









Unleashing the Power of Compiler Intermediate Representation to Enhance Neural Program Embeddings [ICSE 2022]
Zongjie Li, Pingchuan Ma, Huaijin Wang, Shuai Wang The Hong Kong University of Science and Technology
Hong Kong SAR
Qiyi Tang, Sen Nie, Shi Wu Tencent Security Keen Lab China
神经程序嵌入在一系列程序分析任务中已显示出相当大的前景, 包括克隆识别、程序修复、代码补全和程序合成. 然而, 大多数现有方法直接从程序源代码中通过学习标记、抽象语法树和控制流图等特征来生成神经程序嵌入. 本文重新审视了如何利用编译器中间表示(IR)来改进程序嵌入. 展示了简单而高效的方法, 通过在源代码和默认优化级别(例如-O2)生成的LLVM IR的同时训练嵌入模型来提高嵌入质量. 提出一个基于遗传算法(genetic algorithms, GA)的框架 IRGen, 来识别(次)最优优化标志序列来显著提高嵌入质量.
通过在源代码数据集上执行GA, 使用IRGen找到LLVM优化标志的最优序列. 接着作者扩展了流行的代码嵌入模型CodeCMR, 增加了一个基于三元组损失的新目标, 实现对源代码和LLVM IR的联合学习. 实验使用一个具有代表性的下游应用 —— 代码克隆检测对嵌入的质量进行基准测试. 发现CodeCMR使用源码和经过IRGen优化的LLVM IR进行训练后, 嵌入质量得到显著改进, 效果超过只使用源码进行训练的SOTA CodeCMR. 增强后的CodeCMR的性能也优于在源代码和使用默认优化级别优化的IR上训练的CodeCMR. 作者研究了增强嵌入质量的优化标志的性质, 揭示了IRGen在增强其他嵌入模型的泛化能力, 且在训练数据有限的条件下构建IRGen的使用. 作者的研究和发现表明, 对现代神经代码嵌入模型的直接添加可以提供高效的增强效果.
一句话: 应用遗传算法识别LLVM IR的最优优化标志序列, 提高代码嵌入模型的嵌入质量.
导论
Background
生成代码嵌入的常见过程是直接处理程序的源代码, 提取token序列、语句或抽象语法树(AST)来学习程序表示[9,11,17,37,66]. 尽管一些初步的方法试图提取语义级代码签名, 但这些方法受到了使用语义特征的限制, 这些语义特征粒度太粗[73], 代码覆盖率低(动态分析方面)[89], 或可扩展性有限[90]. 到目前为止, 从代码语法和结构信息中学习仍然是该领域的主要方法, 在这种相对“浅层”的水平上使用特征可能会降低学习质量, 并产生鲁棒性较低的嵌入.
在CV和NLP领域, 通常采用数据增强方法来提高嵌入质量, 这些方法通常通过添加对现有数据稍加修改的副本或从现有数据创建新的合成数据来增加训练数据量.
Approach
本项工作研究了使用编译器中间表示(IR)来增强代码嵌入. 现代编译器包含许多优化标志, 可以无缝地将一段源代码转换为一系列语义相同但语法不同的IR代码. 从全面的角度来看,作者认为本技术可以在两个基本层面上促进程序嵌入. (1) 将一段源码翻译为具有相同功能的不同IR代码增强了训练数据的多样性; (2) 在源码层面, 相同功能的代码可能会有语法上的差异, 但是在剪枝和重排的优化之后这些程序会变得更加相似.
首先说明使用默认的编译器优化级别, 如LLVM的-O2, 可以产生显著提高流行的嵌入模型CodeCMR[100]的嵌入质量的IR代码, 并优于仅在源代码上训练的最先进(SOTA)模型CodeBERT [31]. 尽管这种编译器优化的使用具有良好的潜力, 但大量可用的优化标志和随之而来的大搜索空间为识别性能良好的优化序列以增强嵌入模型带来了挑战.
本文提出IRGen框架, 用遗传算法(GA)搜索(近似)最优的优化序列来生成IR代码,以增强程序嵌入模型. 编译器优化标志通常组合起来生成高速或小体积的机器指令. 相比之下, IRGen针对优化序列, 生成结构上与输入源代码相似的IR代码, 防止IR代码过度简化而减弱表达能力(less expressive). 此外, 为了最大限度地提高学习效率, 限制了对未使用词汇表(OOV)术语的过度使用 [16]. 本文提出一种简单而统一的扩展, 通过三元组损失[94], 使嵌入模型能够从源代码和LLVM IR中学习.
