistd.h
12.4、打开include/linux/sys.h,添加extern内核接口函数名称,并将该名称添加到系统调用表
// 在extern int sys_setregid();后面添加extern内核接口函数名称
extern int sys_iam();
extern int sys_whoami();
// 在sys_call_table表中添加映射关系,具体在sys_setregid后面添加
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid,sys_iam,sys_whoami };
12.5、打开kernel/system_call.s, 将nr_system_calls的值加2
# 将其加2,变为74
nr_system_calls = 74
12.6、实现sys_iam,sys_whoami内核接口函数。
这里的话新创建一个文件kernel/who.c,再将实现写在里边。
#include <errno.h>
#include <linux/kernel.h>
#include <asm/segment.h>
char who_kernel_buffer[24] = {0};
/*
该函数将字符串参数 name 的内容拷贝到内核中保存下来。要求 name 的
长度不能超过 23 个字符。返回值是拷贝的字符数。如果 name 的字符个
数超过了 23,则返回 “-1”,并置 errno 为 EINVAL。
static inline unsigned char get_fs_byte(const char * addr)
注意!
指针参数传递的是应用程序所在地址空间的逻辑地址,在内核中如果直接访问这个地址,
访问到的是内核空间中的数据,不会是用户空间的。
*/
int sys_iam(const char * name){
// 定义局部变量
char c;
int count = 0;
// 从用户空间拿数据到内核
while ((c=get_fs_byte(name++)) != '\0') {
who_kernel_buffer[count] = c;
count++;
}
// 字符串为空
if(count<=0){
return count;
}
// 字符串长度超过23
