







 这篇博客深入介绍了MySQL数据库的各个关键概念,包括phpstudy的目录结构、数据类型、SQL语句规则、存储引擎、安全性设置、索引、用户管理、触发器以及日志系统。内容涵盖从基础到进阶的各个方面,是MySQL学习者的实用指南。
这篇博客深入介绍了MySQL数据库的各个关键概念,包括phpstudy的目录结构、数据类型、SQL语句规则、存储引擎、安全性设置、索引、用户管理、触发器以及日志系统。内容涵盖从基础到进阶的各个方面,是MySQL学习者的实用指南。
该篇写的偏理论,点击查看常用指令
phpstudy的mysql目录介绍
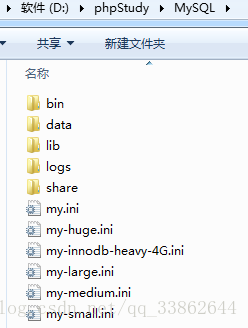
1、bin //可执行文件
2、data //数据库
3、lib //扩展库,一般用不到
4、logs //日志
5、share //系统需要的东西,如 编码啥的
6、my.ini //配置文件。linux上是my.cnf
剩余的ini文件也都是配置文件,只是针对的服务器配置不同而已,如 my-smail.ini是针对内存小于64M用的,用法如下:
假如你的服务器配置小于64M,将my-smail.ini文件改名为my.ini,然后将其他的配置文件删除即可
*默认路径:/usr/local/mysql/var
mysql> show variables like 'general_log_file'; #日志文件路径
mysql> show variables like 'log_error'; #错误日志文件路径
mysql> show variables like 'slow_query_log_file'; #慢查询日志文件路径
7、https://www.cnblogs.com/songanwei/p/9167326.html #使用了哪个配置文件
sql语句的书写规则:
1、以分号结尾 可以用delimiter修改
2、不区分大小写
3、#或--注释
位、字节、字符(计量单位)的关系:
| 位 | 字节 | 字符(多字节) | |
| 英文、数字 | 8 | 1 | 1 |
| 汉字gbk编码 | 8 | 2 | 1(gbk中2个字节是1个字符) |
| 汉字utf8编码 | 8 | 3 | 1(uf8中3个字节是1个字符) |
mysql数据类型介绍:
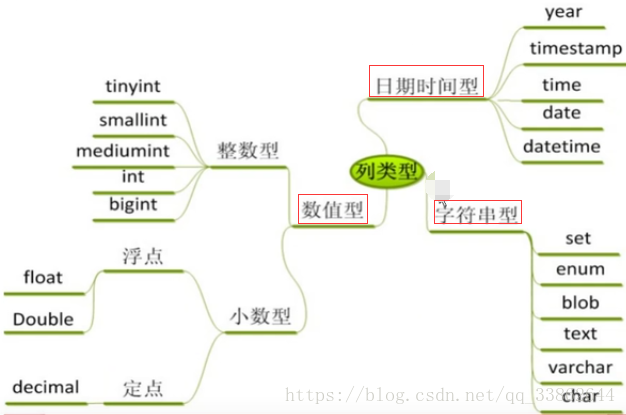
整数型:
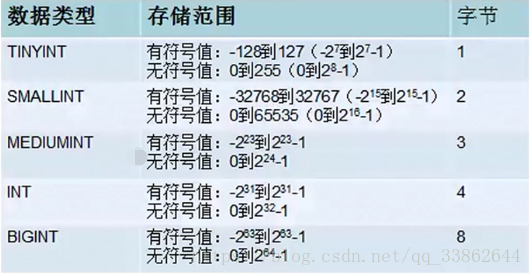
注意:有符号是从负数开始存,无符号是从正数0开始存;超过了最大值以最大值为准

