







Effective C++
前言
作者写这篇文章的目的就是将《Effective C++》中的内容精炼,由于是翻译书籍,有些地方也会用更加通俗易懂的解释方式来描述知识点。如果有哪些地方我理解的有问题欢迎大家指出我及时修正。
第一章:让自己习惯C++
条款01:视C++为一个语言联邦
这里主要将C++分成四个部分,每个部分都有各自的规则可能不同
1.C语言部分
2.Object-Oriented C++部分
3.Template C++部分
4.STL部分
总结
- C++高效编程守则视状况而变化,取决于使用C++的哪一部分,不要墨守成规,要视情况而定。
条款02:尽量以const,enum,inline替换#define
1.const替换#define
可以理解成用编译器替换预处理器,因为预处理器会盲目的进行宏替换,导致预处理后的代码中存在多份宏定义的值,若用const声明常量则不会出现相同的情况代码中只存在一份常量的值,如下:
#define PI 3.14
const float PI=3.14;
在指针使用const时需要注意,不变的是指针本身还是指针所指向的内容又或者是两者都不变。如下所示:
const int *p;指针指向的值为常量(地址内存储的数据为常量)
int *const p;指针本身为常量(地址为常量)
const int *const p;指针本身和他所指向的值都为常量
const取代的一个好处可以封装,#define并不能提供任何封装性;如果要将const声明的常量的作用域限制在class中,需要将该常量声明为static const,这样这个class中的常量才会只有一个实体,否则每次创建class都会声明一个const常量这样有违我们的初衷。如下:
class Test{
private:
static const int NUM=5;
int arr[NUM];
}
上面是典型的声明式而非定义式,只要不取NUM地址无需提供定义式,如果想取地址可以使用定义式如下:
class Test{//头文件
public:
static const int NUM;
int arr[NUM];
}
const int Test::NUM=5;//实现文件
2.enum替换#define
如果不想让别人获得常量的指针或者引用可以使用enum实现这个约束(取enum的地址不合法)。如下:
class Test{//头文件
public:
enum{NUM = 5};
}
3.template inline替换#define
template inline可以替换带参数的宏如下:
#define MIN(a,b) (((a)>(b))?(b):(a))
template
inline T inline_min(const T a,const T b)
{
return (a>b?b:a);
}
使用const,enum可以替换#define定义常量,使用inline可以替换#define定义带参数的宏(也有叫宏函数的),这几乎替换了大部分使用#define的情况。而#ifdef和#ifndef还扮演者重要角色。
总结
- 对于单纯的常量使用const和enum代替#define
- 对于形似函数的宏,最好改用inline函数替换#define
条款03:尽可能使用const
经const修饰的内容,编译器会强制保持不变,const在修饰指针时在’*‘的左侧为指针所指的地址的内容为常量,在’*'右侧为指针所指的地址为常量,两侧都有就都为常量
const int *p;//指针指向的地址中的值为常量
int const *p;//指针指向的地址中的值为常量
int * const p;//指针指向的地址为常量
const int *const p;//指针指向的地址和地址中的值均为常量
int const * const p;//指针指向的地址和地址中的值均为常量
STL中的迭代器可以理解为一个泛型指针T*,用法如下:
std::vector vec;
const std::vector::iterator iter=vec.begin();//iter相当于T* const
*iter=10;//可以修改指针所指向地址中存储的值
iter++;//地址不可以改变iter是一个常量
const std::vector::const_iterator cIter=vec.begin();//iter相当于T const *或constT*
*cIter=10;//不可以修改指针所指向地址中存储的值
cIter++;//地址可以改变
在一个函数内const可以修饰参数,返回值,函数自身(成员函数)产生关联
修饰参数:保护实参不可被修改
修饰函数自身:该函数不可被修改非static成员变量和非mutable修饰的成员变量,不可调用非const修饰的成员函数
修饰返回值:使函数调用表达式不能作为左值。用const来修饰返回的指针或引用,保护指针指向的内容或引用的内容不被修改,也常用于运算符重载。
总结
- 用const修饰一些东西可以帮助编译器侦测出错误用法。const可以修饰任何作用域内的对象,函数参数,函数返回值,成员函数本身。
- 当const和非const成员函数有共同实现,可以令非const修饰的成员函数调用const修饰的成员函数,在const修饰的成员函数中实现该功能。
条款04:确定对象被使用前已经先被初始化
在初始化这件事上C++表现的反复无常,有时会默认初始化,有时默认初始化的值是一个无效值,最佳处理办法就是每次我们自己进行初始化,防止一些意外的发生。
类的初始化落在构造函数的身上,但请区分初始化和赋值。如下:
class Test{
public:
Test(const int a,const int b);
private:
int aa;
int bb;
};
Test::Test(const int a,const int b){
aa=a;//赋值而非初始化
bb=b;//赋值而非初始化
}
首先了解下类的构造过程,调用上述构造函数时系统会先调用构造函数为成员变量初始化,然后在给他们赋值,这样明显初始化没有任何意义,浪费了效率。另一种较佳的写法如下:
Test::Test(const int a,const int b)
:aa(a),//这样是走初始化
bb(b)
{}
构造函数如上面方法实现就会在初始化时进行拷贝构造,对于大多数类型(非内置类型)来说,只进行一次拷贝构造会比先进行构造再进行赋值效率高,有的类型甚至高效得多。当成员变量中存在const修饰的成员变量或者存在引用的时候,如果不使用成员初值列,在构造函数中是无法给他们赋值的。只要有成员变量就是用成员初值列,这样做往往比赋值更加高效。但是如果有时候成员变量特别多又同时存在多个构造函数,写起来有很多重复,这是可以将那些内置的类型从成员初值列中去掉,用一个私有的函数来执行赋值操作(内置类型拷贝构造和赋值效率差值不大),这个私有函数可以供多个构造函数调用。
C++有着固定的成员初始化次序(声明时的次序),即使成员初值列中顺序与声明顺序不同,依旧执行声明时的次序,但为了后期维护,尽量将成员初值列和成员声明时的次序相同。
static对象的初始化十分复杂,在多文件多个全局static对象时为避免初始化次序问题,使用local static对象替换non local static对象。
总结
- 对于内置类型对象进行手工初始化。
- 构造函数最好使用成员初值列,而不要在构造函数内使用赋值操作。初值列成员变量其排列次序应该和他们在class中声明次序相同。
- 为免除夸编译单元的初始化次序问题,使用local static对象替换non local static对象。
第二章:构造/析构/赋值运算
条款05:了解C++默认编写并调用了哪些函数
当你定义一个空类时,编译器会为它默认生成构造函数,析构函数,拷贝构造函数,重载操作符(=),如果某个基类将重载操作符(=)声明为private,编译器将拒绝为派生类生成重载操作符(=)。
总结
- 编译器可以默认为一个空类生成构造函数,析构函数,拷贝构造函数,重载操作符(=)。
条款06:若不想使用编译器自动生成的函数,就该明确拒绝
如果你不想使用编译器默认生成的函数,那么就要把他们声明在private中防止被外部调用,而不是不声明(条款05中明确说明了不声明编译器会为其生成默认的函数)。如果担心被成员函数和友元函数调用可以不予实现只声明即可,这样在连接时找不到函数的实现。
将连接期的错误移至编译器也是可能的,并且在编译器发现错误更好。只要声明一个基类并用private声明不想使用的编译器默认生成的函数,再用派生类继承基类即可实现。
总结
- 不想使用编译器默认生成的函数,那么就要把他们声明在private中,并且不予实现。使用派生类继承基类也是一种方法。
条款07:为多态基类声明virtual析构函数
基类的析构函数声明成virtual可以防止在用基类指针绑定派生类实例时派生类析构函数未执行而导致内存泄露。至于为什么这么做大家可以看我另一篇文章:
https://blog.csdn.net/qq_33865609/article/details/117515859
如果不作为基类尽量不要使用virtual声明任何成员函数,因为声明虚函数会增加类所占用的内存空间。
所有的STL容器都不带有虚析构函数,所以尽量不要用一个类去继承STL的任何容器,这样有可能导致内存泄漏。
如果一个想要定义一个只作为基类的类(抽象类),那么该类至少含有一个纯虚函数,基类的析构函数也需要定义成虚函数,那么可以直接将析构函数定义成纯虚函数,如下:
class Test{
public:
virtual ~Test()=0;
};
总结
- 一个类如果想用作基类就要生命一个虚析构函数,如果一个类有任何虚函数那么他的析构函数也应该声明成虚函数。
- 如果这个类不作为基类就不要为其声明虚析构函数。
条款08:别让异常逃离析构函数
C++并没有禁止在析构函数中抛出异常,但是它不建议你这样做。通常在异常发生时,C++的机制会调用对象的析构函数来释放资源,如果此时析构函数抛出异常,前一个异常还没有处理,又出现新的异常,这样会导致程序的崩溃。最好的办法就是将析构函数中的异常在析构函数内部解决。如下:
~Test(){
try{
正常调用
}
catch(){//捕捉异常可以什么都不处理,但是不要将异常抛出到析构函数之外
}
}
总结
- 绝对不要在析构函数中抛出异常。如果析构函数调用的函数可能抛出异常,那么析构函数应该捕捉任何异常,然后吞下异常或者结束程序。
- 如果需要对某个操作函数运行期间抛出异常做出反应,那么类中应该提供一个普通函数(而不是在析构函数中)执行该操作。
条款09:绝不在构造和析构函数中调用virtual函数
虚函数存在的极大意义是为了实现多态,在父类中定义虚函数数子类继承父类,重写虚函数。在构造子类的对象时会先走父类的构造函数,如果在父类的构造函数中调用虚函数,此时调用父类的虚函数根本不会调用到子类重写的虚函数,因为此时子类还没有走到构造函数子类还没有创建,这显然不是我们想要的结果。在构造期间父类的虚函数不具有虚函数的性质,和普通成员函数无异。
在析构时也有类似的现象,析构时先走子类的析构函数,此时子类的成员都被释放,在走父类析构函数时里面调用虚函数也不会调用到子类重写的虚函数,因为子类已经释放了。
通过上面解析可以看出在构造函数和析构函数中调用虚函数并不能打到我们想要的效果,所以不要再构造函数和析构函数中使用虚函数。
总结
- 不要在构造函数和析构函数中不要调用virtual函数,因为这类调用从不下降至子类
条款10:令operator=返回一个reference to *this
在重载赋值运算符的时候下面两种写法都可以通过编译:
Test Test::operator =(const Test& test)
{
return *this;
}
Test &Test::operator =(const Test& test)
{
return *this;
}
第一种相当于返回一个临时的对象,当讲一个临时对象存储在变量中时会调用拷贝构造函数,第二种写法相当于返回这个对象的引用,也就是返回这个对象本身
这样不会调用拷贝构造函数。
返回引用这个写法不止使用与重载赋值运算符,还是用于operator+=,operator-=,operator*=等。
虽然这个协议不是强制性的,而且编译也不会报错,但是还是建议遵守此协议。
总结
- 令赋值操作符返回一个reference to *this
条款11:在operator=中处理“自我赋值”
class Bitmap{...};
class Widget{
...
