







在《携程技术2018年度合集》中,一共70篇文章中,只有5篇是大数据的内容。其中有一篇,讲到了Alluxio的应用过程。
在2018年,携程主集群规模已经突破千台,存储着50PB的数据,并且每天的数据增量大概是400TB。每天的作业数也达到了30万。
当时,携程使用的Spark Streaming实时任务,会将结果数据直接写入到HDFS中,400个流作业每天带来500万小文件的落地,虽然会有任务定期进行小文件合并,但巨大的增量为HDFS集群带来了很大的压力。
并且对于HDFS进行停机优化,又会导致大量流作业出错。
于是,在下一版的架构中,为SparkStreaming单独部署了一个Hadoop集群,与离线集群的HDFS分离开来。
这也造成了两个HDFS之间数据不同步的问题。当然,可以定时执行distcp进行数据拷贝,但实现起来会有很多问题。
除此之外,能够实现多集群数据互通的产品,必须是Apache Alluxio。
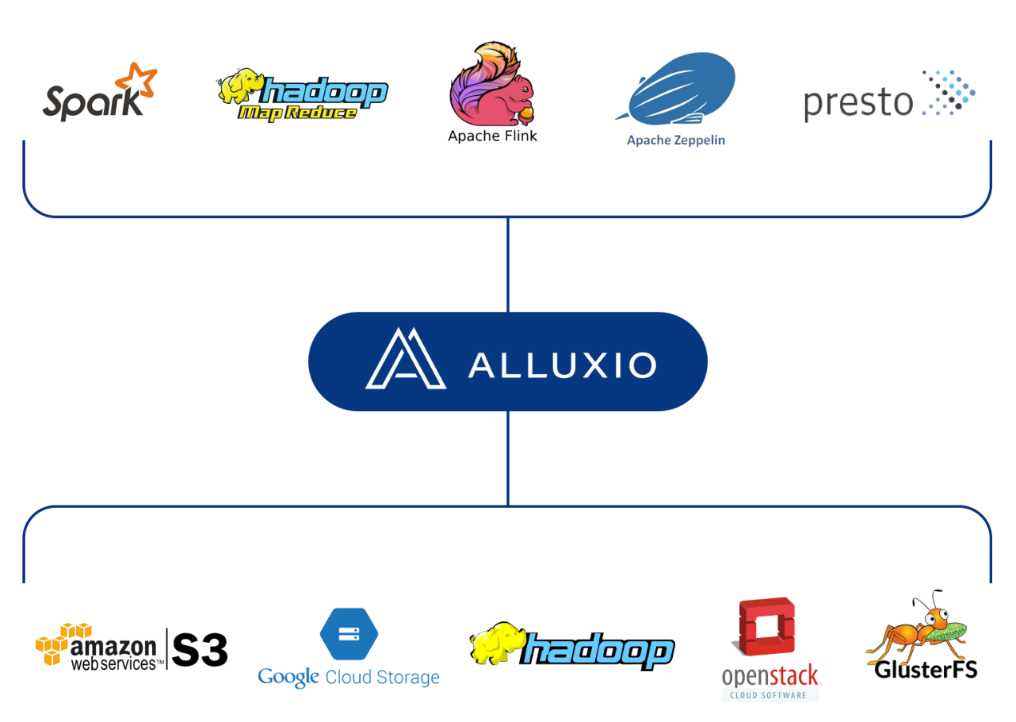
Alluxio 作为全球第一个基于内存级别的文件系统,具有高效的读写性能,同时能够提供统一的 API 来访问不同的存储系统。
Alluxio 可以支持目前几乎所有的主流分布式存储系统,可以通过简单配置或者 Mount 的形式将 HDFS、S3 等挂载到 Alluxio 的一个路径下。
alluxiofs mount /path/on/alluxio hdfs://namenode:port/path/on/hdfs
这样就可以统一的通过 Alluxio 来访问不同存储系统的数据。
对于经常使用的热点数据,可以使用定时器,定期Load到Alluxio中,减少了每次计算需要从远程拉取数据的所导致的网络 IO,并且因为Alluxio的数据存储在内存中,也极大的提高了运算效率。
从 Alluxio 内存中加载数据的Spark SQL作业,和HDFS相比,普遍提高了 30% 的执行效率。
此外,Alluxio 自身实现了一个叫做 TTL(Time To Live)的功能,只要对一个路径设置了 TTL,Alluxio便会定期删除这部分数据。
在删除方式上,Alluxio 提供了 Free 和 Delete 两种 Action。Delete 会将底层文件一同删除,Free 只删 Alluxio 而不删底层文件系统。
为了减少 Alluxio 内存压力,可以将写入到 Alluxio 中的数据设置一个 TTL,使用Free Action,这样 Alluxio 会自动将过期数据删除。
并且,Alluxio 为 Client 提供了三种写策略,分别是:MUST_CACHE、CACHE_THROUGH、THROUGH,这三种策略分别是只写 Alluxio,同步到 HDFS,只写 HDFS。
这里可以根据数据的重要性,采用不同的策略来写 Alluxio。重要的数据需要同步到 HDFS,允许数据丢失的可以采用只写 Alluxio 策略。
所以,之后携程将Alluxio,作为两个HDFS集群之间数据互通的桥梁,在生产环境中落地了。
如果大家所在公司,也遇到了同样的需求,也可以尝试一下Alluxio。
好了,今天就分享到到这里,让我们下次再会!
后话
在公众号《数舟》中,可以免费获取专栏《数据仓库》配套的视频课程、大数据集群自动安装脚本,并获取进群交流的途径。我所有的大数据技术内容也会优先发布到公众号中。如果对某些大数据技术有兴趣,但没有充足的时间,在群里提出,我为大家安排分享。
公众号自取:

















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











