







换盘预测
论文:《Predicting Disk Replacement towards Reliable Data Centers》
作者:Mirela Botezatu,IBM苏黎世研究院
1.介绍
目标:
1)找到对换盘事件最相关的SMART属性。
2)用这些属性构建统计模型,自动预测下一次换盘事件。
方法:
1)时间序列的变化点侦测,识别相关SMART属性。
2)把事件序列转换成样本集合,通过把多个事件编码成单独的数据点,从而得到压缩过,但是有价值的特征。
3)构建预测分类模型
4)用迁移学习方法
问题:
1)不同厂商的SMART属性不同,需要为厂商单独建立模型。
2)磁盘数据不均衡,只有2%需要更换。
2.预测换盘
算法1 磁盘更换预测算法
输入:SMART属性时间序列,加上换盘信息
1. 找到指示换盘的SMART属性子集,通过在时间序列中识别显著变化点。
2. 对步骤1得到的每个相关序列,通过指数平滑,得到高度信息的压缩表示。
3. 通过K-means聚类,进行downsampling,来处理类别间不均衡问题。
4. 用步骤3的训练数据训练一个分类模型
输出:用小规模SMART属性可以预测换盘事件的预测模型。
2.1.选择相关SMART属性
表示目标SMART属性的时间序列,包含p个时间点的数据,p是最近时间点。
用【7】的方法侦测中的显著变化时间点t。总结而言,
使得:
这里的:

下一步,验证这个变化是不是永久性的,看如下两个时间序列的差异是不是显著:一个是现有的SMART属性序列,另一个是相同属性序列,但是去掉观察到的t时刻的显著变化。具体步骤如下:
第一步,令时间序列
表示观察到的中从t到p的子序列。P时间点表示换盘时间点。
第二步,生成一个合成时间序列
除去了t时刻的显著变化点。更确切说,我们用贝叶斯结构时间序列模型计算的后验分布,
给定t时刻前的未变化序列,以及控制时间序列。控制时间序列是从健康磁盘采样得到的时间序列。
最后,目标SMART属性的确是换盘指示属性,如果变化点后面的实际时间序列的概率分布,与从健康磁盘生成的合成序列的分布显著不同。通过假设检验来估计这种区别。
形式化的,令和是从未知分布P和Q分别生成的。假设检验下述:

我们检查我们是否可以抛弃零假设。
2.2.压缩时间序列表示
1)按天的观察还不够,我们需要考虑更长的时间窗口。因为磁盘内部有恢复机制,造成单独一天的记录不够稳定。
2)如果我们考虑到磁盘生命周期的最后一天,模型不能提前预测。
我们用滑动窗口,把原始数据集合划分成小节。在时间窗口上用指数平滑,变成一个值。

