







 超级会员免费看
超级会员免费看
表的高级操作:倾斜表&事务表
Hive倾斜表(Skewed Tables)
什么是倾斜表?
对于一列或多列中出现倾斜值的表,可以创建倾斜表(Skewed Tables)来提升性能。比如,表中的key字段所包含的数据中,有50%为字符串”1“,那么这种就属于明显的倾斜现象;于是在对key字段进行处理时,倾斜数据会消耗较多的时间。
此时可以创建Skewed Tables,对倾斜数据在元数据中进行标注,从而优化查询和join性能。
例如,创建倾斜表skewed_single,包含两个字段key、value;其中key字段包含的数据中,1、5、6出现了倾斜;创建SQL如下:
CREATE TABLE skewed_single (key STRING, value STRING)
SKEWED BY (key) ON ('1','5','6')
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
--向表中插入数据
insert OVERWRITE table skewed_single values('1','1'),('2','2'),('3','3'),('4','4'),('5','5'),('6','6'),('1','1'),('5','5'),('6','6'),('1','1'),('5','5'),('6','6'),('1','1'),('5','5'),('6','6'),('1','1'),('5','5'),('6','6');
除了单个字段之外,也可以对多个字段的倾斜值进行标注:
CREATE TABLE skewed_multiple (key STRING, value STRING)
SKEWED BY (key, value) ON (('1','One'), ('3','Three'), ('5','Five'))
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
--插入数据
insert OVERWRITE table skewed_multiple values('1','One'),('2','One'),('3','One'),('4','One'),('5','One'),('6','One'),('1','Two'),('5','Two'),('6','Two'),('1','Three'),('2','Three'),('3','Three'),('4','Three'),('5','Three'),('6','Three'),('1','Four'),('5','Four'),('6','Four'),('5','Five'),('6','Four');
Optimizing Skewed Joins
倾斜表创建后,会产生Optimizing Skewed Joins(倾斜连接优化)效果。假设表A id字段有值1,2,3,4,并且表B也含有id列,含有值1,2,3。我们使用如下语句来进行连接。
--这里只做讲解说明,并没有创建A、B两表
select A.id from A join B on A.id = B.id
此时将会有一组mappers读这两个表并基于连接键id发送到reducers,假设id=1的行分发到Reducer R1,id=2的分发到R2等等,这些reducer对A和B进行交叉连接,R4从A得到id=4的所有行,但是不会产生任何结果。
现在我们假定A在id=1上倾斜,这样R2和R3将会很快完成但是R1会执行很长时间,因此成为job的瓶颈。若是提前知道这些倾斜信息,这种瓶颈可以使用如下方法人工避免:
--首先进行Join,排除倾斜数据A.id=1
select A.id from A join B on A.id = B.id where A.id <> 1;
--单独对倾斜数据进行Join
select A.id from A join B on A.id = B.id where A.id = 1 and B.id = 1;
但这种方式需要人为干预,提前知道倾斜值,且要执行两次Join操作。但如果表A是Skewed Tables,A.id=1被设置为倾斜值,那么在执行表A与表B的Join操作时,会自动进行以下优化:
- 将B表中id=1的数据加载到内存哈希表中,分发到A表的所有Mapper任务中,直接与A.id=1的数据进行Join。
- 其余非倾斜数据,执行普通Reduce操作,进行Join。
这样会提高在倾斜数据中的Join执行效率。
List Bucketing
List Bucketing是一种特殊的Skewed Tables,它会将倾斜数据保存到独立目录中,更有效的提高查询、Join效率。List Bucketing创建过程较为简单,只需要在Skewed Tables创建语法中指定STORED AS DIRECTORIES即可。
经过测试,在Hive版本(1.2.1)中List Bucketing还存在很多无解的BUG问题,无法被拆分为独立目录进行存储,但在较新的版本(2.3.7)中可以正常运行。如果你当前的版本,存在一些支持上的问题,那么对于以下代码不需要去执行,只做了解即可。
例如,创建List Bucketing表:list_bucket_single,它包含两个字段key、value;其中key字段包含的数据中,1、5、6出现了倾斜;创建SQL如下。
--这里对表进行了分区处理,当然在2.3.7版本中不分区也可以,在较早的一些版本中会有问题
CREATE TABLE list_bucket_single (key STRING, value STRING)
partitioned by (dt string)
SKEWED BY (key) ON (1,5,6) STORED AS DIRECTORIES
STORED AS ORCFile;
--向表中插入数据
insert OVERWRITE table list_bucket_single
partition (dt='2020-11-19')
select * from skewed_single;