private Bitmap *pb;
}
为了防止自我赋值,传统的做法如下:
Widget& Widget::operator=(const Widget& rhs){
if(this == rhs){
return *this;
}
delete pb;
pb=new Bitmap(*rhs.pb);
return *this;
}
new Bitmap可能异常,如果new Bitmap异常了,pb又被释放了,那么可能会导致一些问题发生。于是又有了如下写法:
Widget& Widget::operator=(const Widget& rhs){
Bitmap* pOrig=pb;
pb=new Bitmap(*rhs.pb);
delete pOrig;
return *this;
}
上面的写法先通过一个临时的指针保存了原来成员的指针,然后在去new,如果new成功就将临时指针内容(也就是原来成员)释放掉。如果出现异常临时指针内容(也就是原来成员),临时指针内容不会被释放,原来的成员变量的内容也就得以保存,其他地方用到的时候不会导致出现使用空指针的情况。
copy and swap技术
Widget& Widget::operator=(const Widget& rhs){
Widget temp(rhs);
swap(temp);
return *this;
}
将rhs拷贝一份到temp和*this数据交换,还有一种更为高效的写发但是牺牲了清晰性:
Widget& Widget::operator=(Widget rhs){
swap(rhs);
return *this;
}
总结
- 确保对象有可能出现自我赋值时operator=能有良好的行为。
- 确保任何函数如果操作一个以上的对象,而其中多个对象是同一个对象时行为仍然正确。
条款12:复制对象时勿忘其每一个成分
如果自己实现了拷贝构造和赋值运算函数,在增加类的成员的时候,要修改对应的拷贝构造函数和赋值运算函数,否则在拷贝构造和赋值运算的时候导致新增加的成员没有进行赋值。这种情况编译器不会报错。
在进行类的拷贝构造和赋值运算时不要忘记对象内的所有成员变量,如果存在继承的情况不要忘记父类成分。
class Customer{...}
class PriorityCustomer:public Customer{
public:
...
PriorityCustomer(const PriorityCustomer& rhs);
PriorityCustomer& operator=(const PriorityCustomer& rhs);
...
private:
int priority;
}
实现子类的拷贝构造函数和赋值运算函数要调用父类的拷贝构造函数和赋值运算函数。
PriorityCustomer::PriorityCustomer(const PriorityCustomer& rhs)
:Customer(rhs),
priorty(rhs.priority)
{
}
PriorityCustomer& PriorityCustomer::operator=(const PriorityCustomer& rhs){
Customer::operator=(ths);
priority=ths.prority;
return *this;
}
子类的拷贝构造函数调用父类的拷贝构造函数,子类的赋值运算函数调用父类的赋值运算函数,不要互相调用,这样可能导致你不想要的结果出现。例如在子类赋值运算函数中调用了父类的拷贝构造函数,这样会重现创建一个对象,并不是我们想要的赋值效果。在子类的拷贝构造函数中调用父类的赋值运算函数同样达不到我们想要的效果,试想在我们想要创建一个对象的时候,调用赋值运算函数,给一个没有创建的对象赋值,这并不是我们想要的结果。
总结
- 拷贝函数应该确保复制对象内的所有成员和所有父类的成分。
- 不要尝试以某个拷贝函数实现另一个拷贝函数,应该将共同机能放进第三个函数中并由两个拷贝函数共同调用。
第三章:资源管理
条款13:以对象管理资源
在写代码的时候,经常遇到通过new,或者malloc在堆上开辟空间,在堆上开辟的空间需要程序自己控制释放,如果不释放会导致内存泄露,直到进程结束后才由系统回收,内存如果占有量过大很可能会被系统杀死,这并不是我们想要的结果,所以我们一定要控制内存的开辟和合理的释放。
Investment* createInvestment();
void f()
{
Investment* pInv=createInvestment();
...
delete pInv;
}
上面代码虽然调用了delete释放了内存,但是在…中却存在不安因素,如果…中有return语句,或者goto语句可能会导致内存泄露。就算程序员十分谨慎在应该的位置都增加了释放内存的代码,在后期维护时这地方仍然是个不安因素,维护时候增加了一个return就会导致内存泄露,这个问题在维护过程中并不容易被注意到。所以我们在类中释放内存最好放到析构函数中,这样在不需要使用对象的时候,对象中的成员都会通过析构函数释放内存。如果在释放内存时候抛出异常参考条款8,别让异常逃离析构函数即可。
以对象管理资源的两种关键方法:
1.获得资源后立刻放进管理对象内:
以对象管理资源的方式也常被成为RAII(Resource Acquisition Is Initialization)原则,即在资源获取之后立刻初始化到管理对象中。
2.管理对象运用析构函数确保资源被释放:
不论控制流如何离开模块,一旦对象被销毁(例如对象离开作用域)其析构函数被调用,对象管理的资源就会被释放。如果资源释放动作可能导致异常,条款8已经能够解决这个问题了。
C++中智能指针便是RAII原则的最好应用实例了,智能指针实际上是一个类,在构造的时候为指针开辟内存,析构的时候释放内存。这样就减少了程序员手动操作,增强了程序健壮性。
智能指针的具体介绍看我另一篇文章这里就不具体介绍了。
总结
- 防止资源泄漏使用RAII对象,他们在构造函数中获得资源并在析构函数中释放资源。
- 经常被使用的两个RAII类就是shared_ptr和auto_ptr(作者基本不使用auto_ptr,因为他不能共享所有权在copy的时候原来的指针变量会指向NULL,如果不经意使用这个变量就会导致崩溃)
条款14:在资源管理类中小心copying行为
在资源管理类中,一般都是在构造的时候申请资源,在析构的时候释放资源,如果使用类的拷贝构造函数,这就会导致申请一次资源会释放两次的危险。所以在资源管理类中我们注意处理复制的问题:
1.禁止复制
在很多时候我们不需要RAII对象被复制那么我们可以将拷贝操作声明为私有的或者删除这个函数
2. 对资源采用引用计数法
有时候我们希望保有资源在他最后一个使用者后被释放这时可以使用对资源进行计数的方法,在每次复制的时候被引用数量增加,在每次释放的时候判断被引用计数时候为0,不为0就减一,为0时则释放掉资源。智能指针shared_ptr就是用的这种引用计数的方法。
3.复制底部资源
在复制资源管理对象的时候,同时也复制其所包覆的资源,也就是说复制资源管理对象时要进行深度拷贝。
4.转移底部资源的所有权
资源的所有权会随着复制从被复制对象转移到目标对象。类似于智能指针auto_ptr。复制执行后原来持有资源所有权的对象会失去资源的所有权。
总结
- 复制RAII对象必须一并复制它所管理的资源,所以copying行为决定RAII对象的copying行为。
- 常见的RAII对象复制处理是禁止拷贝或者使用引用计数法。不过其他行为也都可以实现,但是并不推荐,除非有特殊需求。
条款15:在资源管理类中提供对原始资源的访问
将原始资源的管理交给了资源管理类,这样做防止了因为程序员的操作失误而导致的资源泄露。但是在使用的时候会有不方便,因此资源管理类必须提供访问原始资源的方法。
最常见的类的成员的访问方法就是get方法,这种方法可以直观的获取到我们想要获取的资源,因此这种方式称之为显示的访问方式。这种方法的好处就是直接不容易出错。
使用过C++智能指针的都了解智能指针通过重载操作符(*,->)实现了通过对象隐试访问智能指针类中管理的资源对象。隐试访问的好处是使用者使用起来很方便通过使用资源管理对象就可以当做该类中管理的资源使用。
总结
- 资源管理类应该提供提供给访问者一个访问原始资源的方法。
- 对原始资源的访问可能是隐式或者显示的。一般显示比较安全,但隐式使用起来比较方便。
条款16成对的使用new和delete时要采取相同的形式
在C++中对堆空间的开辟方式有两种一种是C语言中的原始方法malloc,另一中是new,new又可以分成new单个成员和new数组,在释放时要考虑到开辟内存时候使用的是什么形式。
当使用new时,会有两件事发生,第一是内存被分配出来,第二针对内存会有一个(或更多)构造函数被调用。当使用delete时也会有两件事发生,第一是针对内存会有一个(或更多)析构函数被调用,第二是释放内存空间。
如果我们在new的时候new了一个数组如下:
int *a=new int [10];
这时在内存中开辟了10个int大小的连续内存。在我们调用delete时如果我们不指定删除对象为数组对象那么delete会将对象看做单一对象delete如下:
delete a;
这样就会导致delete的不彻底。还有可能引发其他不可控的问题。正确的delete如下:
delete []a
总结
开辟空间和释放空间要使用相同的形式,malloc和free;new和delete;new[]和delete[]。
条款17:以独立语句将newed对象置入智能指针
在我们使用智能指针作为函数参数时候尽量将对象传入智能指针的语句独立出来。否则我们无法控制编译器调用的优先顺序。代码声明如下:
int priority();
void processWidget(std::tr1::shared_ptr<Widget> pw,int priority);
调用如下:
//调用方式1
processWidget(new Widget,priority());
这种调用方式根本无法通过编译,因为tr1::shared_ptr构造函数无法隐式转换
//调用方式2
void processWidget(std::tr1::shared_ptr<Widget> (new Widget),int priority);
这种调用方式我们无法控制编译器用什么样的调用顺序完成这件事,因为在这个函数的两参数中一共有三件事需要完成
- 执行new Widget
- 构造tr1::shared_ptr
- 调用priority
只能知道1调用一定在2之前,并不能确定3的调用时机,如果3调用在1,2之间,并且3调用异常会发生什么情况呢?会导致资源已经申请但是并没有放入到资源管理类中去,那么就有可能导致在对processWidget调用过程中发生内存泄露(new的资源并没有被合理释放)。如果我们像下面这么写就会完美避免这一问题:
std::tr1::shared_ptr<Widget> pw(new Widget);