if(count > 23){
errno = EINVAL;
return -1;
}
who_kernel_buffer[count] = '\0';
// 打印拿到的值
printk("sys_iam print kernel data: %s\n\r",who_kernel_buffer);
// 返回字符个数
return count;
}
/*
它将内核中由 iam() 保存的名字拷贝到 name 指向的用户地址空间中,同
时确保不会对 name 越界访存(name 的大小由 size 说明)。返回值是拷
贝的字符数。如果 size 小于需要的空间,则返回“-1”,并置 errno 为
EINVAL。
static inline void put_fs_byte(char val,char *addr)
*/
int sys_whoami(char* name, unsigned int size){
// 定义局部变量
char c;
int index = 0;
int dataSize = 0;
// 指针为空或size为0
if(!name || (size == 0)){
return 0;
}
// 计算数据大小
printk("sys_iam print kernel data: %s\n\r",who_kernel_buffer);
while((who_kernel_buffer[index++] != '\0') && index <= 23);
dataSize = index*sizeof(char);
// 如果 size 小于需要的空间,则返回“-1”,并置 errno 为 EINVAL。
if(size < dataSize){
errno = EINVAL;
return -1;
}
// 从内核空间拿数据到用户空间
index = 0;
while ((c=who_kernel_buffer[index]) != '\0') {
put_fs_byte(c,(char *) (name+index));
index++;
}
put_fs_byte('\0',(char *) (name+index));
// 打印拿到的值,不能直接打印name数据,因为它属于用户空间数据