Contributions
(1) 提倡使用编译器优化来增强软件嵌入. 有意优化的IR代码主要通过扩展模型训练数据集和规格化语法特征来提高学习到的程序嵌入的质量.
(2) 本文构建了IRGen, 使用GA算法迭代地形成(近)最优优化序列. 本文提出一种对现代代码嵌入模型的简单而通用的扩展, 以实现对源代码和IR的联合学习.
(3) 实验显示出优于SOTA的结果, 且进一步证明IRGen的泛化性及其在增加非常有限的训练数据方面的优点.
预备知识
神经代码嵌入, 将离散的代码转换为数值和连续的嵌入向量. 如下图
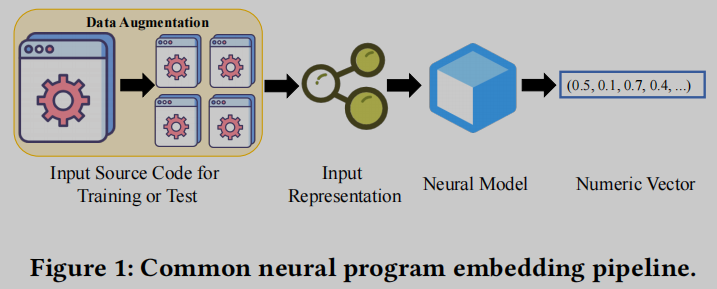
Input Representation
代码可以表示为文本, 并使用现有的NLP模型进行处理. 然而, 这将是昂贵的, 且可能是无效的, 因为编程语言通常包含大量的显式和复杂的结构信息, 这对NLP模型来说很难理解. 因此, 现代代码嵌入模型通常使用信息量大的代码结构表示 (code structural representations) 来学习程序嵌入. 例如, 抽象语法树(AST)用于表示程序嵌入的代码片段. code2vec [11]和code2seq [10]从AST中提取路径集合以形成嵌入. 控制流图(CFG)也被用来形成输入表示, 特别是在分析汇编代码时. 有两个代表性的工作, asm2vec [27]和BinaryAI [99], 在汇编代码上构造CFGs, 并将基本的块级嵌入组合到程序的整体嵌入中.
Neural Model Learning Procedure
神经代码嵌入的学习过程, 主要有两大类: (1) 将程序(结构化)表示(例如AST或CFG)分解为一个或多个token序列, 然后由NLP模型处理; (2) 尝试启动一种“端到端”过程, 使用图神经网络(GNN)等高级神经模型直接学习结构表示.
CodeBERT是一个大规模的SOTA代码嵌入模型, 主要从 token-level 的软件表示中学习., 它的灵感来自BERT. CodeBERT使用掩码语言建模(MLM)和替换token检测来构建学习目标. 利用这些目标, 训练它预测随机屏蔽输入的token, 直到达到饱和精度.
TBCNN [67], Great [41]和BinaryAI [99]利用高级模型, 如GNN, 直接处理程序结构表示. NCC [16]形成了一个包含控制流和数据流信息的上下文流图. 上下文流图中的每个节点都包含一个LLVM IR语句列表, 然后ncc将其转换为向量. 它进一步使用GNN将节点嵌入聚合到整个程序的嵌入中. 与ncc一样, MISIM [98]从程序语法和结构级属性集合开始构建一种新颖的上下文感知语义结构(CASS). 然后使用GNNs将CASS转换为嵌入向量.
Data Augmentation
图像可以在旋转的同时保留其“意义”(例如,通过仿射变换). 同样, 我们可以用同义词替换自然语言句子中的单词, 这不应损害语言语义. 数据增强利用这些观察结果来创建转换规则, 以扩大模型训练数据. 值得一提的是, 特征工程在数据科学和机器学习任务中具有很大的帮助, 但在深度学习领域, 对大量的高维数据做特征工程会变得很不直观. 实际上, 数据增强方法对深度学习模型的性能和鲁棒性的提高得到了检验, 并经常被应用于技术路线中.
然而, 标准的数据增强方法并不直接适用于增强程序嵌入. 增强神经程序嵌入是具有挑战性的, 且尚未得到充分开发. 由于编程语言的合成约束和语义约束, 任意的扩充很容易破坏一个结构良好的程序. 本文探索将数据增强引入源代码. 特别地, 作者提倡使用编译器优化将同一段源代码转换为语义相同但语法不同的IR代码.
动机
LLVM编译器架构支持数百次优化, 每一次优化都会以一种独特的方式改变编译器的IR. 为了让用户更容易访问编译器优化, LLVM框架提供了几个优化包, 用户可以为编译指定, 例如-O2、-O3和-Os. 前两个包结合了优化过程以快速代码执行, 而-Os旨在生成尽可能小的可执行文件. 初步研究表明, 通过将优化的IR代码纳入嵌入学习, 可以大大提高嵌入质量.