上述公式中,作为时刻t平滑值,基于t时刻的观测值,和t-1时刻的平滑值。当把窗口宽度扩展为k,成为一定数量的直到的过去观测值的加权和。K越小,平滑效果差,但是对新的变化更敏感。参数控制老观测值衰减的速度。
对每个SMART属性,时间窗口宽度是2.1步骤中显著变化的事件区间分布的中值。
2.3.通过降采样来平衡类别
大量的盘是好盘,因此训练集是不均衡的。
解决方案是用健康磁盘的代表性子集。
用K-mean聚类算法【15】,把观察到的健康磁盘数据划分成k个聚类。
每一个聚类中,选择离聚类中心最近的数据点,作为代表性数据。
最后,我们生成一个平衡的训练集,通过选择k与坏盘样本数接近即可。
2.4. 分类算法
训练数据集:
,表示多变量时序观察信息,在时间点和之间。
y是二值响应变量,
要学习一个函数
可以最小化损失函数
选择的算法是RGF【14】。比GBDT【21】和随机森林【6】,以及SVM【8】,逻辑回归【9】的精确性更好。
- RGF引入一个明确的正则化项:
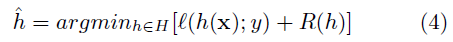
- RGF引入fully-corrective贪婪算法,迭代修改当前获得的所有叶子节点(决策规则)的权重,同时通过贪婪搜索法向森林里增加新规则。这里,一个明确的正则项加到里面,防止过拟合。
- RGF利用结构化稀疏来直接执行贪婪搜索。
算法2 正则化贪婪森林框架
While 停止标准不满足 do:
修改权重,调整森林结构s
计算
If 某种条件匹配命中 then:
修正结构,改变F中的权重,使得,Q(F)中的loss最小化。
End if
End While
优化F中的叶子权重,来最小化Q(F)中的loss
Return
结束
F表示一个森林
F中的每个节点v关联一个元组
表示节点v的basis函数
表示节点v的权重
模型F定义为
对于v的内部节点,有
公式(4)的正则损失是F的一个函数:
S(F)表示F的所有结构改变操作(如,节点分割,或者增加一个新树)
2.5. 迁移学习
用某个特定磁盘训练的模型,迁移到同厂商的新磁盘模型上。
算法3:不同模型间的迁移学习
输入:
从磁盘模型1搜集到的标记数据
从磁盘模型2搜集到的未标记数据
过程:
用来学习一个函数,f(x)表示一块磁盘属于“”或“”的概率。
根据f,从采样一个子集
用来学习一个函数,g是算法2,g(x)表示一个类型的磁盘需要更换的概率。
输出:
磁盘模型2的更换预测模型。
算法背后的想法是,训练一个分类器,可以rank相似性,介于,连接到一个特定磁盘模型的观测结果,以及预训练的目标磁盘模型的观察结果。