void processWidget(pw,int priority);
总结
以独立的语句将new的对象存储在智能指针中,防止在多个不可控操作时抛出异常,造成难以察觉的内存泄露。
第四章设计与声明
条款18:让接口容易被正确使用,不易被误用
书中举例子是年月日,比如一个接口需要传入三个值分别是年月日,由于年月日一般都是int型所以容易出现把年月日传混的情况,并且程序不会察觉出来传入的值有问题,出现这种问题就需要调试调查原因,下面直接上代码:
定义:
class Date
{
public:
Date(int year,int month,int day);
};
调用:
Date d(1,1,1993);//这么传入也不会错但是明显值是不对的所以我们需要对函数入参有一个限制
下面增加一些限制防止年月日的顺序输错了
定义:
struct Day
{
explicit Day(int d):val(d){} //explicit防止构造函数隐式转换
int val;
};
struct Month
{
explicit Month(int m):val(m){}
int val;
};
struct Year
{
explicit Year(int y):val(y){}
int val;
};
class Date
{
public:
Date(const Year &y,const Month &m,const Day &d);
};
Date d(Year(1993),Month(1),Day(2));//这就可以限制年月日的传入顺序
Date d(Month(1),Day(2),Year(1993));//这么传直接报错
当然还有问题就是月份有限制只有1到12是有效的,下面继续增加限制
struct Month
{
public:
static Month Jan(){return Month(1)}
static Month Feb(){return Month(2)}
...
static Month Dec(){return Month(12)}
private:
explicit Month(int m):val(m){}
int val;
};
Date d(Year(1993),Month::Jan(),Day(2));//这样不用传月份数字直接通过月份的静态成员函数来获取月份,可以避免月份超出1到12这个范围的情况发生
书中还介绍了一个接口返回指针或者返回智能指针的例子,如果返回一个指针接口使用者不一定会将返回的指针放到智能指针中使用这可能会导致一些内存泄露或者重复释放的风险,如果返回值直接设置成智能指针类型,那么接口使用者只能通过智能指针去接收这个返回值,这样就可以使用智能指针管理这个指针,防止内存泄露和重复释放发生。下面写例子
int *CreateInt();//无法确定接口使用者使用智能指针还是非智能指针接收,有内存泄露和重复释放的风险
std::share_ptr<int> CreateInt();//使用智能指针返回,让智能指针管理内存的释放时机安全
总结
好的接口设计不容易被误用。设计接口时应努力达到这样。
促进正确使用的办法包括接口一致性以及内置类型的行为兼容。
阻止误用的办法可以创建新类型限制类型上的操作,约束对象值,消除客户的资源管理责任。
条款19:设计class犹如设计type
在C++中定义了一个类(class)就相当于自定义了一个新的类型(type)在定义这个类时我们应该考虑下面几点:
- 新类型的对象应该如何创建和销毁?:这个想必大家都知道通过构造函数创建析构函数销毁,我们要考虑怎么设计构造函数和析构函数是否需要传参,函数里面是否需要重写一些其他的内容。
- 对象的初始化和对象的赋值有什么差别?:这就涉及到了赋值运算函数和构造函数,需要大家考虑构造一个新的对象和赋值其他对象的值有什么区别。
- 类的对象如果被值传递,意味着什么?:考虑一下拷贝构造函数的深拷贝浅拷贝问题。
- 什么是新类的和法值?:比如新类中有某个成员是枚举类型只有枚举指定的值有意义,那么就要对这个值的赋值进行限制(一般就是对构造函数和set函数限制),也就是在赋值时候进行一下范围检查。
- 新类需要配合某个继承图系吗?:如果你的新类继承了某个基类那么就要考虑基类中的虚函数是需要重写还是复用基类的实现,也需要考虑新类是否被其他类继承,如果需要被其他类继承需要考虑哪些函数声明为虚函数,析构函数必须声明成虚函数。
- 新类需要类型转换吗?:显示转换还是隐式转换需要考虑,必须一个class A 需要提供一个转换成class B的方法,显示转换可以直接提供一个获取方法(B getB()),隐式转换可以提供一个运算符重载方法( operator B() )。
- 新类需要声明什么样的成员函数?:这个需要根据需求自己决定包括那些运算符需要重载。
- 新类哪些成员需要私有哪些需要受保护哪些需要公有?:根据需求自己决定,设定合理即可。
- 什么是新类的未声明接口?:个人理解这里想说的是除了接口我们还要注意一些隐晦的问题,比如是否会出现死锁是否会内存泄露。在这些方面做出一些限制。
- 你的新类有多么一般化?:考虑这个类是定义个类型家族。如果是定义一个类型家族则应该定义一个模板类。
- 是否有必要定义一个新类?:如果定义的新类继承了某个基类,可以考虑下是该定义新类还是该在原本基类上增加成员。
总结
谨慎定义一个新的类。
条款20:宁以const引用传递代替值传递
先说一下引用传递和值传递的区别,引用传递本质是地址的传递,而值传递是在函数中新构建一个临时变量存储入参,这就不难看出在一些复杂类型传递时引用的传递效率高于值传递。
引用传递如果函数中修改了参数值,调用该函数的函数中的值也会改变,而值传递不会。如果想防止入参改变可以将引用传递前面加上const防止函数里面修改入参。
C++中引用传递可以防止对线切割,这里说明一下比如你定义一个基类Person和派生类Student,Student继承了Person,有个接口A需要一个参数Person,如果此时我们用值传递传入一个Student的对象,那么在接口A中就会拷贝构造一个Person的对象并且会将Student对象中的基类Person的部分拷贝给接口A中的Person的对象,而Student本身的属性就被抛弃了。也就是接口A收到的实参其实就是一个Person的对象只拷贝了Student基类的部分,并不是我们传入的完整的Student对象。如果使用引用传递那么接口A就不会拷贝构造生成一个新的Person的对象,而是产生一个地址去存储Student的地址。这样我们在接口A中如果想使用Student的属性还可以通过将Person强转成Student获得。
总结
- 尽量使用引用传递代替值传递,引用传递通常比较高效,并且可以避免对象切割。
- 对于内置类型(int,char,double…)以及stl迭代器,函数对象,指针(指针传递本身就属于值传递),往往更适合值传递。
条款21:必须返回对象时别妄想返回对象的引用
一般情况下函数返回值都采用值传递,而不是返回一个引用。下面说下这么做的原因。
- 如果返回一个临时变量的引用,在函数返回之后这个引用的内存会被释放。
- 如果返回一个指针的引用不知道这块内存到底该由谁释放。有重复释放和内存泄露的风险。
- 如果返回一个函数内静态变量的引用,已知静态变量只初始化一次,以后每次返回的都是原来的变量,如果你想要多个这种变量,这可能不是你想要的。当然如果创建单例时可以使用静态变量创建一个单例以后每次返回都是原来的单例这个是想要的结果。具体情况具体分析。
总结
不要返回一个指向临时变量的指针或者引用,或返回一个在堆空间新创建的引用,也不要返回一个需要多个对象的静态变量的引用,因为静态你每次获取都是初始化创建的那一个。
条款22:将成员变量声明为private
下面说一下如果成员变量声明成public和protected的一些缺点:
public:
如果成员变量声明成public类型的,使用者可以直接访问该变量,这样没有任何限制使用者可以任意赋值甚至可以赋一些超出范围的非法值。如果不使用public声明成员变量,我们提供一些public的get和set方法可以在方法中做一些限制,如果有些成员变量我们只需要使用者赋值或者只需要使用者获取值我们就可以只提供一个set或者get方法就可以了。将成员变量隐藏在接口背后可以为所有可能的实现提供一些弹性,我们修改public的方法内部不会导致使用者做对应的修改,使用者只需要通过public提供的方法去获取我们的成员就好。
protected:
如果成员变量声明成protected类型的,使用者虽然不可以直接访问该变量,但是如果这个类作为基类其他类会继承这个类的成员。如果这个类的成员做了修改(增加或者删除)所有继承这个类的派生类都需要做修改,如果声明成public同样存在这个问题但是声明成private类型的就不会出现这个问题。牵一发而动全身这种事情在代码繁杂的项目中显然是我们不愿意看到的。
private有最好的封装性,为了后续项目代码的维护便利应该将成员变量声明成private。
总结
务必将成员变量声明成private。这样方便使用者访问数据保持一致性,创建者可细微划分访问控制,也可以做对成员做约束,并且给创建者充分的实现弹性。
条款23:宁以non-member、non-friend替换member函数
本条款个人理解就是不要一味的使用成员函数去满足调用者的需求,应该站在这个类的创建者的角度去思考一些问题,例如一个狗的类,这个类里面有品种,年龄,性别… 我们在创建这个对象时候想要知道他的年龄和性别我们不要提供一个成员函数或友元函数将这两个成员提供给使用者,我们需要分别提供各自成员的get函数,让使用者自己去灵活调用,需要什么就去获取什么。这样可以保证封装性,使用更少的方法去访问成员。如果真的需要频繁的获取年龄和性别我们可以创建一个工具类里面写一个方法去将年龄和性别获取到提供给使用者,而不是在狗这个类中去创建一个方法。
在我们去定义一些工具类的时候在注意其中的共性将有共性的定义在一个类里,将所有工具类放在一个命名空间里,这样可以减少编译依赖,如果只想使用工具类中的某一类接口就可以不去引用其他的工具类。这正是C++标准库的组织方式,比如你想使用list就需要引用#include而不需要引用其他的容器,这就可以只与一小部分系统形成编译相依。
总结
宁可拿non-member、non-friend函数替换member函数。这样增加封装性包裹,弹性和机能扩充性。
条款24:若所有参数皆需要类型转换请为此采用non-member函数
本条款中举例为operator *这个函数是应该写为成员函数、友元函数还是一个普通的函数。
在类内作为一个成员函数我们可以这么写
class Rational
{
public:
Rational(int numerator = 0,int denominator = 1); //允许隐式转换
int numerator() const;
int denominator() const;
const Rational operator *(const Rational & rhs) const;
private:
...
