







本周的主要工作是研究这篇论文,理解其中的风格迁移模型的结构和原理:
论文原文 https://arxiv.org/pdf/1603.08155v1.pdf
style transfer是ill-posed的问题,styletransfer there is no single correct output
这篇论文:
One approach for solving imagetransformation tasks is to train a feedforward
convolutional neural network in asupervised manner, using a per-pixel
loss function to measure the differencebetween output and ground-truth images.
目前做风格迁移有两种路线,一种是监督学习的方式,使用per-pixel losses,训练反馈转换网络,per-pixel losses有一个问题就是Image offset的问题;另一种是使用perceptual loss functions,based on differencesbetween high-level image feature representations extracted from pretrainedconvolutional neural networks. Images are generated by minimizing a lossfunction.这种方式产生的图像质量高,但是速度很慢
本文加了一个前置的生成网络,用前置网络来做图片生成,再利用pretrained VGG-16来计算Loss,梯度更新生成网络的参数。最后就会得到一个深度学习“滤镜”网络。只需要一次向前传播就可以生成要的图片。
训练的时候,风格转移的loss和Gatys.相同通过和C, G来计算,超清化任务的loss就是一张低清图和高清图的Content Loss。
这个前置网络的设置用了不少流行的技巧。取消池化,用3x3的小kernel(除第一层和最后一层),先使用stride 2 downsample,然后是五个残差块(这里的残差块好像不是He的版本),再用stride 1/2 upsample(fractionally convolution)。因为增大了感受野,在相同计算代价的前提下可以做一个更深的网络,获得更强的描述能力。最后一层用tanh来缩放到0-255。
最后的Loss函数还加了一个一个Total Variation Regularization(相邻像素的差值),用来平滑优化视觉结果。
最后的loss:

(这个网络里用的是批归一化,后来作者有一篇Instance Normalization: The Missing Ingredient for Fast Stylization,论述IN比BN更适合图像生成任务。)
在Style Transfer的任务上,把优化过程,变成一个单次的生成过程。据原论文来说,在生成效果类似的前提下,有三个数量级的提速。
前置网络模型如下图:
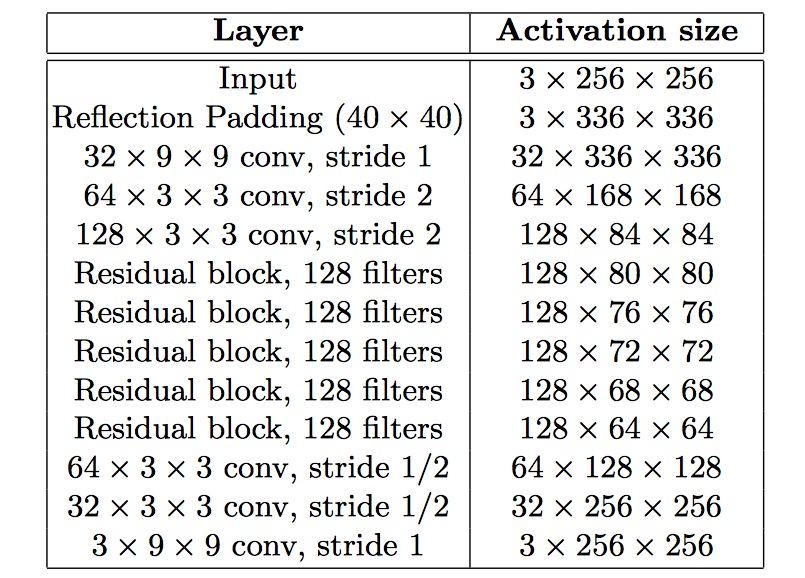
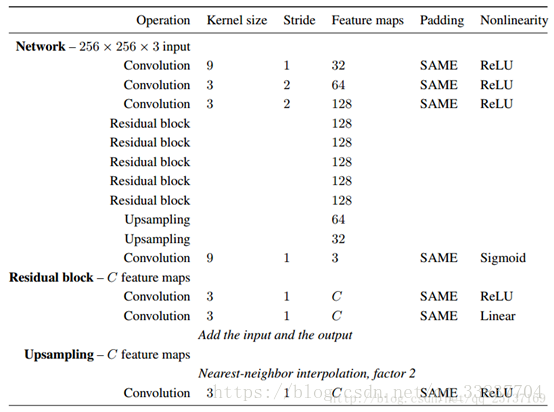
整体网络模型:
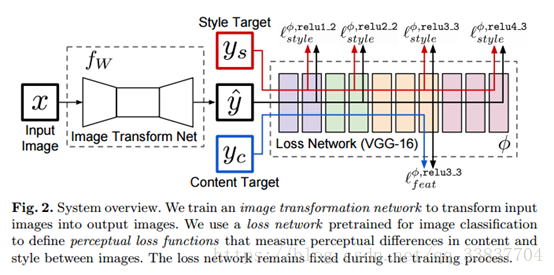
只是看论文的话,理解不会那么深刻。为了实现风格转换功能,准备使用tensorflow实现这篇论文。下面就记录一系列的实现过程。














 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