Learning Over Source Code
CodeCMR首先将源代码转换为字符序列, 然后计算字符级嵌入, 从而生成代码嵌入. 这些嵌入被送到金字塔卷积神经网络(Pyramid Convolutional Neural Network, DPCNN) [45]的堆栈中, 其中平均池化层构建程序的嵌入. 在作者对POJ-104的评估中, 观察到在MAP分数方面有很好的准确性, 如表1所示.

Limitation of Standard Optimization Levels
尽管结果令人鼓舞, 但作者注意到, 这些默认优化水平是由编译器工程师以不同的关注点选择的, 例如, 生成最小可能的可执行程序或快速执行. 然而, 作者探索了一个不同的角度, 优化被用来生成LLVM IR代码, 以增强程序神经元嵌入. 在这方面, 可以怀疑仅仅利用默认的优化水平是不够的. 例如, -Os和-O3中的某些CPU标志在缩减IR代码时很激进(例如-aggressive-instcombine), 但嵌入模型通常喜欢更"expressive"的输入. 在评估中, 我们发现IRGen没有选择-aggressive-instcombine等侵略性标志.
方法
图2描述了IRGen的工作流程. IRGen初始化第一代优化序列, 然后启动基于GA的搜索, 迭代修改和选择具有高适应度分数 (fitness score) 的序列. GA过程重复𝑁次, 直到终止(𝑁当前为800). 在终止后, 我们在整个GA搜索中选择适应度分数最高的𝐾个序列. 使用这些优化序列, 训练数据中的每段C/ c++代码都可以编译成𝐾个语法上不同的LLVM IR代码片段. 通过将三元组损失作为额外的学习目标, 由此产生的增强代码数据集可用于增强神经嵌入模型.
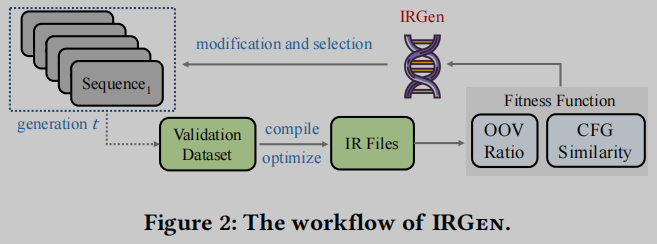
Genetic Representation
作者将每个优化序列表示为一维向量 𝑣 = ( 𝑓 1 , 𝑓 2 , … , 𝑓 𝐿 ) 𝑣=(𝑓_1,𝑓_2,…,𝑓_𝐿) v=(f1,f2,…,fL), 其中𝐿是LLVM为x86平台提供的优化标志的总数. 𝑓 𝑖 𝑓_𝑖 fi是一个二进制数(0/1), 表示在𝑖上是否启用了相应的标志 𝑐 𝑖 𝑐_𝑖 ci. 作为标准设置, 通过随机设置向量𝑣中的元素为1, 初始化向量𝑣的𝑀实例. 这些随机初始化的集合, 在GA术语中称为“种群”, 提供了启动几代进化的起点. 这里, 𝑀被设置为20.
Modification and Selection
在每一代𝑡, 作者采用两个标准的遗传算子, 交叉和突变, 以操作种群中的所有20个载体. 给定两个“父”向量𝑣1和𝑣2, 使用𝑘-point交叉生成两个子代向量: 𝑘在𝑣1和𝑣2上随机选择𝑘交叉点, 并在它们之间交换每一对交叉点标记的内容. 这里, 𝑘设置为2, 每个潜在交叉的机会设置为0.4. 我们还使用翻转位变异(flip bit mutation), 这是另一种常见的方法, 来使种群中的向量多样化. 随机变异向量𝑣中1%的比特. 在这些突变之后, 种群大小保持不变(20个向量), 但一些向量被修改.
接着使用下面定义的适应度函数对每个向量进行评估. 然后将所有变异和未变异的向量传递到标准的轮盘赌选择(RWS)模块, 其中选择向量的机会与其适应度分数成比例. 这样, 具有较高适应度分数的向量更有可能被选择到下一代. RWS过程重复20次, 为生成 𝑡 + 1准备20个向量.