};
这么写就会出现一个问题因为成员函数本身存在一个this指针参数,而 operator *()函数最多只能有两个参数,所以除了this指针这个参数只能选择一个对象的引用作为另一个参数。
下面写法可以实现
Rational oneEighth(1,8);
Rational oneHalf(1,2);
Rational result;
result = oneHalf * oneEighth; //正确
result = oneEighth * oneHalf; //正确
但是当我们想要隐式转换的时候会发现一些问题
result = oneHalf * 2;//正确
result = 2 * oneHalf;//错误
下面重写一下这两个式子
result = oneHalf.operator * (2);//正确
result = 2.operator * (oneHalf);//错误
上面由于operator *()两个参数一个是this指针一个是Rational的对象oneHalf的引用,当实参传2的时候因为形参是一个Rational的对象oneHalf的引用,而Rational类的构造函数允许隐式转换所以可以正常运算;但是2无法隐式转换为this指针所以没有operator * ()成员函数所以这种压根编译不过。要想解决这个问题可以将operator * ()写成一个非成员函数这样没有this指针这个隐形的参数,这个函数里面就可以传入两个参数。非成员函数包括普通函数和友元函数。我们要知道友元函数的初衷是为了访问受保护和私有成员,如果这里只是为了传两个参数而使用
友元函数违背了友元函数的初衷,并且我们无论在何时也应该尽量避免使用友元函数,因为它会破坏类的封装。尽量使用成员函数访问私有成员和受保护成员而不是选择友元函数。当然友元函数也有其使用的场景。但是我们不能够只因为非成员函数就将其声明为友元函数。所以我们可以声明为一个普通的函数。
const Rational operator * (const Rational &lhs,const Rational &rhs)
{
return Rational(lhs.numerator() * rhs.numerator() , lhs.denominator() * rhs.denominator())
}
总结
如果你需要为某个函数的所有参数(包括this指针所指的那个隐喻参数)进行类型转换,那么这个函数必须是个non-member。
条款25:考虑写出一个不抛异常的swap函数
首先看下标准程序库提供的swap算法:
namespace std
{
template<typename T>
void swap(T& a, T& b)
{
T temp(a);
a = b;
b = a;
}
}
可以看出标准程序库中是通过一个拷贝构造和两个赋值运算来完成两个成员a,b之间的转换。这种swap实现相当于两个对象完全的调换,但是对于有些类来说我们只需要调换对象中的某个或者某几个成员,那么在使用这种标准库中的swap函数完全没有必要。所以在有些时候我们需要实现特化的swap函数
namespace std{
template<>
void swap<Widget>(Widget& a,Widget& b)
{
swap(a.pImpl , b.pImpl) ;
}
}
上面代码中swap函数里面无法直接使用类的私有和受保护的成员,所以上面写法会报错,我们可以将特化的swap声明成这个类的友元函数,但是这和以往的规矩不太一样。我们还可以使用Widget声明一个swap的公有成员函数,同时再将std::swap特化:
class Widget
{
public:
void swap(Widget& other)
{
using std::swap;
swap(pImpl , other.pImpl)
}
};
namespace std
{
template<>
void swap<Widget>(Widget& a, Widget& b)
{
a.swap(b);
}
}
这种做法不仅能通过编译还与STL容器有一致性,因为STL容器也都提供public swap成员函数和std::swap特化版本。一般都是采用std::swap的特化版本调用类内的public swap方法。
然而假设Widget和WidgetImpl都是class templates 而非classes,也许我们可以试试将WidgetImpl内的数据类型加以参数化
template<typename T>
class WidgetImpl{...};
template<typename T>
class Widget{...};
如果是class templates在std命名空间内swap特化应该写成下面样子:
namespace std
{
template<typename T>
void swap (Widget<T> &a,Widget<T> &b)
{
a.swap(b);
}
}
这样书写会报错std命名空间比较特殊。我们可以全特化std内的swap方法,但是不可以添加新的模板到std中。其实我们可以自定义一个命名空间来实现如下:
namespace WidgetStuff
{
...
template<typename T>
class Widget{...};
template<typename T>
void swap(Widget<T> &a,widget<T> &b)
{
a.swap(b);
}
...
}
这样就可以实现了,如果T是Witget并位于命名空间WidgetStuff内,编译器会使用实参找到WidgetStuff内的swap。如果没有T专属的swap,编译器会调用std内的swap。如果我们在写代码时候不是十分确定的想要调用制定命名空间里的函数不要使用 命名空间::函数名 这种写法。例如上面写的如果是std::swap(obj1,obj2)。那么编译器只认std内的swap函数,那么就不会调用一个比较适合模板专属的版本。如果在调用函数swap之前使用using std以便让他std::swap在函数调用前得到曝光,然后调用swap时候不添加任何命名空间赤裸裸的调用swap,那么就会调用比较适合的那个swap。
总结
- 当std::swap 对自定义类效率不高时,提供一个swap成员函数,并确定这个函数不抛出异常。
- 如果你提供一个swap成员函数,也应该提供一个非成员函数调用他对于非模板类请特化std::swap。
- 调用swap时应针对std::swap使用using声明式,然后调用swap并且不带任何命名空间修饰符。
- 为用户定义的class进行std 模板全特化是好的但是不要在std内内增加对于std而言全新的东西。
第五章:实现
条款26:尽可能延后变量定义式的出现时间
我们知道每个类型的变量定义时相当于调用了该类型的构造函数,释放时相当于调用了该类型的析构函数。在我们写代码时如果不注意就会导致一些无效的构造和析构被调用。
std::string encryptPassword(const std::string &password)
{
using namespace std;
string encrypted;
if(password.length()<MinimumPasswordLength)
{
trow logic_error("Password is too short");
}
...
return encrypted;
}
对象encrypted过早被定义了,如果密码长度低于最小长度会抛出异常,这样会毫无意义的调用一次string的构造和析构。
std::string encryptPassword(const std::string &password)
{
using namespace std;
if(password.length()<MinimumPasswordLength)
{
trow logic_error("Password is too short");
}
string encrypted;
...