注意:单双精度会四舍五入,和钱沾边的用decimal
字符串
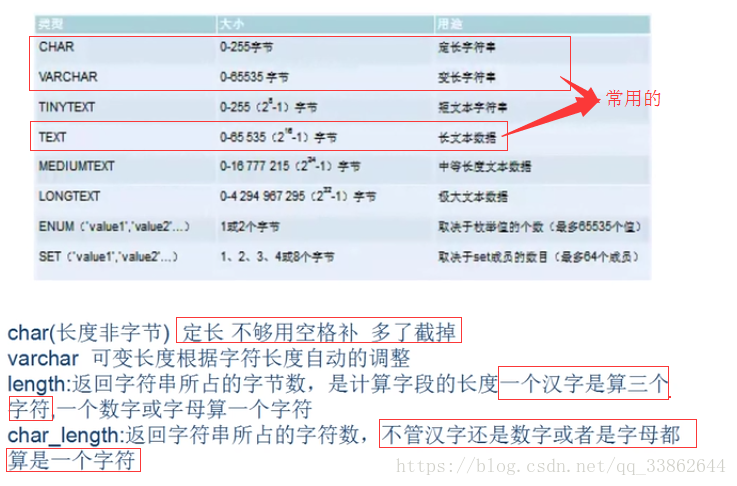
注意:
1、括号里的是长度是字符。select char_length(name) from tp5_user; //该字段中,字符串所占的字符数
2、char 读写速度快,因为他在内存中是按快找,缺点 浪费内存,因为存的不够会自动补空格
时间日期

*datetime的默认值是 '1970-01-01 00:00:00'
*timestamp的默认值是0,详见 https://blog.csdn.net/qq_29726869/article/details/81192679
字段的其他修饰关键词:
1、unsigned #无符号
2、auto_increment #自增
3、default 默认值 #给默认值的,如 价格默认0.00。不写 默认为null
4、comment '' #字段说明(注释)
5、not null #不能为空
6、null #可以为空
7、unique #唯一索引(对该列数据进行唯一性效验,插入重复的值会报error:Duplicate entry '123' for key 'user_name')
8、key 或 index #普通索引
9、primary key #主键索引

注意:
1、一般auto_increment 和 primary key是一对,在一起不分离 主键索引才自增
主键索引才自增
2、全文索引用的是MyISAM引擎,只支持英文
3、外键索引语法:foreign key (b表字段名) references a表(外键字段名)
如 a(外键)表是学生表,b(本)表是成绩表。
作用:a表中如果没有该id,b表插入不进去,保持了数据的一致性,如果想要删除a表中的数据,也是无法清空的,因为b表对a表有依赖性。
注意:数据不一致,俩个表的id数据不一致,就是b表中的id在a表中没有,会报1452;俩个id的数据类型、长度等不一致报1215
3.1、a表的id要和b表的user_id数据类型,有无符号,是否为空等完全一致。
速记:涉及数字加unsigned ,每列必加not null和commet ''
加索引的2种方式:1、在字段中加;2、所有字段书写完后统一加
SQL语句
sql语句中的运算符:
1、 = #2个意思,等于 或 赋值,系统会根据上下文判断
2、!= <> #不等于
3、< > <= >= #小于 大于 小于等于 大于等于
4、OR #或
5、AND #与
6、BETWEEN ... AND #在...之间(判断2-5范围,与的关系)
7、IN #在...之内(判断2,3,4,5范围,或的关系)
8、NOT IN #不在...之内
sql语句的分类:

线上服务器的安全:
1、不要用root连接
2、默认密码也修改掉(因为人家会用字典一个一个的破)
修改密码:去表中改
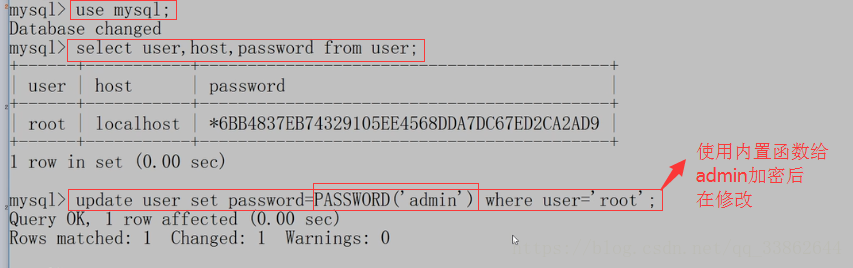
3、win的忘记密码:先停掉mysql
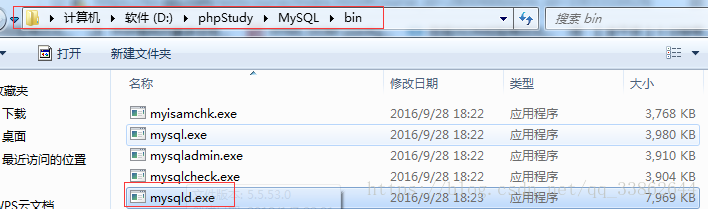
使用该命令,就不会查mysql自带的user表了,会给你开个新
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