此时,它会创建4个目录(3个目录对应key的3个倾斜值,另外一个目录是其余值)。这个表的数据被分成了4个部分:1,5,6,others
hadoop fs -ls /user/hive/warehouse/list_bucket_single/dt=2020-11-19

这样的话,对于倾斜较高的key值的查询,便会有很好的效率提升。
当然,List Bucketing表也支持对多个字段的倾斜值进行标注:
CREATE TABLE list_bucket_multiple (key STRING, value STRING)
partitioned by (dt string)
SKEWED BY (key, value) ON (('1','One'), ('3','Three'), ('5','Five')) STORED AS DIRECTORIES
STORED AS RCFile;
--向表中插入数据
insert OVERWRITE table list_bucket_multiple
partition (dt='2020-11-19')
select * from skewed_multiple;
此时,它会创建4个目录(3个目录对应(‘1’,‘One’), (‘3’,‘Three’), (‘5’,‘Five’)3个组合倾斜值,另外一个目录是其余值)。但目前Hive对多字段倾斜值的实现还存在些问题,不管是1.2.1还是2.3.7版本都只有HIVE_DEFAULT_LIST_BUCKETING_DIR_NAME单个目录。
倾斜表的DDL操作
对于以创建的倾斜表Skewed Tables,可以使用alert table语句来修改倾斜信息,也可以将普通表转化为Skewed Tables:
ALTER TABLE <T> (SCHEMA) SKEWED BY (keys) ON ('c1', 'c2') [STORED AS DIRECTORIES];
当然也可以将Skewed Tables修改为普通表:
ALTER TABLE <T> (SCHEMA) NOT SKEWED;
或者将List Bucketing表转换为普通Skewed Tables:
ALTER TABLE <T> (SCHEMA) NOT STORED AS DIRECTORIES;
支持对倾斜值的存放目录进行修改:
--语法格式
ALTER TABLE <T> (SCHEMA) SET SKEWED LOCATION (key1="loc1", key2="loc2");
--将list_bucket_multiple表的组合倾斜值('1','One')、('3','Three')存放目录进行更改
ALTER TABLE list_bucket_multiple SET SKEWED LOCATION (('1','One')="hdfs://node01:9000/file/one_data" ,('3','Three')="hdfs://node01:9000/file/one_data");
当然这些修改,不会对之前的数据产生影响,仅对修改之后的表数据生效。
Hive事务表(ACID)
Hive在0.13之后,支持行级别的ACID语义,即Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)、Durability(持久性)。行级别的ACID意味着,在有其它程序在读取一个分区数据的同时,可以往这个分区插入新的数据。支持的操作包括 INSERT/UPDATE/DELETE/MERGE 语句、增量数据抽取等。
在3.0版本之后,又对该特性进行了优化,包括改进了底层的文件组织方式,减少了对表结构的限制,以及支持条件下推和向量化查询等。
但事务功能仅支持ORC表,而且事务功能依赖分桶的存储格式,所以事务表必须进行分桶操作。
Hive开启事务配置
默认情况下事务是非开启状态的。在开启事务前,需要集群进行一些配置(使用脚本安装Hive后,已经自动完成配置)。
对于Hive服务端(MetaStore),需要在hive-site.xml中添加以下配置:
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
<description>
开启事务必要配置:是否在Metastore上启动初始化和清理线程
</description>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>3</value>
<description>
开启事务必要配置:压缩时,启动的worker线程数
</description>
</property>
服务端配置好后,此时就可以创建事务表了。但Hive不允许非ACID的会话对事务表进行操作。那么就需要开启客户端的ACID功能,这里即对hiveserver2进行事务配置。配置项可以直接添加到hive-site.xml中,也可以在执行SQL时使用set命令进行临时设置。这里为了方便起见,直接添加到hive-site.xml中。
<property>
<name>hive.support.concurrency</name>
<value>true</value>
<description>
开启事务必要配置:HiveServer2 Client配置,是否允许并发
</description>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
<description>
开启事务必要配置:HiveServer2 Client配置,提供事务行为
</description>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
<description>
开启事务必要配置:HiveServer2 Client配置,开启自动分桶
在2.x之后不需要进行配置,为了兼容之前版本添加此参数
</description>
</property>
配置完成后,在Hive安装节点(Node03),重启Hive:
# 停止hiveserver2和metastore服务
jps | grep RunJar | awk '{print $1}' | xargs kill -9