return encrypted;
}
这样写虽然string的构造肯定会有意义但是这样没有初始化,我们都知道string可以直接初始化他的对象。如果这么调用那么就会先调用默认无参构造然后调用赋值运算给其赋值,但如果直接采用有参构造会有更高的效率。
std::string encryptPassword(const std::string &password)
{
using namespace std;
if(password.length()<MinimumPasswordLength)
{
trow logic_error("Password is too short");
}
string encrypted(password);
encrypted(encrypted);
return encrypted;
}
这样才是比较好的代码实现方式,尽可能延后的意义不只是延后变量的定义,应该直到非使用该变量的前一刻为止,甚至应该尝试延后这份定义知道能够给他初值的实参为止。这样不仅能够避免够着和析构非必要对象。还可以避免无意义的默认构造行为。更深一层说,以“具明显意义之初值”将变量初始化,还可以附带说明变量的目的。
下面我们来说说循环时怎么定义变量是再循环体内还是再循环体外。
//方法A:一次构造,一次析构,n次赋值
Widget w;
for(int i=0;i<n;++i)
{
w=取决于i的某个值;
}
//方法B:n次构造,n次析构
for(int i=0;i<n;++i)
{
Widget w(取决于i的某个值);
}
如果Widget的赋值成本低于一组构造+析构成本,做法A比较高效,否则做法B更好。A中Widget的对象w作用域覆盖到了for循环外部这可能会导致程序的可理解性和已维护性造成冲突,而且当n=0时方法A还是会产生一次无意义的构造。因此除非你很清楚赋值比构造+析构成本更低,或者代码对效率高度敏感。否则你应该使用方法B。
总结
- 尽可能延后变量定义的出现时机,这样做可以增加程序的清晰度并改善程序效率。
条款27:尽量少做转型动作
C++中可以使用的强制转型包括旧式转型和四种新式转型:
旧式转型:
(类型)变量名
新式转型:
const_cast<类型>(变量名)
dynamic_cast<类型>(变量名)
reinterpret_cast<类型>(变量名)
static_cast<类型>(变量名)
下面简单介绍下这几种强转:
1.const_cast:
我目前在公司项目编码中还没有使用过const_cast。const_cast主要是用来去除或者添加复合类型中const和volatile属性(没有真正去除或添加)。为什么这么说请看下面几段代码:
//去除const
int main(int argc, char *argv[])
{
const int a=10;
int *b = const_cast<int *>(&a);
std::cout<<a<<std::endl;
std::cout<<*b<<std::endl;
*b = 20;
std::cout<<a<<std::endl;
std::cout<<*b<<std::endl;
return 0;
}
输出:
10
10
10
20
上面这段代码可以看出虽然表面去除了const属性,但是a的值并没有因为*b的值的改变而改变。所以上面说并没有真正去除。直接修改a的值编译时会报错。
//去除const
int main(int argc, char *argv[])
{
int i=10;
const int a=i;
int *b = const_cast<int *>(&a);
std::cout<<a<<std::endl;
std::cout<<*b<<std::endl;
*b = 20;
std::cout<<a<<std::endl;
std::cout<<*b<<std::endl;
return 0;
}
输出:
10
10
20
20
上面这段代码可以看出a的值因为b的改变而改变了,产生这种问题的原因就是,如果将常量赋值给const修饰的变量以后使用到这个const变量的时候将会直接用这个常量替代,但是如果将一个变量赋值给const修饰的变量就不会采用定义时候的值直接替换。直接修改b的值编译时会报错。
//增加const
int main(int argc, char *argv[])
{
int a=10;
const int *b = const_cast<const int *>(&a);
std::cout<<a<<std::endl;
std::cout<<*b<<std::endl;
a = 20;
std::cout<<a<<std::endl;
std::cout<<*b<<std::endl;
return 0;
}
输出:
10
10
20
20
上面这段代码可以看出b的值因为a的改变而改变了,原因和之前的一样因为b复制的时候赋值给他的是一个变量。直接修改*b的值编译时会报错。
2.dynamic_cast:
dynamic_cast是将一个基类对象指针(或引用)转换到派生类指针,dynamic_cast会根据基类指针是否真正指向派生类指针来做相应处理。如果基类指针指向派生类对象,那么将会返回这个派生类的指针(该派生类和强转类型为同一个类),如果基类指针指向基类对象那么将会返回nullptr。下面直接上代码
class Base
{
public:
Base(){}
virtual ~Base(){} //基类中一定要有一个虚函数哪怕是虚析构函数
int b;
};
class Drive1:public
Base{
public:
Drive1(){}
int d1;
};
class Drive2:public Base{
public:
Drive2(){}
int d2;
};
int main(int argc, char *argv[])
{
Base *pb = nullptr;
Drive1 *pd1 = nullptr;
Drive2 *pd2 = nullptr;
pb = new Drive1(); //父类指针指向子类对象
pd1 = dynamic_cast<Drive1 *>(pb);//向下转型,父类指针转换成子类指针,父类无虚函数编译会报错
if(nullptr == pd1)
{
std::cout<<"转换失败pd1是nullptr 1"<<std::endl;
return -1;
}
pd1->d1 = 1;
pd1 = new Drive1();//子类指针指向子类对象
pb = dynamic_cast<Base *>(pd1);//向上转型,子类指针转换成付类指针
if(nullptr == pb)
{
std::cout<<"转换失败pb是nullptr 1"<<std::endl;
return -1;
}
pb->b = 1;
pb = new Base();//父类指针指向父类对象
pd1 = dynamic_cast<Drive1 *>(pb);//向下转型,父类指针转换成子类指针,父类无虚函数编译会报错
if(nullptr == pd1) //dynamic_cast返回nullptr
{
std::cout<<"转换失败pd1是nullptr 2"<<std::endl;
return -1;
}
pd1->d1 = 1;
pb = new Drive2();//父类指针指向一个继承相同父类的子类的对象
pd1 = dynamic_cast<Drive1 *>(pb);//向下转型,父类指针转换成子类指针,父类无虚函数编译会报错
if(nullptr == pd1) //dynamic_cast返回nullptr
{
std::cout<<"转换失败pd1是nullptr 3"<<std::endl;
return -1;
}
pd1->d1 = 1;
return 0;
}
上面代码中如果使用dynamic_cast向下转换(基类转派生类)基类一定要有一个虚函数否则在使用dynamic_cast的在编译的时候会报错,向上转换则不会报错。
3.reinterpret_cast:
reinterpret的意思是重新解释,只要reinterpret_cast的类型和参数在电脑中存储占用相同的比特位就可以进行转换,但是实际结果可能取决于编译器,这也就代表其不可移植。reinterpret_cast本人在项目中从未看到过,通过他的字面意思就是将那段内存按照最新的类型重新解释一下。
int main(int argc, char *argv[])
{
char b='a';
int *a= reinterpret_cast<int *>(&b);
char *c = reinterpret_cast<char *>(a);
int d = 0xff;
char *e = reinterpret_cast<char *>(d);
return 0;
}
reinterpret_cast可以用于不同类型间的指针转换,或者可以将整形转换为指针。
4.static_cast:
编码中我用到最多的就是static_cast,static_cast用来强迫隐式转换,与旧式强转十分相似,完全可以用新式转型static_cast替换我们旧式常用的场景,他们的区别就是static_cast在编译阶段会进行类型检查,而旧式的强制转换不会。使用新式转型static_cast代替旧式强转可以提高的代码的健壮性。
总结
- 如果可以尽量避免转型,特别是在注重效率的代码中避免使用dynamic_cast(消耗很大)。
- 如果必须使用转型,试着将他隐藏于某个函数背后。使用者调用函数来获取转换后的类型,避免使用者误操作。
- 使用新式转型代替旧式转型,新式转型容易识别并且分门别类。
条款28:避免返回handles指向对象内部成分
本条款比较简单这里就简单叙述一下,原文意思就是如果用指针去接收一个对象的内部成分的地址,当对象析构后会产生一个悬垂指针(指向一个被释放了的地址),这样不仅破坏了类的封装性(可以通过指针修改内容)还带来了崩溃的风险。如果不是必须尽量不要这样使用。
总结
避免返回handles(包括引用,指针,迭代器)指向对象内部。遵守这个条约可以增加封装性,帮做const成员函数的行为更像一个const,并将发生悬垂指针的可能性降到最低。
条款29:为“异常安全”而努力是值得的
下面直接上代码:
class PrettyMenu
{
public:
void changeBackground(std::istream &imgSrc);
private:
Mutex mutex;
Image *bgImage;
nit imageChanges;
};
void PrettyMenu::chargeBackground(std::istream &imgSrc)
{
lock(&mutex);
delete bgImage;
++imageChanges;
bgImage = new Image(imgSrc);
unlock(&mutex);
}
从“异常安全性”的观点来看,这个函数很糟糕。异常安全有两个条件,而这个函数一个都没有满足。
异常安全的两个条件:
- 不泄露任何资源
- 不允许数据败坏
上面代码如果new Image时候抛出异常,那么unlock将不会被执行,就会永远持有锁,bgImage也将会指向一个被删除的对象。
解决资源泄露我们可以使用条款14中提及的使用资源管理类。
void PrettyMenu::chargeBackground(std::istream &imgSrc)
{
Lock lock(&mutex);
delete bgImage;
++imageChanges;
bgImage = new Image(imgSrc);
}
如上所示就算抛出异常该函数也不会继续持有锁。资源泄露解决了,下面我们就关注下如何使数据不被败坏。
一个异常安全函数应该满足下列条件之一:
- 基本保证:如果异常被抛出,程序内的任何事务仍然保持在有效状态下。
- 强烈保证:如果异常被抛出,程序状态维持在调用该函数之前的状态保持不变。
- 不抛掷保证:承诺不抛异常,因为他们总能够完成他们原先承诺的功能。
一般而言从异常安全角度考虑不抛异常的函数很棒,但是我们很难保证在调用其他函数的时候不抛出异常。比如在我们调用new的时候如果内存不够会抛出一个bad_alloc的异常。如果可能的话尽量提供nothrow保证,如果我们实现的函数调用的其他函数有很大的抛出异常的风险个人觉得应该在我们实现的函数中处理掉该异常,如果调用的函数抛出异常我们实现的函数可以通过处理该异常返回失败或者其他预定的解决方案,这样我们对外暴露的接口就不会抛出异常,提供了nothrow保证,但对于绝大部分函数而言抉择往往落在基本保证和强烈保证之间。
在基本保证和强烈保证之间具体的使用往往视情况而定,例如我们如果使用强烈保证往往是通过copy-and-swap策略实现的,会保存一个临时变量来存储这个变化的值,如果生成这个临时变化的值过程中失败那么就不需要将这个临时值赋予最终变化的变量使其持有原来的值;如果生成这个临时变化的值成功那么就要将这个临时值赋予最终变化的变量使其持有最新的值,如果这个临时变量过大会导致代码的效率下降,这在有些注重效率的代码中往往得不偿失,所以可能这时使用基本保证是更好的方案。
总结
- 异常安全函数即使发生异常也不会泄露资源或允许任何数据结构败坏。这样的函数区分为三种可能的保证:基本型,强烈型,不抛任何异常型。
- 强烈保证往往能够以cop-and-swap实现出来,但是强烈保证并非对所有函数都具备现实意义。
- 函数提供的异常安全保证通常最高值等于其所调用的各个函数的异常安全保证中最弱者。
条款30:透彻了解inlining的里里外外
Inline函数的设计观念是将对此函数的每一个调用都以函数本体替换类似于宏。过度热衷inlining会造成程序体积变大,inline造成的代码膨胀也会导致额外的换页行为,带来效率的损失。换个角度如果inline函数的本体很小,编译器针对“函数本体”所产出的码可能比“函数调用”所产出的码更小,这样也会带来效率的提升。
inline只是对编译器的一个申请,不是强制命令。这项申请也可以隐喻提出。隐喻方式是将函数定义于类定义内如下所示:
//在定义类的时候实现函数,该函数默认是inline的,如果不是想指定这个函数是inline的不要在类定义的时候将函数实现。
class Person
{
public:
...