// printk("sys_whoami print kernel data: %s\n\r",name);
// 返回size
return dataSize;
}
12.7、修改kernel/Makefile文件
确保自己写的系统调用编译进内核。
AR =ar
AS =as --32
LD =ld
LDFLAGS =-m elf_i386 -x
CC =gcc-3.4 -march=i386
CFLAGS =-m32 -g -Wall -O -fstrength-reduce -fomit-frame-pointer \
-finline-functions -nostdinc -I../include
CPP =gcc-3.4 -E -nostdinc -I../include
.c.s:
$(CC) $(CFLAGS) \
-S -o $*.s $<
.s.o:
$(AS) -o $*.o $<
.c.o:
$(CC) $(CFLAGS) \
-c -o $*.o $<
OBJS = sched.o system_call.o traps.o asm.o fork.o \
panic.o printk.o vsprintf.o sys.o exit.o \
signal.o mktime.o who.o
kernel.o: $(OBJS)
$(LD) -m elf_i386 -r -o kernel.o $(OBJS)
sync
clean:
rm -f core *.o *.a tmp_make keyboard.s
for i in *.c;do rm -f `basename $$i .c`.s;done
(cd chr_drv; make clean)
(cd blk_drv; make clean)
(cd math; make clean)
dep:
sed '/\#\#\# Dependencies/q' < Makefile > tmp_make
(for i in *.c;do echo -n `echo $$i | sed 's,\.c,\.s,'`" "; \
$(CPP) -M $$i;done) >> tmp_make
cp tmp_make Makefile
(cd chr_drv; make dep)
(cd blk_drv; make dep)