3. 评估
3.1.模型描述和实验建立
数据集是Backblaze数据集:https://www.backblaze.com/hard-drive-test-data.html
包含了50984块磁盘,27个月(2013年4月到2015年6月)的观察数据,以天为粒度。
数据格式:
(1)时间戳
(2)磁盘序列号
(3)磁盘模型
(4)磁盘容量
(5)失效 健康0,换盘1
(6)SMART统计数据
从磁盘模型,可以提取厂商,我们的分析基于Hitachi和Seagate两个厂商。
同时也除去了一些数据,最终数据从2014年1月到2016年6月,共17个月。
构建的磁盘模型
SgtA Seagate ST4000DM000
HitA Hitachi HDS22020ALA330
然后,我们评估迁移学习效果:
从SgtA到SgtB ST31500541AS
从HitA到HitB HDS5C3030ALA630
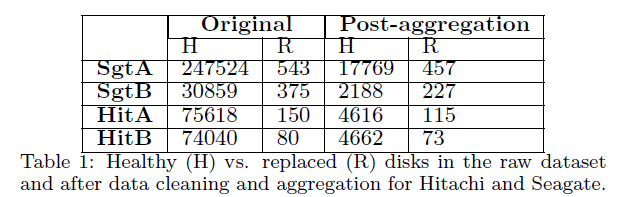
表一是数据信息:
3.2. SMART属性选择
每个SMART指示器有两个值:原始值,和正则化值。
原始值表示技术,或者物理计量值(温度、毫秒数等)
正则化值是厂商特定的映射。
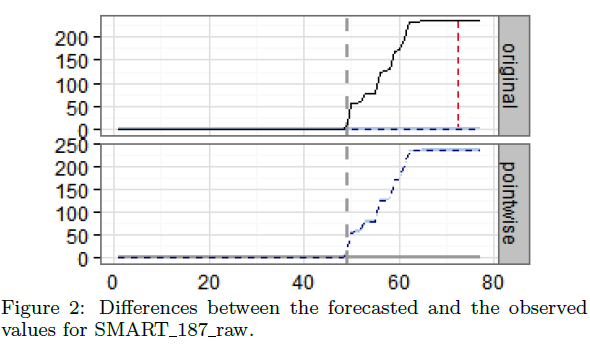
图2图示了SMART_187_raw的时间序列,SgtA磁盘,80天。
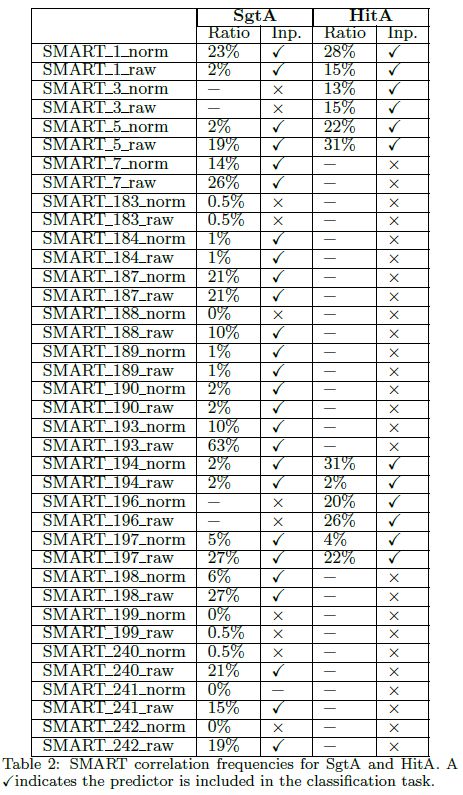
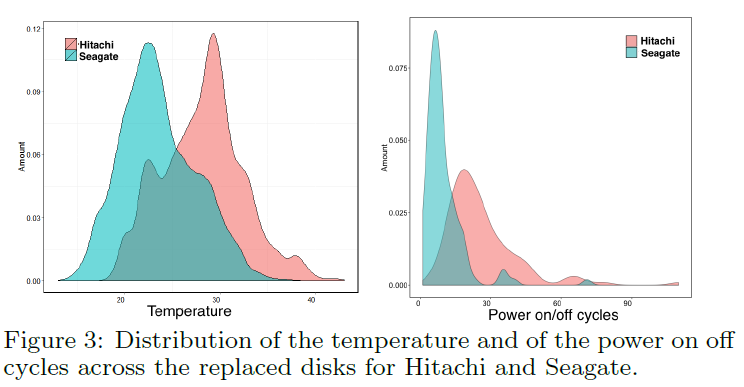
我们对希捷和日立磁盘分布做了变化点分析,结果见表2。每个参数,我们报告了磁盘数的百分比,观察到了相关。
3.3. 数据压缩
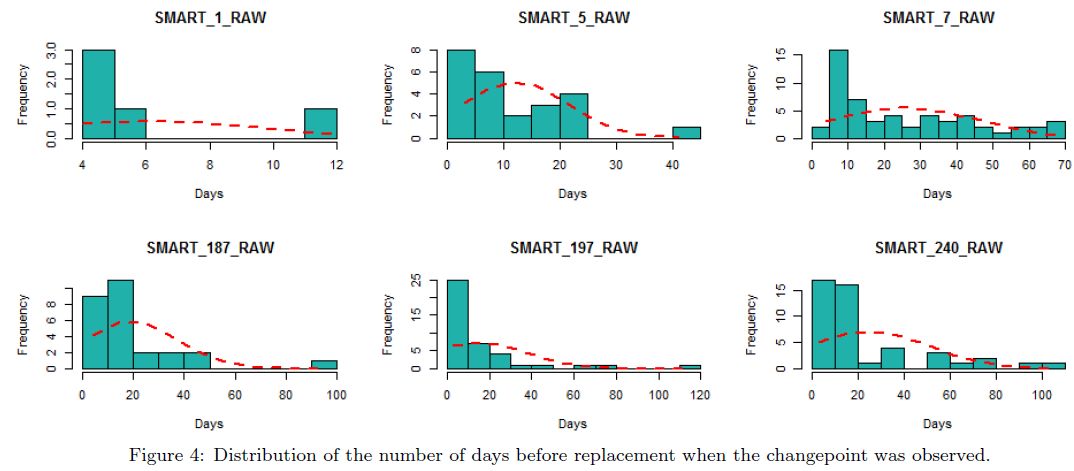
图4展示了,当6个变化点观察到了之后,换盘天数的分布
read error rate,
the number of reallocated sectors,
the number of pending sectors,
the reported uncorrectable errors,
the seek error count
the transfer error rate
我们用这些中值来做事件序列窗口。
4. 部署















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