int age() const {return theAge;} //一个隐喻的inline申请
...
private:
int theAge;
};
如果friend(友元函数)被定义在类内,那么他们也是被隐喻声明为inline的。
template一般都声明在头文件中,如果你希望模板具现出来的所有函数都应该是inline那么可以类似如下的实现方式:
template<typename T>
inline const T& stad::max(const T &a, const T &b)
{
return a<b?b:a;
}
virtual不要使用inline,虚函数是在运行时确定具体调用哪个函数,inline是在编译期就将函数替换了,这本来就是不可能实现的事情。
如果你所编写的程序是以程序库的方式提供给使用者,那么就要评估inline对程序所带来的影响。inline函数无法随着程序库的升级而升级。如果你的函数库内有个inline 函数f,函数库使用者将f函数本体编进程序中,一旦程序库设计者修改f为non-inline,所有使用到该函数库的程序都需要重新编译,这往往是大家不愿意看到的。如果不改变函数f的inline属性那么客户只需要重新链接就好,这比重新编译要好的多。
总结
- 慎用inline,没必要为了一点点函数调用的开销而去声明inline,除非我们十分确定该函数是那种小型且调用频繁的函数(inline就是为了这种函数量身定制的)。这可以使调试过二进制升级更容易,也可以是代码膨胀问题最小化
- 不要只因为函数模板出现在头文件就将他们声明为inline。
条款31:将文件间的编译依存关系降至最低
再对程序进行修改时,如果你只做了些轻微修改,修改的不是接口而是实现,而且只修改了私有部分,然后重新构建编译时因为这次改动导致项目中大部分代码被重新编译,这种现象是我们不希望发生的。我们要将文件间的编译依存降低,将接口从实现中分离,在你修改实现文件时,接口文件如果没变引用其接口的文件也没变,那么他们将不会重新编译,这样就降低了文件之间的依存并且加快构建速度。比如定义一个成员变量如果你定义的是指针那么这个指针只依赖头文件就可以完成,但是如果你定义的是对象那么就需要构造这个对象就需要依赖实现,如果构造函数和声明没有写在一起而是和实现写在一起,那么这个类就需要同时依赖声明和定义。
总结
- 编译依存最小化的一般构思是,相依于声明式不要相依于定义式
- 程序库的头文件应该完全且仅有声明式
第六章:继承与面向对象设计
条款32:确定你的public继承塑模出is-a关系
public继承表示的事一种类与类之间一种is-a的关系,子类可以说也是一个父类(学生-子类是人-父类),但是类与类之间除了is-a还存在has-a(包含)和is-implemented-in-terms-of(根据某物实现出)关系,这两种关系后面会具体讨论。
其实在我们编码过程中也能体现出来,如果是public继承我们可以直接声明一个基类的指针去指向一个子类的对象而不报错就如下面代码,但是如果是protected继承或者private继承那么就会直接报错’Base’ is an inaccessible base of ‘Drive’
Base *d = new Drive();
总结
- public继承意味着父类和子类是一种is-a的关系。适用于父类每一个成员方法也一定适用于子类。因为每一个子类对象也都是一个父类对象。
条款33:避免遮掩继承而来的名称
下面直接上代码说明
class Base
{
public:
Base(){
}
void fun1(int a){
printf("Base::fun1\n");
}
};
class Derived:public Base
{
public:
Derived(){}
void fun1(){
printf("Derived fun1\n");
}
};
int main (int argc, const char * argv[])
{
Derived d;
d.fun1(1);
}
如上所示Base类中有fun1(int)Derived类中有fun1(),两个函数同名但是不同参,这段编译回报错,因为Derived的fun1覆盖了Base的虽然他们参数不同,这就导致在main中调用fun1其实调用的是Derived中的fun1但是Derived中的fun1没有参数这就导致报错,如果我们Derived不定义fun1其实会去调用Base的fun1,如果想调用基类中的fun1需要增加using声明,转交函数或者直接指定调用哪个类下面的fun1如下:
//using声明
class Derived:public Base
{
public:
Derived();
using Base::fun1; //使用using声明,相当于在Derived作用域内增加了Base作用域内的fun1声明,这样就可以调用到Base的fun1
void fun1(){
printf("Derived fun1\n");
}
};
int main (int argc, const char * argv[])
{
Derived d;
d.fun1(1);//调用Base类的fun1
d.fun1();//调用Derived类的fun1
}
//转交函数
class Derived:public Base
{
public:
Derived();
void base_fun1(int a){ //使用转交函数,通过调用Derived的base_fun1函数间接调用Base的fun1
Base::fun1(a);
}
void fun1(){
printf("Derived fun1\n");
}
};
int main (int argc, const char * argv[])
{
Derived d;
d.base_fun1(1);//调用转交函数调用Base类的fun1
d.fun1();//调用Derived类的fun1
}
//直接指定调
class Derived:public Base
{
public:
Derived();
void fun1(){
printf("Derived fun1\n");
}
};
int main (int argc, const char * argv[])
{
Derived d;
d.Base::fun1(1);//直接指定调用Base类的fun1
d.fun1();//不指定调用的就是Derived类的fun1
}
总结
- derived class内名称会被遮掩base class内的名称。在public继承下重来没有人希望如此。
- 为了让被遮掩的名称重见天日可以使用using声明式,转交函数或者直接指定。
条款34:区分接口继承和实现继承
public继承概念仔细检查后可以发现它由两部分组成:接口函数继承,实现函数继承。
接口函数继承是派生类继承了基类的接口,即使在子类中没有定义但是他仍可以调用一些父类中的接口(非虚函数的接口)。
实现函数继承是派生类可以继承基类的接口实现(一些已经实现的虚函数或者非虚函数)
存在纯虚函数必须被派生类实现,虚函数派生类可以选择实现该函数或者复用基类的实现。这样在大型项目中,如果有人不熟悉代码,查看到一个派生类没有实现某个虚函数,可能会照成一些疑惑;
为了方便代码维护和拓展,建议基类具体执行接口继承和缺省实现继承如下明确接口继承和明确复用基类的实现:
class Ariplane{
pubilc:
` virtual void fly(const Airport &destination)=0;
};
void Ariplane::fly(const Airport &destination)={
//实现缺省的飞行模式
}
class ModelA:public Airplane{
public:
virtual void fly(const Airport &destination){
Airplane::fly(destination);//复用基类的飞行模式
}
};
class ModelB:public Airplane{
public:
virtual void fly(const Airport &destination){
Airplane::fly(destination);//复用基类的飞行模式
}
};
class ModelC:public Airplane{
public:
virtual void fly(const Airport &destination){
//实现自己的飞行模式
}
};
如上代码就可以明确接口继承实现,防止因为使用基类的缺省实现导致的一些隐藏问题。
纯虚函数,虚函数,非虚函数之间的差异,怎么使用定义:
- 如果是一个明确的接口和实现,那么用非虚函数在基类中实现,这样以后的派生类继承基类就继承了基类的该接口和基类的实现(因为非常明确所以这一部分不会变更)。
- 如果只想被子类继承一个接口和缺省实现(可能大部分派生类功能遵循这个规则但也有一些派生类会出现特殊情况),那么使用虚函数,但是为了避免一些隐藏问题,最好将函数定义为纯虚函数,但基类实现该纯虚函数,派生类想要使用缺省实现时候可以在派生类中实现该纯虚函数并调用基类的缺省实现。
- 如果只关心派生类要有这个功能但是具体怎么实现并不关心,那么基类可以使用纯虚函数并且不需要给其缺省实现。
总结
- 接口继承和实现继承不同,在public继承下,派生类重视继承基类的接口
- 纯虚函数明确指定接口继承
- 虚函数明确指定接口继承和缺省实现继承
- 非虚函数明确指定接口继承以及强制性实现继承
条款35:考虑virtual函数以外的其他选择
这里书中介绍了四种代替virtual函数的形式:
1.使用NVI(non-virual interface)手法。令客户通过 public non-virtual 成员函数间接调用 private virtual 函数,是 Template mothod 设计模式的一种独特表现形式。这个 non-virtual 虚函数称为 virtual 函数的外覆器
class GameCharacter{
public:
int healthValue() const{
...
int retVal=doHealthValue();
...
