







Abstract
本文提出了一个新的视觉基准系统,采用二维码标志,可以从图像中得到6自由度定位结果。我们所提出的鲁棒的数字系统,通过快速且鲁棒的线检测,能够对镜头的遮挡、扭曲和变形,有更鲁棒的结果。
Introduction
视觉基准系统提供的标签,与相机的相关位置和方向有关。视觉基准系统也可以用来进行运动捕捉。
本文提出了一个新的视觉基准系统,能够显著提升精度,主要contribution:
- 提出了一个鲁棒的视觉基准点检测方法。提出了一个基于图的图像分割方法,从而能够对点进行更加精准的估计;此外,本文还描述了一种能够处理显著遮挡的四元提取方法;
- 与已有的系统相比,证明了本文的检测系统更加精准的定位精度;
- 提出了一个新的编码系统来解决二维条码系统的这些问题,对旋转更加鲁棒,对自然因素引起的误报更加鲁棒。实验结果表明,编码系统在理论和实践中具有更多的益处;
由于其他系统的封闭性,对于实验的比较和评价相对困难。本文搜集了现有公开资源,并提供了测试代码,方便未来的研究者进行方法的比较。
本文的方法主要包括:标记检测、编码系统。以及一些实验比较和评价。
Previous Work
ARToolkit是第一个标签追踪系统,主要应用在AR中。该方法的编码拟采用诸如拉丁字符“A”之类的符号,解码时与已知的标签数据库关联。该方法的主要缺点是:1)每个模板都需要单独计算,操作速度慢;2)难以生成彼此正交的模板。ARToolkit的标签检测系统基于输入图像的简单阈值二值化。该方法运算速度快,但对光线较为敏感。并且,ARToolkit对遮挡问题不友好。
ARTag提供了对检测和编码提升的方法:检测基于梯度,从而方法对光线鲁棒;该方法能够检测有遮挡的边界。ARTag也提供了第一个基于前向错误校正的编码系系统,标签易于产生、快速校正、标签间正交。
相比于基于LED的系统,二维的平面系统更易于打印,且能够提供6自由度的位置估计,而不需要很多LEDs设备。
Detector
系统由标签检测器和编码系统组成。检测器的作用是估计标签在图像中的位置。探测器用于找到内部比外部暗的四边形区域。四边形检测器必须具有极低的假阴率,从而会有很高的假阳率。本系统采用编码系统来减少False Positive Rate。
A. Detecting line segments
方法的核心是检测image中的线。计算每个像素点的梯度方向和大小,并将相似梯度方向和大小的像素进行聚合:

聚合算法与graph-based方法Felzenszwalb相似:创建图,每个图的节点代表每个像素。相邻的像素点会添加边,边的权重就等于像素的梯度方向差异。这些边随后被排序:对每一条边,判断被该边相连的像素点是否应该连结在一起。
n表示像素点集,表示梯度方向,表示梯度大小。给定两个点集n和m,连结策略如下:

和的较小值表示集合内部变化较小。如果两个集合的并集与单个集合的并集大致相同,则将两个簇连结在一起。集合的内部变化通过和进行计算。在早期迭代中,K参数允许每个组件“学习”其集群内部的变异。我们的实验中,设置=100,=1200。
出于性能原因,边缘权重被量化并存储为定点数字。unionfind算法可以有效地执行实际合并操作,梯度方向和幅度的上下界存储在一个简单数组中,该数组由每个组件的代表成员索引。
该基于梯度的聚类方法对噪声非常敏感,即使是少量的噪声点也会造成局部梯度方向发生变化,抑制组件的生长。解决方法是采用低通滤波(low-pass filter)。这个滤波器会模糊有效的信息。而标记的边缘本质上是大规模特征(尤其是与数据字段相比),因此该方法不会造成信息的丢失。本文中σ=0.8。
聚类操作完成后,使用传统的最小二乘法将线段拟合到每个连接的组件上,通过其梯度大小对每个点进行加权,如上图Fig3所示。
分割算法是本文检测算法中最慢的一个环节。当图像分辨率下降一半时,速度可以提升4倍,但如此操作,小的四边形区域可能不会被检测到。
B. Quad Detection
在此,我们计算了图像的一系列方向线段,下一步就是寻找能够组成四边形的线段。难点在于对噪声和遮挡进行正确的划分。
我们的方法基于递归的深度优先搜索算法,深度为4:搜索树的每个层级都会向四边形添加一条边。在深度1时,我们考虑所有的线段;深度2时,我们考虑与层级1中足够近邻的线段,并且遵循逆时针的缠绕顺序;鲁棒性和分割的错误率通过“close enough”阈值来控制,阈值越大,对大的gaps的边处理更好。
“close enough”的阈值是线条长度的两倍加上五个额外像素,从而待了低的假阴率,但带来了高的假阳率。我们填充二维查找表,以加速对从空间中某个点附近开始的线段的查询。通过这种优化,以及早期拒绝不遵守缠绕规则或多次使用线段的候选四边形,从而四边形检测算法只占总计算需求的一小部分。
检测出四条线段,则一个候选四边形区域就被创建了。由于线段是由像素点拟合而来,这些corner的估计精确到像素点的一小部分。
C. Homography and extrinsics estimation
我们计算一个3×3的单应性矩阵,通过标签坐标系统,能够将2D的点投影到homogeneous坐标系统中。单应性矩阵通过直接线性变换(DLT)得到。
计算标签的位置和方向还需要额外信息:相机的焦距和标签的物理尺寸。3×3的单应性矩阵可以写为:的相机投影矩阵和外参矩阵。一般来说,外参矩阵为4×4矩阵,但是二维标签上的每一个点在z方向上都为0,从而我们就可以重写标签坐标。Homogeneous矩阵计算如下:

其中,S是缩放尺度因子。展开以上公式:
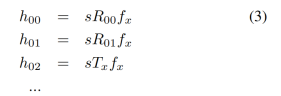
旋转矩阵必须具有单位梯度,因此我们计算两列旋转矩阵的几何平均值。
D. Payload Decoding
最后需要从有效负载字段读取内容。通过计算每个位场的标签相对坐标,使用单应变换将它们转换为图像坐标,然后对结果像素进行阈值化来实现这一点。为了对光照(光照不仅在标签之间变化,而且在标签内部也可能变化)具有鲁棒性,我们使用了一个空间变化的阈值。
我们建立了“black”像素的空间灰度模型。使用标签的边界,它同时包含了黑色和白色的像素,灰度模型如下:
![]()
该模型有四个参数(A, B, C, D),采用最小二乘法容易计算。建立两个模型,一个用于计算白色,一个用于计算黑色。解码阈值采用black和white模型预测值的平均值。
Coding System
当负载数据经四边形解码得到时,需要编码系统(Coding System)判定其是否有效。编码系统目的是:
- 最大化区分码数量;
- 最大化错误bit的数量;
- 最小化假阳率;
- 最小话每个标签上的bits;
以上目标本身常常矛盾,因此需要求得一个权衡。
A. Methodology
本文提出了一个改进的lexicode方法。经典的lexicode方法由两个数量参数化:每个codeword中的bits数量n和任何两个codewords之间的最小汉明距离 d。 Lexicodes方法可以纠正和检测 bit的错误。为方便起见,我们将最小汉明距离为10的36bit编码表示为36h10。
在视觉基准中,编码方案必须对旋转鲁棒。我们通过拒绝导致简单几何图案的候选codewords来进一步修改词法代码生成算法。参数基于需要生成的标签矩形数量。例如,纯色图案只需要一个矩形,而黑白条纹则需要两个矩形(一个大的黑色矩形,第二个绘制一个较小的白色矩形)。 我们的假设得到了本文后面的实验结果的支持,即具有高复杂性(需要重建许多矩形)的标签模式在自然界中出现的频率较低,从而导致较低的误报率。
我们使用重复的简单贪婪方法来近似生成标签模式所需的矩形数量,考虑所有可能的矩形并添加最能减少误差的矩形。由于标签通常非常小,因此这种计算不是瓶颈。最小复杂度小于阈值(在我们的实验中通常为10个)的标签被拒绝。
最后,我们通过对词法代码生成算法进行再一次修改,凭经验观察到较低的误报分数。我们不是按顺序测试codewords(0, 1, 2, 3, ...),而是考虑 (b, b+1p, b+2p, b+3p, ...),其中b是任意数字,p是一个大素数,每一步都保留最低的n位。直观上,这种方法生成的标签在每个比特位置都有更大的熵;另一方面,字典顺序有利于商场价值的代码。这种方法的缺点是创建的可区分代码较少:字典排序倾向于非常密集地打包代码字,而更随机的顺序导致代码字打包效率较低。
我们使用的lexicode系统,能够产生任意尺寸(eg. 3×3, 4×4, 5×5, 6×6)和最小的汉明距离。我们的方法明确保证了每个标签的所有四次旋转的最小汉明距离,并消除了几何复杂度低的标签。标签计算的代价比较高。较小的标签(如5×5)能够在短时间内计算出来,大标签(6×6)就需要几天时间来计算。
B. Error correction analysis
理论上,假阳率是比较容易评估的。误报的概率是被接受为有效标记的codewords与可能的codewords总数的比例。更积极的错误纠正会增加这一比率,因为它增加了接受codewords的数量。
当然,36h15编码的更好性能是有代价的:只有27个可区分的codewords,与36h10的2221个可分辨codewords相反。
我们的编码方案更加鲁棒,我们的系统在所有成对的codewords中,实现了更小的汉明距离,且编码了大量的可区分ID。
为了编码一个可能失败的codeword,当前的codeword与所有标准有效的codeword的汉明距离进行计算。如果最匹配的汉明距离低于预设的阈值,则该codeword被检测出来。通过调整阈值,用户可以控制假阳率和假阴率。
本文方法的一个缺点是:解码过程的花费时间与codebook的大小成正比,因为每一个有效的codeword都要被考虑到。该方法的算法复杂度较低。
对于给定的编码方案,标签越大,编码效果越好。在所有其他条件相同的情况下,给定相机可以读取36位标签的范围将短于同一相机可以读取16位或25位标签的范围。然而,由于边界的4像素开销,较小标签在范围内的好处相当有限;通过使用16位标签而不是36位标签,可以预期检测范围仅提高25%。因此,只有在范围最敏感的应用中,较小的标签才是有利的。
Experimental Results
A. Empirical Experiments
待验证的核心问题是:理论分析的降假阳方法在实际中是否起作用。作者采用了一个图像数据库:LabelMe Dataset。
Evaluation of complexity heuristic: 为了评估假设:假阳率能够通过我们的几何复杂性启发式算法拒绝候选codewords而降低。我们产生了25h9 family,复杂度1~10,下图给出了每种复杂度的误报率,作为最大纠正误码数的函数:

从上图可以看到,启发式算法对降低假阳率非常有效。
Comparision to other coding schemes: 比较本文的编码系统于ARToolkitPlus、ARTag编码系统对假阳率的影响。采用相同的数据集进行实验,结果如下图所示:

B. Localization Accuracy
影响定位精度的主要原因是:目标的尺寸,其受标签的距离和方向影响。本文将两者因素进行分离,固定变量进行实验。固定距离,进行角度的实验:

随着角度的变大,检测率下降,误差增大;本文方法明显优于ARToolkitPlus。
固定角度,进行距离实验:

角度固定情况下,随着目标距离的增加,检测精度下降,错误率变大。本文方法明显优于ARToolkitPlus。本文算法的计算量相比于ARToolkitPlus更大。
Conclusion
本文描述了一个改进的视觉基准系统。通过coding system,并基于图聚类的方法,进行边缘检测,获得了更加鲁棒和精准的结果。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