Fitness Function
给定一个向量𝑣, 表示一系列优化标志, 适应度函数ℱ产生一个适应度分数, 作为对𝑣优点的估计. 具体来说, 对于每个𝑣, 我们编译验证数据集𝑃中的每个程序𝑝, 使用𝑣中指定的优化来生成IR程序𝑙∈𝐿. 对于一个C程序𝑝及其编译后的IR 𝑙, 我们计算以下适应度分数:
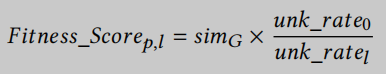
其中
𝑠
𝑖
𝑚
𝐺
𝑠𝑖𝑚_𝐺
simG表示 𝑙 和 𝑝 之间的图级相似度,
𝑢
𝑛
𝑘
_
𝑟
𝑎
𝑡
𝑒
0
𝑢𝑛𝑘\_𝑟𝑎𝑡𝑒_0
unk_rate0的值表示在用-O0编译𝑝时在IR代码
𝑙
0
𝑙_0
l0中发现的#OOV案例的数量,
𝑢
𝑛
𝑘
_
𝑟
𝑎
𝑡
𝑒
𝑙
𝑢𝑛𝑘\_𝑟𝑎𝑡𝑒_𝑙
unk_ratel代表 𝑙 中发现的# OOV案例数. 然后将每个程序p的适应度分数取平均得到向量
v
v
v的适应度分数.
图相似度度量 在CFG级别量化原始源代码与编译后IR代码之间的相似度. 这提供了对创建的IR代码质量的高层次评估. 更重要的是, 该条件防止了编译器优化对代码的过度缩减, 确保了IR代码合理地保留了原始源代码的结构级特性.
作者初步评估了三种图相似度计算方法:1)核方法, 2)图嵌入[35,97], 和 3)树编辑距离. 图嵌入方法通常需要微调大量超参数, 具有挑战性. 树编辑距离算法处理为测试用例创建的非常复杂的CFGs的能力有限. 因此, IRGen目前的实现使用了一种经典和广泛使用的内核方法, 最短路径内核[18], 来量化源代码𝑝与其优化的IR代码𝑙之间的结构距离.
OOV比率 在嵌入学习中, OOV (out-of-vocabulary)表示很少观察到的token, 不属于典型的token词汇表. 作者给优化标志序列选择添加高OOV惩罚机制. 虽然可以通过利用BPE[46]等子token化技术来避免token级OOV问题, 但是在IR代码上应用时会带来30倍的开销增加.
Learning Multiple IRs using Triplet Loss
IRGen不是保留具有最高适应度分数的单个序列, 而是保留每一代的top-𝐾序列, 根据它们的适应度分数进行排名. 作者发现用top-𝐾优化序列生成的多个LLVM IR代码执行增强是有益的. 给定GA过程, 这top-𝐾序列将明显共享一些重叠的优化标志. 使用这些top-𝐾序列将源程序编译为𝐾个LLVM IR程序时,这些IR程序仍然是不同的, 尽管它们共享与参考源代码相关的规范代码结构. 因此, 我们预计增强后的数据集将是多样化的.
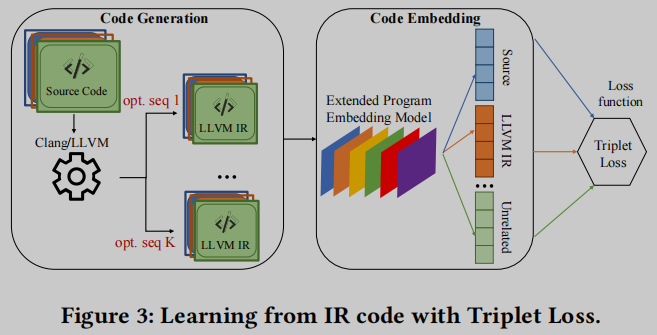
图3描述了对程序嵌入模型进行有效和通用的扩展, 以包含多个IR代码. 作者首先扩展了一个代码嵌入模型𝑀来处理LLVM IR. 然后采用一个流行的学习目标, 即三元组损失[94], 作为𝑀的损失函数. 三元组由一个正样本、一个负样本和一个锚点组成, 被用作三元组损失的输入. 锚点也是正样本, 它最初与负样本的距离比与正样本的距离更近. 在训练过程中, 锚点-正对被拉近, 而锚点-负对被推开. 在本方法的设置中, 正样本代表一个程序𝑝, 锚代表从𝑝产生的IR代码, 负样本代表其他不相关的源代码.
实验
IRGen目前是用CodeCMR [100]实现的, 这是一个已在真实世界的C/C++程序上经过彻底测试的SOTA代码嵌入模型.我们发现它的代码使用简单, 质量高. IRGen与使用的特定代码嵌入模型正交. 并用另一个嵌入工具NCC评估了IRGen的泛化性, 该工具直接从LLVM IR计算嵌入.
