







1 Trie树
Trie树,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
在图示中,键标注在节点中,值标注在节点之下。每一个完整的英文单词对应一个特定的整数。键不需要被显式地保存在节点中。图示中标注出完整的单词,只是为了演示trie的原理。trie中的键通常是字符串,但也可以是其它的结构。
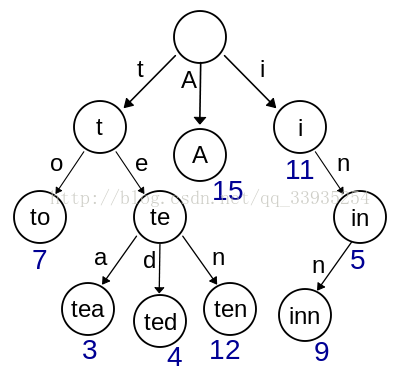
上图是一个简略视图,实际上trie每个节点是一个确定长度的数组,数组中每个节点的值是一个指向子节点的指针,最后有个标志域,标识这个位置为止是否是一个完整的字符串,并且有几个这样的字符串
常见的用来存英文单词的trie每个节点是一个长度为27的指针数组,index0-25代表a-z字符,26为标志域。如图:

2 Patricia树
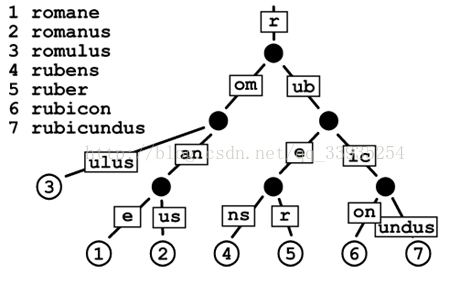
Patricia树,或称Patricia trie,或crit bit tree,压缩前缀树,是一种更节省空间的Trie。对于基数树的每个节点,如果该节点是唯一的儿子的话,就和父节点合并。
3 Merkle树
Merkle Tree,通常也被称作Hash Tree,顾名思义,就是存储hash值的一棵树。Merkle树的叶子是数据块(例如,文件或者文件的集合)的hash值。非叶节点是其对应子节点串联字符串的hash。(不懂Hash运算的可以自行百度)
要了解Merkle Tree就要先从Hash List说起:
在点对点网络中作数据传输的时候,会同时从多个机器上下载数据,而且很多机器可以认为是不稳定或者不可信的。为了校验数据的完整性,更好的办法是把大的文件分割成小的数据块(例如,把分割成2K为单位的数据块)。这样的好处是,如果小块数据在传输过程中损坏了,那么只要重新下载这一快数据就行了,不用重新下载整个文件。
怎么确定小的数据块没有损坏哪?只需要为每个数据块做Hash。BT下载的时候,在下载到真正数据之前&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