### Dependencies:
exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \
../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \
../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \
../include/asm/segment.h
fork.s fork.o: fork.c ../include/errno.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/sys/types.h \
../include/linux/mm.h ../include/signal.h ../include/linux/kernel.h \
../include/asm/segment.h ../include/asm/system.h
mktime.s mktime.o: mktime.c ../include/time.h
panic.s panic.o: panic.c ../include/linux/kernel.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/sys/types.h \
../include/linux/mm.h ../include/signal.h
printk.s printk.o: printk.c ../include/stdarg.h ../include/stddef.h \
../include/linux/kernel.h
sched.s sched.o: sched.c ../include/linux/sched.h ../include/linux/head.h \
../include/linux/fs.h ../include/sys/types.h ../include/linux/mm.h \
../include/signal.h ../include/linux/kernel.h ../include/linux/sys.h \
../include/linux/fdreg.h ../include/asm/system.h ../include/asm/io.h \
../include/asm/segment.h
signal.s signal.o: signal.c ../include/linux/sched.h ../include/linux/head.h \
../include/linux/fs.h ../include/sys/types.h ../include/linux/mm.h \
../include/signal.h ../include/linux/kernel.h ../include/asm/segment.h
sys.s sys.o: sys.c ../include/errno.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/sys/types.h \
../include/linux/mm.h ../include/signal.h ../include/linux/tty.h \
../include/termios.h ../include/linux/kernel.h ../include/asm/segment.h \
../include/sys/times.h ../include/sys/utsname.h
traps.s traps.o: traps.c ../include/string.h ../include/linux/head.h \
../include/linux/sched.h ../include/linux/fs.h ../include/sys/types.h \
../include/linux/mm.h ../include/signal.h ../include/linux/kernel.h \
../include/asm/system.h ../include/asm/segment.h ../include/asm/io.h
vsprintf.s vsprintf.o: vsprintf.c ../include/stdarg.h ../include/string.h
who.s who.o: who.c ../include/errno.h ../include/linux/kernel.h \
../include/asm/segment.h