# 重新启动hiveserver2和metastore服务
hive --service hiveserver2 &
hive --service metastore &
启动beeline客户端:
beeline -u jdbc:hive2://node03:10000 -n root
官方建议开启非严格模式,严格模式会禁止一些比较危险的SQL执行。
set hive.exec.dynamic.partition.mode=nonstrict;
事务表的创建
首先对事务表进行创建,首先需要是ORC表,然后进行分桶,并在表中添加属性’transactional’ = ‘true’。
CREATE TABLE employee (id int, name string, salary int)
CLUSTERED BY (id) INTO 2 BUCKETS
STORED AS ORC
TBLPROPERTIES ('transactional' = 'true');
事务表创建完成后,插入部分数据:
INSERT INTO employee VALUES
(1, 'Jerry', 5000),
(2, 'Tom', 8000),
(3, 'Kate', 6000);
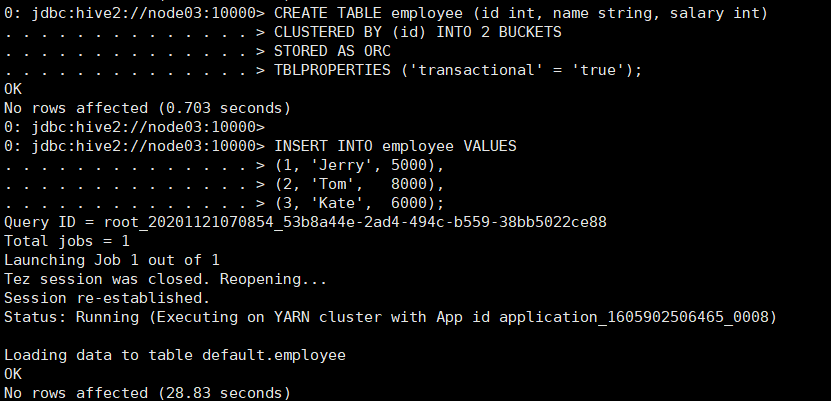
插入数据后,可以查看事务表在HDFS上的存放情况:
hadoop fs -ls -R /user/hive/warehouse/employee

在HDFS上的事务表,其实包含两种类型的文件:base文件、delta文件。
其中delta文件,用来存储新增、更新、删除的数据。每一个事务处理数据的结果都会单独新建一个delta目录用来存储数据,目录下存储的数据按照桶进行划分。而base文件,则用来存放平常的数据。Hive会定期执行任务,将delta文件合并到base文件中。
现在可以看到HDFS中只包含delta文件,是因为delta文件还没有合并到base中。
假设有一张表名为t,分桶数量只有2的表,那它的文件结构应该是下面这种形式。
hive> dfs -ls -R /user/hive/warehouse/t;
drwxr-xr-x - ekoifman staff 0 2016-06-09 17:03 /user/hive/warehouse/t/base_0000022
-rw-r--r-- 1 ekoifman staff 602 2016-06-09 17:03 /user/hive/warehouse/t/base_0000022/bucket_00000
-rw-r--r-- 1 ekoifman staff 602 2016-06-09 17:03 /user/hive/warehouse/t/base_0000022/bucket_00001
drwxr-xr-x - ekoifman staff 0 2016-06-09 17:06 /user/hive/warehouse/t/delta_0000023_0000023_0000
-rw-r--r-- 1 ekoifman staff 611 2016-06-09 17:06 /user/hive/warehouse/t/delta_0000023_0000023_0000/bucket_00000
-rw-r--r-- 1 ekoifman staff 611 2016-06-09 17:06 /user/hive/warehouse/t/delta_0000023_0000023_0000/bucket_00001
drwxr-xr-x - ekoifman staff 0 2016-06-09 17:07 /user/hive/warehouse/t/delta_0000024_0000024_0000
-rw-r--r-- 1 ekoifman staff 610 2016-06-09 17:07 /user/hive/warehouse/t/delta_0000024_0000024_0000/bucket_00000
-rw-r--r-- 1 ekoifman staff 610 2016-06-09 17:07 /user/hive/warehouse/t/delta_0000024_0000024_0000/bucket_00001
在用户进行数据读取时,会将base文件和delta文件读取到内存中,判断哪些数据进行了修改和更新,然后合并成最新的数据。
事务表创建完成后,可以进行行级别的数据更新操作。
UPDATE employee SET salary = 7000 WHERE id = 2;
也可以进行行级别的数据删除:
delete from employee where id=1;
但每次追加、更新、删除,都会生成新的delta目录,用于存放delta文件。所以性能上并不出色。
对于事务表,可以查看所有正在进行的事务操作:
SHOW TRANSACTIONS;
事务表的压缩
随着对事务表的操作累积,delta文件会越来越多,事务表的读取会遍历合并所有文件,过多的文件数会影响效率。而且小文件数量也会对HDFS造成影响。因此Hive支持文件压缩(Compaction)操作,分为Minor和Major两种。
Minor Compaction会将所有的delta文件合并到一个delta目录中并进行分桶存储,会定期在MetaStore中执行。当然也可以手动触发:
ALTER TABLE employee COMPACT 'minor';
Minor Compaction只是单纯的文件合并,不会删除任何数据,能够减少文件数量。
而Major Compaction则会将所有文件合并为base文件,以base_N命名。base_N中只会保留最新的数据。Major Compaction也会定期执行,不支持手动触发。Major Compaction会消耗较多的集群资源。
对于执行过程中的压缩任务,可以使用命令查看:
SHOW COMPACTIONS;

















 2439
2439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