return retVal;
}
private:
virtual int doHealthValue() const{
//缺省算法
}
};
2.将虚函数替换为“函数指针变量”,这是策略(Strategy)模式的一种分解表现形式,它提供了一些弹性。
class GameCharacter;
int defaultHealthCalc(const GameCharacter &gc);//缺省算法
class GameCharacter{
public:
typedef int (*HealthCalcFunc)(const GameCharacter &);
explicit GameCharacter(HealthCalcFunc hcf = defaultHealthCalc):healthFunc(hcf){}
int healthValue() const{
return healthFun(*this);
}
private:
HealthCalcFunc healthFunc;
};
同一人物类型不同实体可以有不同的健康计算函数,定义一个新任务类型EvilBadGuy继承GameCharacter可以在构造EvilBadGuy时候传入一个满足HealthCalcFunc函数指针格式的其他健康指数计算函数
3.将虚函数替换为std::tr1::function成员变量,个人理解这个和2类似,只不过将函数指针泛化了,可以使用函数指针也可以使用函数对象甚至是lambda表达式。这也是策略(Strategy)模式的一种形式
class GameCharacter;
int defaultHealthCalc(const GameCharacter &gc);//缺省算法
class GameCharacter{
public:
typedef std::tr1::function<int (const GameCharacter &)> HealthCalcFunc;
explicit GameCharacter(HealthCalcFunc hcf = defaultHealthCalc):healthFunc(hcf){}
int healthValue() const{
return healthFun(*this);
}
private:
HealthCalcFunc healthFunc;
};
4.将虚函数替换成另一个体系内的虚函数,这是策略(Strategy)模式的一种传统实现手法
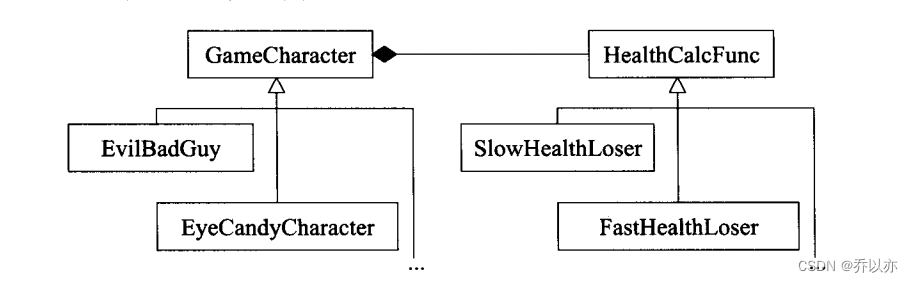
由上面类图可以看出GameCharacter派生出了EviBadGuy和EyeCandyCharacter两个类(可能还有更多),GameCharacter持有了HealthCalcFunc类的对象,HealthCalcFunc类派生出了SlowHealthLoser和FastHealthLoser(可能还有更多)。这样EviBadGuy和EyeCandyCharacter就通过继承GameCharacter也持有了HealthCalcFunc对象,那么EviBadGuy和EyeCandyCharacter两个类就可以使用HealthCalcFunc派生出来的形态
class GameCharacter;
class HealthCalcFunc{
public:
...
virtual int calc(const GameCharacter &gc) const{
//缺省算法
}
...
}
HealthCalcFunc defaultHealthCalc;
class GameCharacter{
public:
explicit GameCharacter(HealthCalcFunc* hcf = &defaultHealthCalc):pHealthFunc(hcf){}
int healthValue() const{
return pHealthFunc->calc(*this);
}
private:
HealthCalcFunc *pHealthFunc;
};
总结
- 虚函数的替代方案包裹NVI手法以及策略(Strategy)设计模式的多种形式。NVI手法自身是一个特殊的Template Method设计模式。
- 将功能从成员函数移到类外部带来一个缺点就是无法使用类内的protected和private成员
- std::tr1::function对象的行为就像一般函数指针。但是比一般函数指针兼容性更强。
条款36:绝不重新定义继承而来的非虚函数
class Base{
public:
virtual void fun(){
std::cout<<"Base fun"<<std::endl;
}
};
class Derived:public Base{
public:
virtual void fun()override{
std::cout<<"Derived fun"<<std::endl;
}
};
int main(int argc, char *argv[]) {
Base *b=new Derived();
Derived *d=new Derived();
b->fun ();
d->fun ();
}
输出为:
Derived fun
Derived fun
class Base{
public:
void fun(){
std::cout<<"Base fun"<<std::endl;
}
};
class Derived:public Base{
public:
void fun(){
std::cout<<"Derived fun"<<std::endl;
}
};
int main(int argc, char *argv[]) {
Base *b=new Derived();
Derived *d=new Derived();
b->fun ();
d->fun ();
}
输出为:
Base fun
Derived fun
通过上面两个例子可以看出如果派生类重新定义了一个非虚函数会导致调用的函数是定义的指针类型的成员函数而不是实际指针所指向对象的成员函数,如果派生类想要重写基类的函数为什么将该函数声明成虚函数呢,前面条款32说过public继承意味着is-a的关系,那么派生类就是基类已经有了基类的方法为什么还要重写一个呢?基类的public非虚函数意味着是一个不变的功能那么就不要试图在派生类重写他,否则为什么不声明成虚函数?无论从哪一观点派生类都不应重写基类的非虚函数
总结
绝对不要重新定义继承而来的非虚函数
条款37:绝不定义继承而来的缺省参数值
在满足条款36的前提下,该条款就局限于绝不定义继承而来的带有缺省参数的虚函数。
虚函数是动态绑定的,但是缺省参数确是静态绑定的
class Base{
public:
virtual void fun(int a=10){
std::cout<<"Base fun:a="<<a<<std::endl;
}
};
class Derived:public Base{
public:
virtual void fun(int a=20)override{
std::cout<<"Derived fun:a="<<a<<std::endl;
}
};
int main(int argc, char *argv[]) {
Base *b=new Derived();
Derived *d=new Derived();
b->fun ();
d->fun ();
}
输出为:
Derived fun:a=10
Derived fun:a=20
通过上面例子输出结果可以看出,虽然基类指针(指向派生类)和派生类指针都通过动态绑定调用到了实际对象(派生类对象)的fun函数但是他们的默认参数值却不同,这就是因为默认参数采用的是静态绑定(在编译期就确定了默认参数的值),这就导致了基类指针(指向派生类)调用的函数虽然是派生类的函数但是默认参数却变成了基类的默认参数。就算派生类和基类的默认参数相同也不要这么写,因为如果某一天想修改默认参数会照成不必要的麻烦。
当你想令虚函数表现出想要的行为但是遇到了困难,可以考虑替代设计。按照条款35中替代设计的一种NVI实现的代码如下:
class Base{
public:
void doFun(int a=10){
fun(a);
}
private:
virtual void fun(int a){
std::cout<<"Base fun:a="<<a<<std::endl;
}
};
class Derived:public Base{
private:
virtual void fun(int a)override{
std::cout<<"Derived fun:a="<<a<<std::endl;
}
};
int main(int argc, char *argv[]) {
Base *b=new Derived();
Derived *d=new Derived();
b->doFun ();
d->doFun ();
}
输出为:
Derived fun:a=10
Derived fun:a=10
因为基类的非虚函数是不应该被重写的(条款36)这个设计很明确的指定了参数的默认值
总结
绝对不要重新定义一个继承而来的缺省参数值,因为缺省参数都是静态绑定的,而虚函数确是动态绑定的,你唯一应该重新定义的东西应该是动态绑定的。
条款38:通过复合塑模出has-a或“根据某物实现出”
其实这个条款没有什么可说的,讲的就是两个类之间是用继承还是复合取决于两个类之间的关系是is-a还是has-a,has-a也可以理解为通过某物实现出(A类持有B类对象就可以说AB是复合关系也就是has-a,A类是根据B类实现出的)
总结
- 复合的意义和public继承完全不同
- 在应用域,复合意味着has-a(有一个)。在实现域,复合意味着是根据某物实现出来的。
条款39:明智而审慎地使用private继承
public继承意味着is-a的关系,因为调用者可以通过派生类调用基类的public方法,派生类就是基类的一种特例形式,而private继承意味着基类的所有public方法都无法被外界调用,但是可以被派生类自己使用,相当与has-a的关系,可以理解为派生类是通过基类实现出来的,这和条款38中复合的情况类似。
class Timer{
public:
explicit Timer(int tickFrequency);
virtual void onTick()const;//定时器每滴答一次该函数就会被调用一次
...
};
假设你要实现的类中需要一个定时器的功能,恰好代码库中存在一个已经实现的定时器如上所示,那么你实现的类可以考虑继承Timer,但是又不想被外面调用到onTick方法所以不能使用public继承,因为这个只是自己的类内部使用所以你选择了private继承。其实也可以选择一种public继承加复合的方式实现如下:
class Widget{
private:
class WidgetTimer:public Timer{
public:
virtual void onTick()const;
...
