






selenium的八种元素定位方式有:id、name、class_name、tag_name、link_text、partial_link_text、xpath、css_selector。
1、id 定位
id是唯一的。
用法:只有当需要定位的元素有id属性时才能使用(动态的id,也不能使用)
排错(定位时可能出现的错误):
1、NoSuchElementException #定位元素名称写错
2、'list' object has no attribute 'get_attribute' #原因:写成了复数定位find_elements
例子:使用id来定位百度页面的搜索框。
from selenium import webdriver
import os
import time
driver = webdriver.Chrome() #打开浏览器
driver.get('http://www.baidu.com') #打开网址
time.sleep(3)
# url = "file:///"+os.path.abspath("路径") #当前文件夹里的文件的路径
search = driver.find_element_by_id('kw')
search.get_attribute('outerHTML')
print(search.get_attribute('outerHTML')) #查看元素对应的源码
# print(search)
driver.quit() #关闭浏览器
结果:显示搜索框对应的源码

2、name 定位
3、class_name 定位
name 和 class_name 不是唯一的,可能重复。
用法:只有当需要定位的元素有name、class属性时才能使用(动态的name,也不能使用)
例如:使用name 和 class_name 来定位百度页面的搜索框。
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
time.sleep(2)
#使用name 定位
search_1 = driver.find_element_by_name('wd')
print('使用name定位:',search_1.get_attribute('outerHTML'))
#使用class_name 定位
search_2 = driver.find_element_by_class_name('s_ipt')
print('使用class_name 定位:' + search_2.get_attribute('outerHTML'))
driver.quit()
结果:

4、tag_name 定位
使用单数形式的driver.find_element_by_tag_name()时,默认只找第一个。
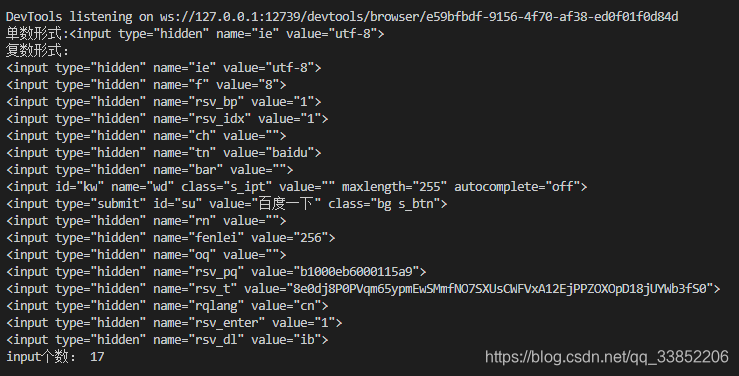
例如:查找百度页面上的input标签,列出每个input对应的源码,并计算共有几个input标签。
from selenium import webdriver
import time
driver = webdriver.Chrome()
url = 'http://www.baidu.com'
driver.get(url)
time.sleep(3)
input_ele = driver.find_element_by_tag_name('input')
print('单数形式:'+ input_ele.get_attribute('outerHTML'))
input_eles = driver.find_elements_by_tag_name('input')
print('复数形式:')
#遍历
for input in input_eles:
print(input.get_attribute('outerHTML'))
print('input个数',len(input_eles)) #计算有几个input
driver.quit()
结果:
5、link_text 定位
6、partial_link_text 定位
通常用于定位链接。
by_link_text() #需要知道完整的超链接文本
by_partial_link_text() #只需要知道部分文本内容,但是这些内容必须是连续的
例如:定位百度页面的“新闻”和“hao123”链接。
from selenium import webdriver
import time
driver = webdriver.Chrome()
url = 'http://www.baidu.com'
driver.get(url)
input_news = driver.find_element_by_link_text('新闻') #定位“新闻”链接,文本内容必须是完整的
print('"新闻"链接的源码为:',input_news.get_attribute('outerHTML'))
input_hao123 = driver.find_element_by_partial_link_text('123') #文本内容可以是部分的,但必须连续,不可写13
print('"hao123"链接的源码为:',input_hao123.get_attribute('outerHTML'))结果:

7、xpath 定位
'''
1.绝对路径:
/ 表示绝对路径
/html/body/form/div/fieldset/p/input
2.相对路径(重点):
// 表示相对路径
1、标签+属性定位:
//标签名[@属性名='属性值']
2、层级定位:
元素没有属性时,就只有一个标签时,可以通过上一级标签进行定位
//父标签[@父标签属性名='父标签属性值']/子标签名
注意:层级定位不仅限于2层,可以是多层的
3、索引
当一个父标签下有多个相同子标签时:
//父标签[@父标签属性名='父标签属性值']/子标签名[索引]
Xpath索引从1开始,定位第一个子标签时可以不加索引值
4、逻辑
当元素属性与其他元素属性有相同部分时,不能只用一个属性定位,需要多个元素属性进行定位 and
and or not
//标签名[@属性名1 ='属性值1' and @属性名2 = '属性值2' and ....]
5、模糊匹配
//标签名[contains(@属性名,属性值/部分属性值)]
用法:当常用定位方法无法使用时,可使用Xpath定位方法
'''
例如:使用xpath定位百度页面的搜索框或者form下的第二个input。
from selenium import webdriver
import time
driver = webdriver.Chrome()
url = 'http://www.baidu.com'
driver.get(url)
#绝对路径定位
input_absPath = driver.find_element_by_xpath('/html/body/div/div/div[5]/div/div/form/span/input')
print('绝对路径定位',input_absPath.get_attribute('outerHTML'))
#相对路径定位
#1、标签+属性名
input_name = driver.find_element_by_xpath('//input[@name="wd"]')
print('使用标签+属性名name 定位',input_name.get_attribute('outerHTML'))
#2、层级定位
input_Hierarchical = driver.find_element_by_xpath('//form[@id="form"]/span/input')
print('使用层级定位',input_Hierarchical.get_attribute('outerHTML'))
#3、索引定位
input_index = driver.find_element_by_xpath('//form[@name="f"]/span/input[1]') #索引1可以不写,定位搜索框
#input_2 = driver.find_element_by_xpath('//form[@name="f"]/input[2]') #定位form下第二个input
print('使用索引定位',input_index .get_attribute('outerHTML'))
#4、逻辑定位 and 要写
input_2 = driver.find_element_by_xpath('//input[@type="hidden" and @name="f"]') #定位form下第2个input
#and要写,属性名前要写@,且只有一个[],注意与css_selector的逻辑定位区分
print('使用逻辑定位',input_2.get_attribute('outerHTML'))
#5、模糊匹配
input_vague = driver.find_element_by_xpath('//input[contains(@class,"ipt")]') #定位搜索框,注意:contains[] 且属性名和属性值之间是,
print('使用模糊匹配',input_vague.get_attribute('outerHTML'))
driver.quit()
结果:

8、css_selector 定位
'''
1、id、class属性:
# 表示id属性
. 表示class属性
2、其他属性
[属性名=属性值]
3、标签+属性
标签名[属性名=属性值],若标签名唯一,则也可以不写标签名
4、层级定位
父标签[父标签属性名=父标签属性值]>子标签 >也可以换成空格
5、索引
语法:
父标签[父标签属性名=父标签属性值]>:nth-child(索引值)
nth-child(索引值):表示包括父标签下的所有子标签顺序值 #索引值从1开始
例如:
父标签[父标签属性名=父标签属性值]>p:nth-of-type(索引值)
p:nth-of-type(n):表示父标签下第n个索引值的p标签
6、逻辑(and)
标签名[属性名1=属性值1][属性名2=属性值2] #中间不需要and
7、模糊匹配
^ 表示以...开头
$ 表示以...结尾
* 匹配所有 #记住*即可
标签名[属性名*=部分属性值]
'''例如:使用css_selector 定位百度页面的搜索框
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#id 定位
input_id = driver.find_element_by_css_selector('#kw')
print('使用 id 属性:',input_id.get_attribute('outerHTML'))
#class定位
input_class = driver.find_element_by_css_selector('.s_ipt')
print('使用 class 属性:',input_class.get_attribute('outerHTML'))
#name定位
input_name = driver.find_element_by_css_selector("input[name='wd']")
print('使用其他 name 属性',input_name.get_attribute('outerHTML'))
#层级定位
input_Hierarchical = driver.find_element_by_css_selector('form.fm>span input') #看别人解释是说由于span是内联函数,所以要定位到它所在的模块(上一级)
print('使用层级定位',input_Hierarchical .get_attribute('outerHTML'))
#索引定位
input_index = driver.find_element_by_css_selector('form.fm span>:nth-child(2)') #由于span是内联函数,所以要定位到它所在的模块(上一级)
#或者 input_index = driver.find_element_by_css_selector('form.fm span input:nth-of-type(1)')
print('使用索引定位',input_index.get_attribute('outerHTML'))
#使用逻辑关系定位
input_logic = driver.find_element_by_css_selector('input[maxlength="255"][autocomplete="off"]') #中间不需要and
print('使用逻辑多个属性定位',input_logic.get_attribute('outerHTML'))
#使用模糊匹配
input_vague = driver.find_element_by_css_selector('input[class*="s"]')
print('使用*模糊匹配定位',input_vague.get_attribute('outerHTML'))
driver.quit()
结果:

以上归纳了selenium的八种定位方式,有不对的地方,欢迎批评指正。
其中有一点还是不太明白,就是有关定位span的问题,虽说span是内联函数,在进行定位是,需要找上一级,可是如下例所示,如果想通过层级或者索引方式定位,上一级还是span为什么又可以呢?而且定位时只写一个span为什么也可以??然而前面利用css_selector方法定位百度页面搜索框时又会报错,求大神解答。
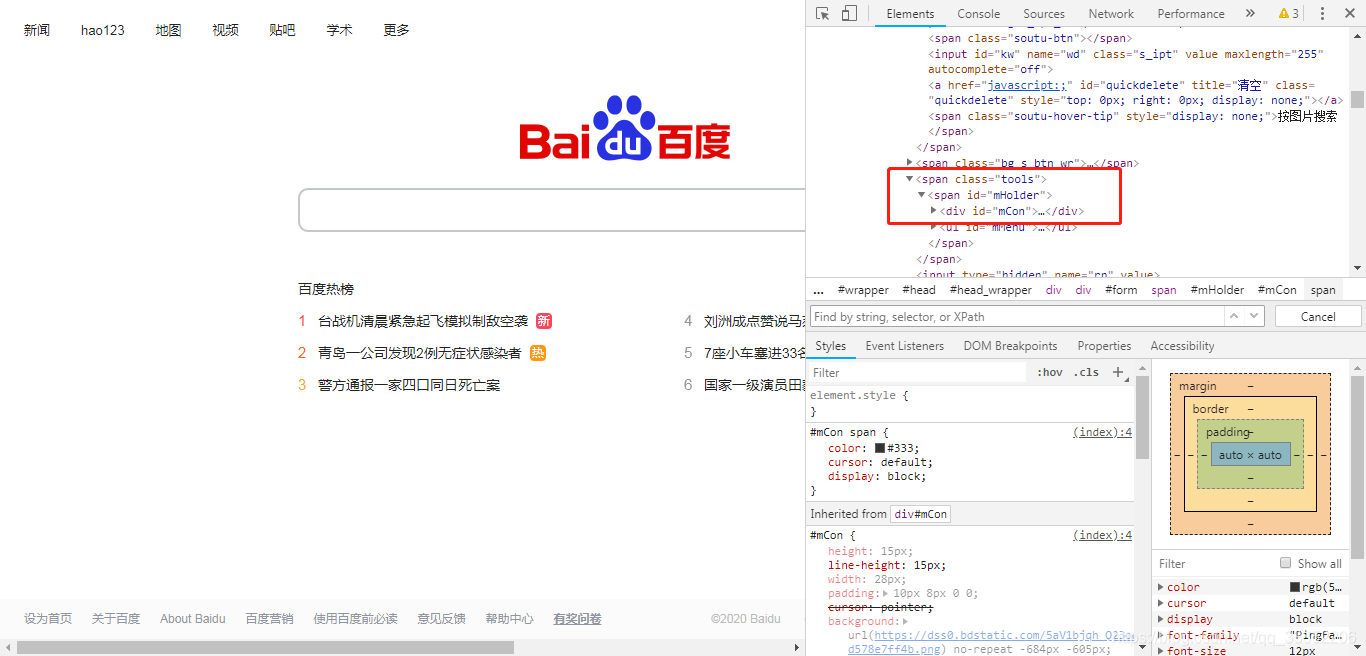
div = driver.find_element_by_css_selector('span.tools span :nth-child(1)') #class定位
div = driver.find_element_by_css_selector('span#mHolder :nth-child(1)') id定位
span1 = driver.find_element_by_css_selector('span.tools')
span2 = driver.find_element_by_css_selector('span.tools span')
print('使用索引定位',div.get_attribute('outerHTML'))
print('使用索引定位',span1.get_attribute('outerHTML'))
print('使用索引定位',span2.get_attribute('outerHTML'))结果(为什么没有报错?):