12.8、编译,运行操作系统
编译:
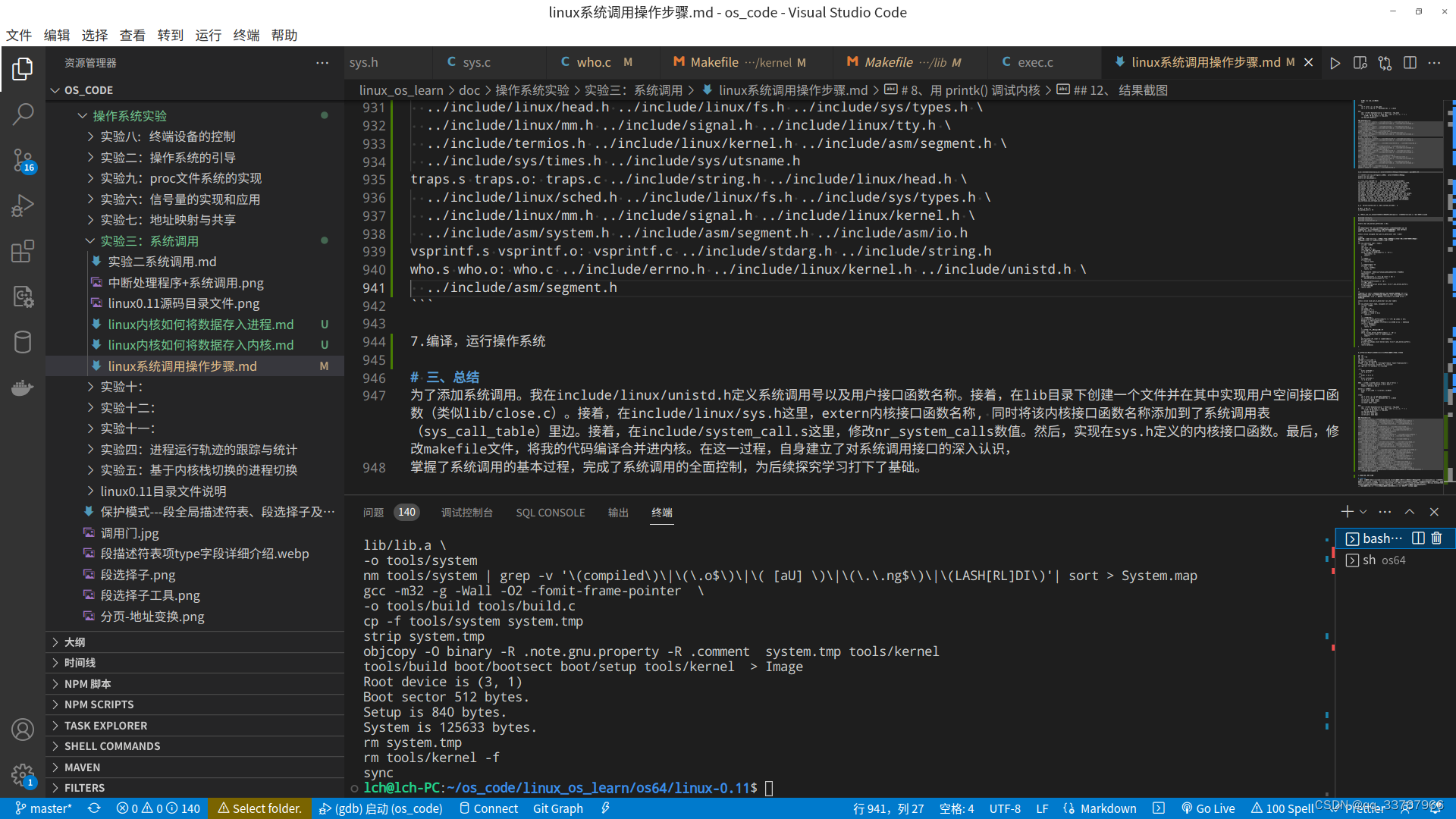
运行:
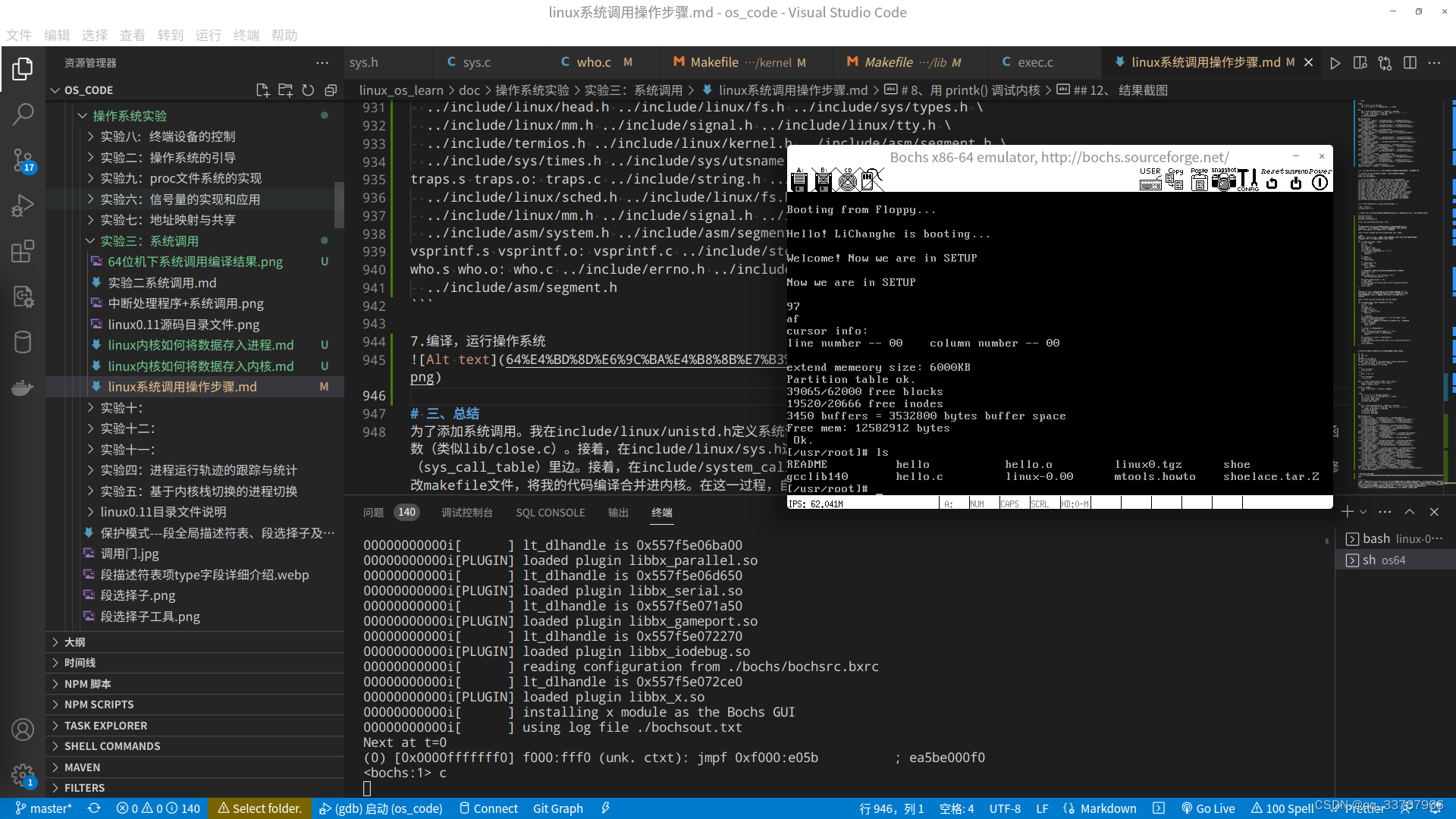
测试系统调用思路及问题:
运行操作系统。首先我们是在这个系统上编译C文件,那么按照gcc默认include路径,
我们需要检查下/usr/include/unistd.h,/usr/include/stdio.h是否符合要求。
经检查可得出:
运行的linux0.11系统,其/usr/include目录下的 unistd.h 是标准头文件(它和 0.11 源码树中的 unistd.h 并
不是同一个文件,虽然内容可能相同),没有 __NR_whoami 和 __NR_iam 两个宏,需要手工加上它们,也可以直接从
修改过的 0.11 源码树中拷贝新的 unistd.h 过来。
现在,再进入/usr/root在其中创建iam.c跟whoami.c文件,接着分别进行编译
gcc -o iam iam.c -Wall,gcc -o whoami whoami.c -Wall,最后按顺序分别执行./iam ./whoami。
参考“蓝桥云课”—静态链接库出错的解决办法
该实验只需修改 linux 源代码中的 /kernel/sytem_call.s 中的 nr_system_calls ,在 /include/linux/sys.h 中的 sys_call_table 添加对应的
系统调用函数,新增 who.c 文件,里面编写 sys_iam、sys_whoami 函数,并修改对应的 Makefile 文件将 who.c 添加到内核中;在
hdc 文件系统上,在 /usr/include/unistd.h 中添加 __NR_xxx xx,然后编写 iam.c whoami.c(在文件中使用 _syscall1、_syscall2 宏展
开)。完成后,编译内核后运行 bochs 虚拟机,可以在 bochs 虚拟机上直接 gcc 编译 iam.c、whoami.c,最后可以成功运行。linux 源
代码中的 /include/unistd.h 和 hdc 文件系统上的 /usr/include/linux/sys.h 都不修改,也可达到跟实验中完整编写代码完全相同的效果。