}
WidgetTimer timer;
}
这种方式只比private继承复杂一些,因为他导入了一个private的内部类来public继承Timer。这样做Widget的派生类无法看到Widget中timer相关的内容,如果想降低程序的依存关系可以将WidgetTimer独立出来这样Widget可以不用看到Timer相关的内容。
当然如果你的程序对内存消耗非常敏感那么可以使用private继承。
class Empty{};
class HoldsAnInt{
private:
int x;
Empty e;
};
你会发现sizeof(HoldsAnInt)>sizeof(int),因为虽然Empty是个空类,但是通常C++官方会默默安插一个char到空对象内(独立对象的大小一定不为0),而基于内存对其的原则这个char的大小很可能被放大成一个int
这时候使用private继承就可以达到节省空间的作用
class HoldsAnInt : private Empty{
private:
int x;
}
sizeof(HoldsAnInt) == sizeof(int),这就是所谓的EBO(emptybase optimization;空白基类最优化),但是EBO一般只在单一继承下才行。现实中Empty类并不一定为空,往往内涵typedefs , enums, static成员变量或是非虚函数,STL中有许多技术用途的empty classes。
总结
- private继承意味着has-a(根据某物实现),和复合意义类似,但是他的优先级比复合低,但是当派生类需要访问受保护的基类成员或者需要重新定义继承而来的虚函数时,这么定义是合理的。
- 和复合不同,private继承可以造成empty base最优化,这对于需要极致空间优化的开发者而言很重要。
条款40:明智而审慎的使用多重继承
多重继承一个派生类继承多个基类如果在多个基类中有方法名相同的有可能导致歧义,这时必须指定哪个基类的方法。多重继承每个基类都要指定继承的访问权限
class Base1{
public:
void fun(){}
};
class Base2{
public:
void fun(){}
};
class Derived:public Base1, public Base2{
};
int main(int argc, char *argv[]) {
Derived d;
d.Base1::fun();//必须指定哪个基类的方法
}
书中举例InputFile和OutputFile继承了File,而IOFile又继承了InputFile和OutputFile,以上继承全部采用public继承,此时InputFile和OutputFile内部都有一个File基类的内容,如果IOFile继承了InputFile和OutputFile那么就会有两个FIle基类内容,这并不是我们想要的。为了解决这一问题就出现了虚继承
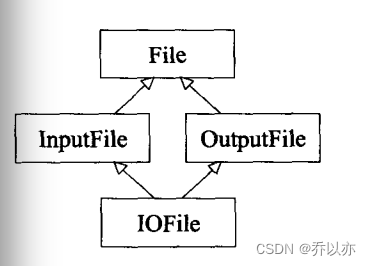
虚继承如下:
class File{};
class InputFile:virtual public File{};
class OutputFile:virtual public File{};
class IOFile:public InputFile,public OutputFile{};
这样IOFile中就只有一份File基类中的内容了,但是引入了虚继承会导致派生类的体积变大,访问虚基类的成员变量也会变慢,所以编译器虽然解决了多重继承导致的基类重复问题,同时也牺牲了一定的空间和性能。这里建议非必要不使用虚继承,如果必须使用虚继承,尽量不要在虚基类中放置数据(将虚基类设置的类似java中Interfaces那样的纯接口类)
书中还介绍了一种多重继承情况如下:
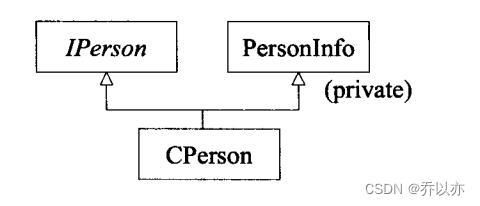
class IPerson{};
class PersonInfo{};
class CPerson:public IPerson,private PersonInfo{};
CPerson是IPerson的一种(is-a这种使用public继承),然后CPerson的构建依赖PersonInfo(has-a这种可以使用复合或者private继承这里为了介绍多重继承采用private继承,当然本人更推荐使用复合)。上面这种情况是一个符合使用多重继承的一种情况。
对于多重继承非必要不使用虚继承,普通的多重继承具体情况具体分析,如果使用多重继承就可以让项目更加简洁,更加便于维护,理解也十分合理,那么请放心大胆的使用多重继承。只要你确定你是在明智而审慎的使用他。
总结
- 多重继承比单一继承复杂,他可能有歧义性,特殊时候还需要虚继承
- 虚继承会增加派生类的大小,降低派生类访问基类成员的效率,初始化赋值都需要复杂的成本。如果虚基类不带有任何成员(数据)将是最实用的情况
- 多重继承也有正当的用途。其中一中情况是public继承某个interface class,private继承协助实现派生类,这两种情况结合的场景
第七章:模板与泛型编程
条款41:了解隐式接口和编译期多态
面向对象编程总是以显示接口和运行时多态解决问题,泛型编程与面向对象上根本的不同在于,在泛型编程中显示接口和运行时多态仍然存在,但重要性降低。反而隐式接口和编译器多态移到了前头。泛型编程并没有清楚的指定类而是指定了类中的一系列方法(在函数模板中使用到的方法),如果这个类支持这些方法,那么这个函数模板就适用于这个类,stl中有很多方法都是多个容器公用的就是这个原理,因为这些容器都支持那些函数模板中用到的方法。如果函数模板中用到了一些运算符(>,<,!=,==,…)比较了一些不同的类也可以通过重载运算符实现一些功能。
总结
- 类和模板都支持接口和多态
- 类的接口是显示的,以函数签名为中心,多态是通过虚函数发生于运行期间
- 对模板参数而言,接口是隐式的,奠基于表达式,多态是通过模板具现化和函数重载解析发生于编译期间
条款42:了解typename的双重意义
template<class T> class Widget;
template<typename T> class Widget;
上面这种情况使用class和typename完全相同。下面介绍下typename的特别用处,下面代码是书中的例子
template<typename C>
void print2nd(cibst C&container){
if(container.size()>=2){ //取容器的第二个元素
C::const_iterator iter (container.begin());
++iter;
int value = *iter;
std::cont<<value;
}
}
template 内出现的名称如果相依与某个template参数,称之为从属名称,如果从属名称在class内呈现嵌套状,我们称之为嵌套从属名称。C::const_iterator就是一个嵌套从属名称。 函数模板中的 int value中int类型不依赖template参数的名称,我们称之为非从属名称。上面的代码无法编译通过是因为嵌套从属名称前面必须加上typename 用来告诉编译器这个嵌套从属名称是一个类型。因为如果明确告诉编译器,可能会导致编译器的误解,下面看例子
template<typename C>
void print2nd(const C&container){
C::const_iterator *x;
}
如果C这个类里面有个静态变量const_iterator。这个代码是不是也可以解析成C中的const_iterator变量乘以x,这会导致编译器无法分辨出C::const_iterator是一个类型还是一个变量。因此加上typename明确告诉编译器他是一个类型。但是typename也不是可以随便加在前面的
template<typename C>
void fun(){
C x;
}
这种只是用C这个类型没有任何从属嵌套时就不要在前面加typename,增加typename反而会导致编译出错。
通过上面讲解大家已经了解了什么时候使用typename,下面看个例子看看是否会改变一些对typename使用的认知
template<typename T>
class Derived:public Base<T>::Nested{ //不使用typename
public:
explicit Derived(int x):Base<T>::Nested(x){//不使用typename
typename Base<T>::Nested temp;//使用typename
}
}
从上面可以看出T作为一个类型单独使用的时候是不需要加typename,比如单独传给Base<T>。当T作为嵌套从属类型Base<T>::Nested的时候需要加typename。
有时候typename 后面这个类型又很长这时可以使用typedef给他起个别名
template<typename T>
void workWithIterator(T iter){
typedef typename std::iterator_traits<T>::value_type ValueType;
ValueType t(*iter);
}
许多人可能觉得typedef typename看着不和谐,如果你原因使用用那么长的类型也可以不使用typedef
这里就是typename的一些使用方法,虽然class在某些时候可以代替typename,但我依然建议在使用模板时候我们只是用typename。书中还说了编译器对typename的支持性不是很一致,这就导致可能移植性给你带来一些烦恼。
总结
- 声明template参数时,前缀关键字class和typename可以互换(但是个人建议只使用typename)
- 请使用关键字typename标识嵌套从属类型名称
条款43:学习处理模板化基类内的名称
首先介绍下模板的编译流程:
如果编码时使用了模板那么他的编译阶段可以分为两个阶段,模板定义阶段和模板实例化阶段。
在模板定义阶段只对模板中和模板参数无关的名字进行查找(无视那些有模板参数的部分)。由于父类是模板类,所以在编译的时候那些和泛型扯相关的东西会被忽略掉;在模板实例化阶段编译器主要处理带模板参数的部分,所有和模板相关的操作都在该阶段完成。
因此以模板类作为基类时,在派生类中我们一定要明确告诉编译器哪个成员是模板基类中的,这样编译器在第一阶段就会忽略掉,在第二阶段才会进行检查(因为它以来模板在第一阶段还不知道模板具体是什么)。但是如果你不明确告诉编译器这个成员涉及到模板他就会在第一阶段进行检查,这时就会报错(因为模板是依赖第二阶段的)。
class Base{
public:
void funb(int a){
T t;
printf("Base funb\n");
}
};
template<typename T>
class Derived:public Base<T>{
public:
void fund(int a){
// this->funb(a); //可以编译通过
// Base<T>::funb(a); //可以编译通过
// funb(a); //编译报错,因为没有明确告诉编译器funb涉及到模板,因此在第一阶段没有忽略掉找不到实现报错
printf("Derived fund\n");
}
};
int main(int argc, char *argv[])
{
Derived<int> d;
d.fund(10);
return 0;
}
总结
可以在以模板类为基类的派生类内通过"this->"或者使用基类限定修饰符来告诉编译器这个成员依赖模板。
条款44:将与参数无关的代码抽离templates
模板在具现化的时候会根据模板参数不同生成不同的函数,往往这正是我们所期望的,但是如果在模板参数中夹杂着一些固定类型如:
template<typename T,std::size_t n>
class SquareMatrix{
...
void invert();
};
如果你在使用这个模板类的时候这样使用想想会出现什么后果:
SquareMatrix<double,5> sm1;
sm1.invert();
SquareMatrix<double,10> sm2;
sm2.invert();
上面代码会具现化两份invert,这些函数并非完完全全相同因为他们的size_t一个是5一个是10。但是两个函数其他部分相同,这就会导致代码膨胀,效率降低。
参考文献《Effective C++》中文版第三版















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