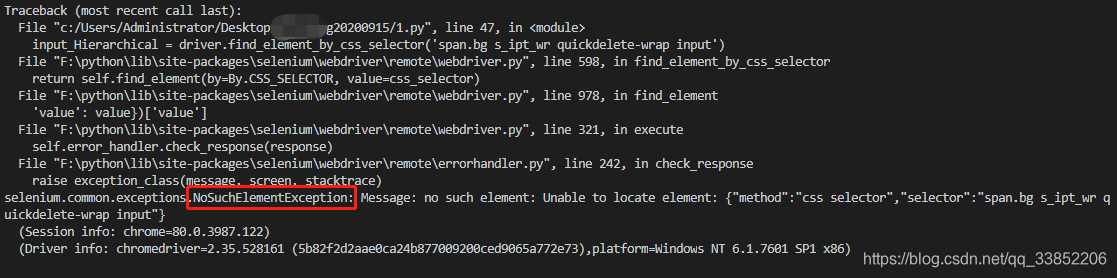
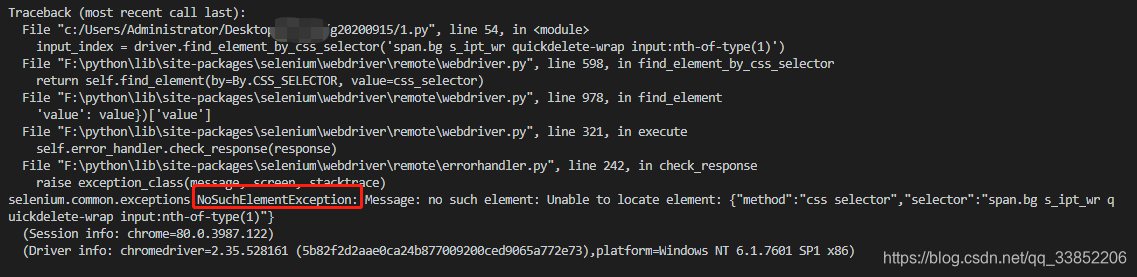
而前面我在css_elector中的索引定位,和层级定位中如果不加form是会报错的,如下。
#层级定位
input_Hierarchical = driver.find_element_by_css_selector('span.bg s_ipt_wr quickdelete-wrap input')
print('使用层级定位',input_Hierarchical .get_attribute('outerHTML'))
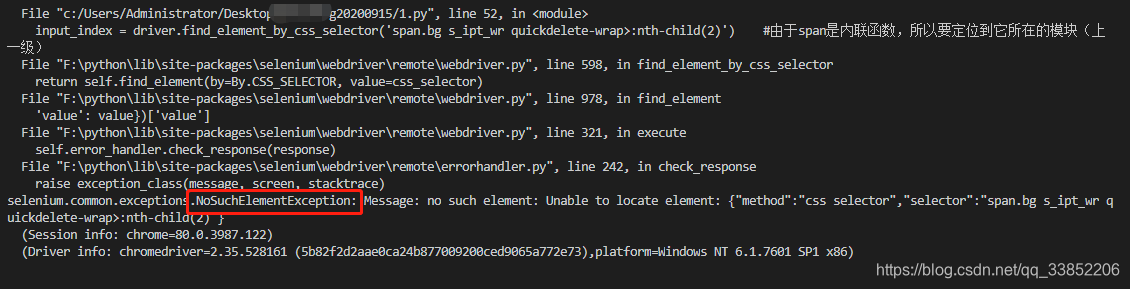
#索引定位
input_index = driver.find_element_by_css_selector('span.bg s_ipt_wr quickdelete-wrap>:nth-child(2)') #由于span是内联函数,所以要定位到它所在的模块(上一级)
#或者 input_index = driver.find_element_by_css_selector('span.bg s_ipt_wr quickdelete-wrap input:nth-of-type(1)')
print('使用索引定位',input_index.get_attribute('outerHTML'))层级报错如下:
索引报错如下:

















 4563
4563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