在真正通过0x80触发系统调用前,程序都在用户态。
只有程序运行时,才会跟内核代码进行动态链接。因此,即使内核代码修改了,在虚拟机中的gcc也是识别不到的,gcc只识别文件系
统hdc-0.11.img上的各种库文件头文件,没有就报错。
由于静态链接库lib.a存在于我们编写的源码中而不存在于硬盘挂载的文件系统中,我们手动地将API函数放置在用户空间中强制与
测试函数连接在一起就可以解决问题。
我倒是想起了一套逻辑----用户程序、C函数库、系统调用、内核函数、驱动、设备。似乎编辑源码只实现了
C函数库后面的逻辑。可这不应该呀!理论上来讲
不需要那么麻烦。哈哈!我在圈子里边,看不到外边。
12.9、本次实验用到的shell命令:
vi创建并编辑文件
ESC进入命令模式
dd 删除一整行
x 删除光标所在的字符
a 进入编辑模式,插入的字符在光标所在字符后面
A 进入编辑模式,插入的字符在光标所在行尾
i 进入编辑模式,插入的字符在光标所在字符前面
less查看文件
q 退出
u 向前半页
y 向前一行
空格 滚一页
回车 滚一行
12.10、测试文件及结果
测试文件
test_iam.c
#include <stdio.h>
#define __LIBRARY__
#include <unistd.h>
_syscall1(int,iam,const char *,name);
int main() {
char name[10] = "LiChangHe";
int ret = iam(name);
printf("System call return value: %d\n", ret);
return 0;
}
test_whoami.c
#include <stdio.h>
#define __LIBRARY__
#include <unistd.h>
_syscall2(int,whoami,char *,name,unsigned int,size);
int main() {
char name[10] = "";
int ret = whoami(name,10*sizeof(char));
printf("System call return value: %d\r\n", ret);
printf("value: %s\r\n",name);
return 0;
}
iam系统调用测试:
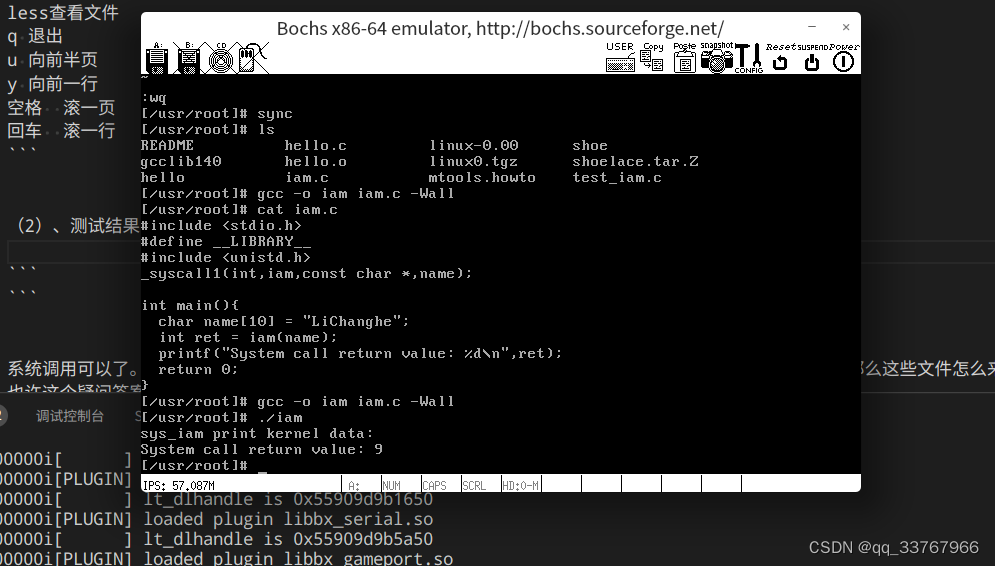
执行完发现: 返回大小没有问题,可内核没有打印数据。
原来的逻辑:用户空间获取数据,存入局部变量,最后存入全局变量。
现在,我去掉局部变量,直接用全局变量。
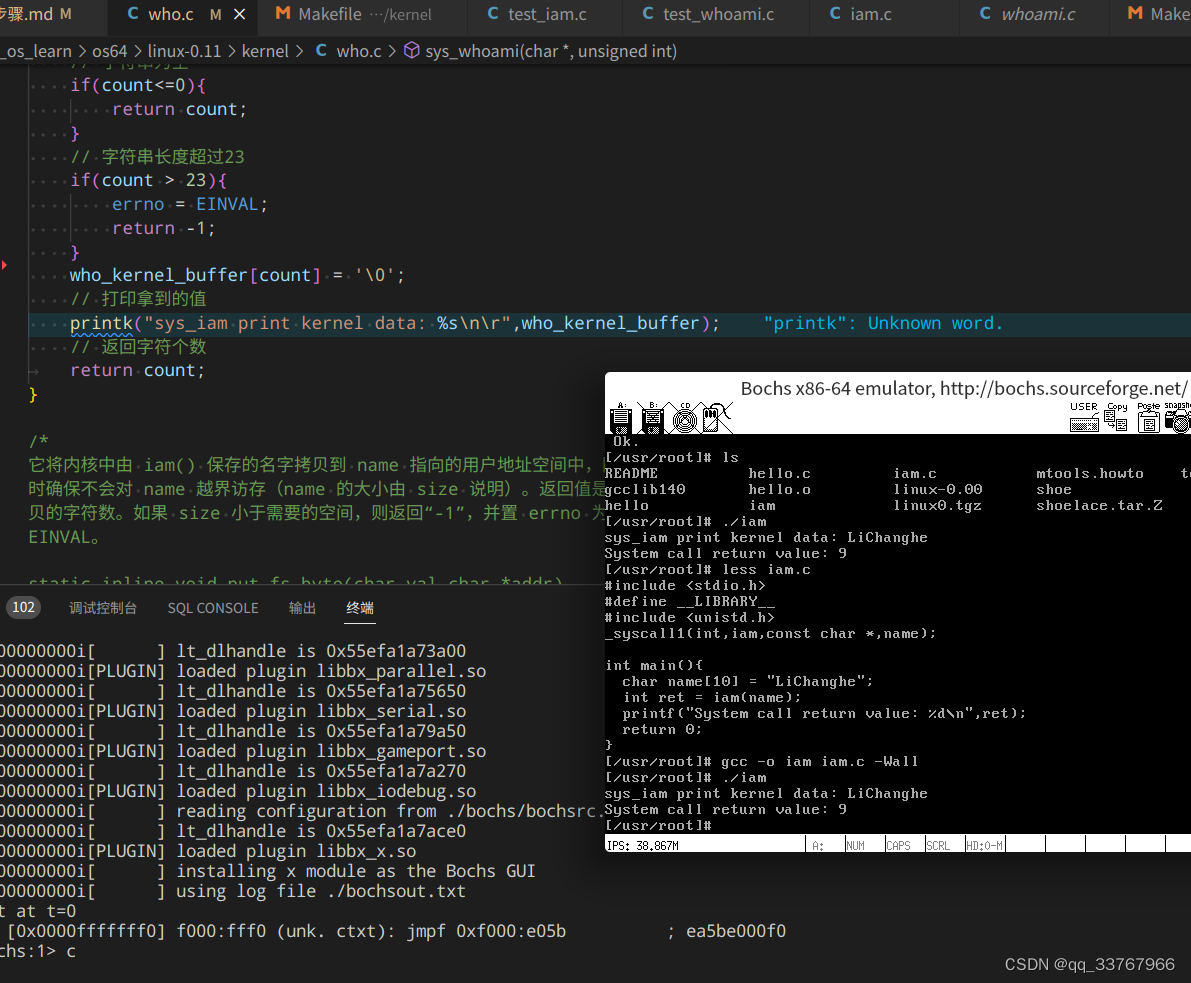
成功了… ???
whoami系统调用测试:
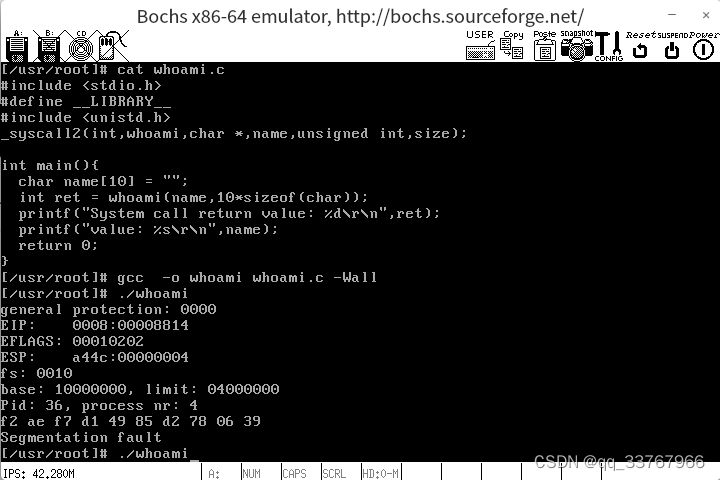
原来的逻辑:printk直接打印name字符串(用户空间数据,内核只能操作内核空间数据)。
修改后:
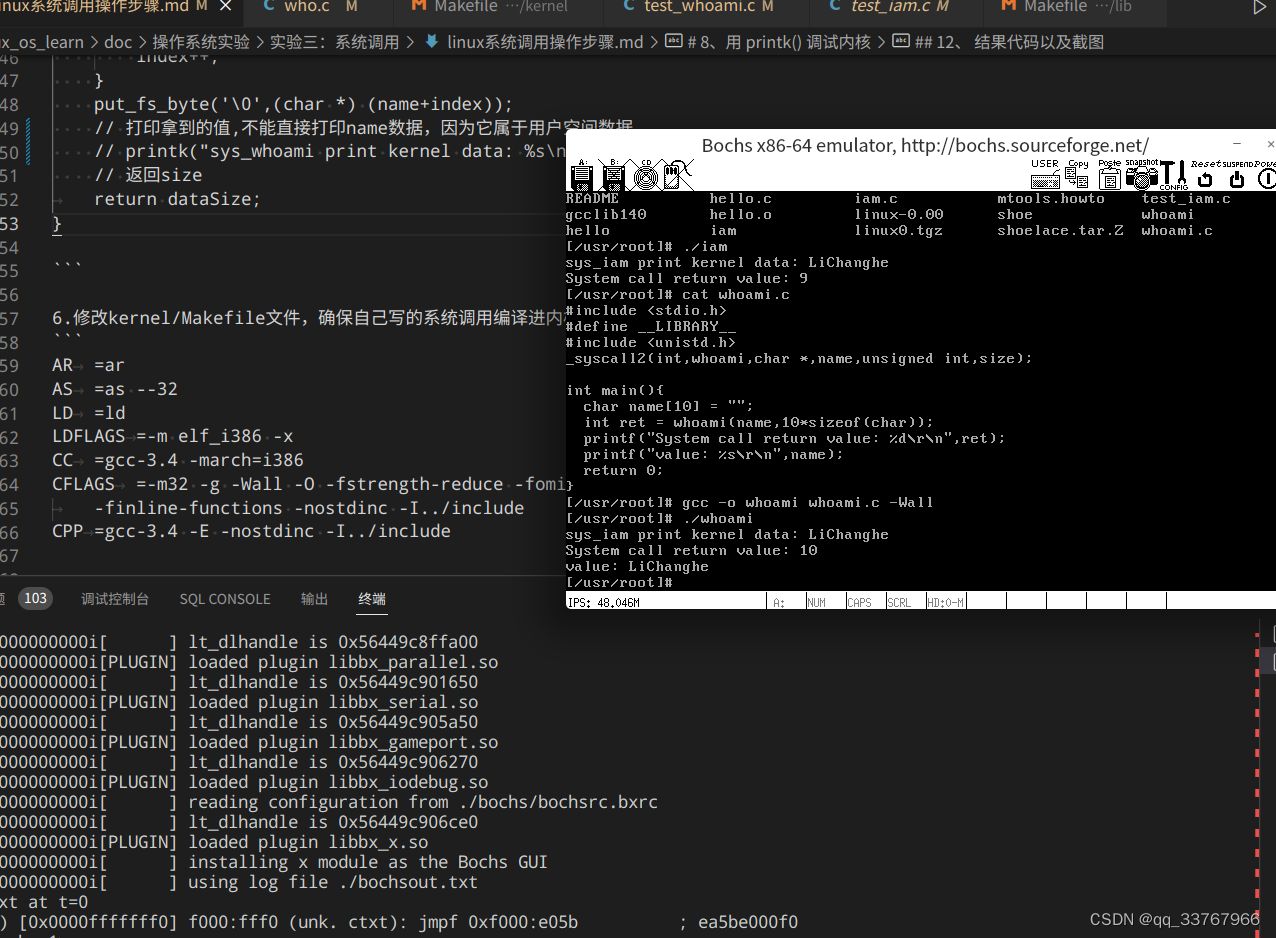
系统调用可以了。可在这一过程中,我又有好几个疑惑。
1、运行linux0.11系统,我发现里边有一些默认文件,那么这些文件怎么来的呢?
也许这个疑问答案应该在文件系统那里。
2、为什么内核用局部变量周转时,printk会有问题?
三、总结
为了添加系统调用。我在include/linux/unistd.h定义系统调用号以及用户接口函数名称。接着,在lib目录下创建一个文件并在其中实现用户空间接口函数(类似lib/close.c)。接着,在include/linux/sys.h这里,extern内核接口函数名称, 同时将该内核接口函数名称添加到了系统调用表(sys_call_table)里边。接着,在include/system_call.s这里,修改nr_system_calls数值。然后,实现在sys.h定义的内核接口函数。最后,修改makefile文件,将我的代码编译合并进内核。
运行进入linux0.11系统后,我们需要修改/usr/include/unistd.h文件,让它跟我们在源码里文件保持一致。接着,创建编译iam.c,whoami.c测试文件。最后,按顺序运行iam,whoami可执行文件。
在这一过程,自身建立了对系统调用接口的深入认识,掌握了系统调用的基本过程,完成了系统调用的全面控制,为后续探究学习打下了基础。















 3478
3478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