作者扩展了官方版本的CodeCMR, 以使用C源代码和LLVM IR代码共同计算嵌入. 还实现了一个基于treesitter [86]的C/C++解析器和一个LLVM IR解析器(由ncc扩展而来), 因为我们需要使用内核方法来比较C/C++和IR代码的距离. 图4描绘了扩展的CodeCMR的主要网络结构. CodeCMR是DPCNN的一种变体, 已被证明可以有效地表示文本中的长程关联. 如图4所示, 关键的构建模块——单词级卷积神经网络(CNN)可以被复制, 直到模型足够深以捕获全局输入文本表示.
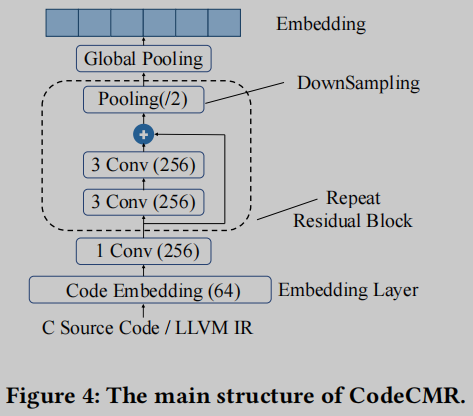
回想IRGen通过返回top-𝐾序列生成𝐾个IR代码集合, 现在比较𝐾对学习质量的影响. 作者使用在POJ-104上训练的CodeCMR进行实验, 并在表2中测量不同𝐾的MAP精度. 总的来说, 增加𝐾虽然可以不断扩展训练数据, 但学习精度在𝐾=6时达到峰值. 本文解释这些结果以确认另一个重要的(和直观的)观察: 与自然语言或图像模型上的数据增强一致, 在训练数据集中涉及多个不同的IR代码集合, 可增强代码嵌入的学习质量.
Datasets
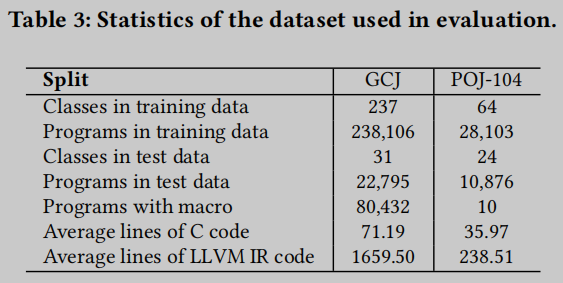
表3给出了POJ-104 [66] 和 GCJ [72]两个数据集的汇总统计数据. POJ-104数据集包含44,912个C/C++程序, 它们为104个不同的任务(例如, 归并排序)实现了入门级编程任务. 谷歌Code Jam (GCJ)是谷歌自2008年以来举办的一项国际编程比赛. GCJ数据集包含GCJ编程挑战的解决方案的源代码. GCJ数据集是常用的, 包含260,901个C/C++程序. 与POJ相比, GCJ文件更长, 数量也更多.
Baseline Models 为了与IRGen增强的CodeCMR进行比较, 配置了7个嵌入模型, 包括CodeBERT [31]、code2vec [11]、code2seq [9]、ncc [16]、Aroma [58]、CodeCMR和MISIM [98].
Cost 作者对GA的学习和测试是在具有两个Intel Core™ i7-8700 CPU和16GB RAM的桌面计算机上进行的. 机器运行的是Ubuntu 18.04. IRGen对POJ-104和GCJ的遗传算法迭代800次平均耗时分别为143.52和963.41个CPU小时. 尽管CPU时间很高, 但通过并行可以大大减少挂钟时间. 实验探索了在64核CPU服务器上重新运行GA过程, POJ-104大约需要25个小时, GCJ大约需要81小时.
嵌入模型训练是使用GPU服务器. 该服务器有两个Intel® Xeon® Platinum 8255C cpu, 工作在2.50GHz, 384 GB内存和16个NVIDIA Tesla V100 GPU, 每个内存为32GB. 学习率为0.001, 残差块重复次数为11; 扩展的CodeCMR的其他设置与标准的CodeCMR设置相同. POJ-104和GCJ共耗时约15.9小时和91.3小时.
Accuracy of IRGen
RQ1:经过IRGen的改进后, CodeCMR与其他相关的克隆代码检测工作相比表现如何?
对于神经嵌入模型, 作者启动每个实验三次, 并报告平均分数, 以及括号中的最小和最大分数. 在表4第3-11行给出了Baseline Models的评估结果, 还报告了使用由标准优化水平(-O0, -O1, -O2, -O3, -Os)优化的IR代码增强的CodeCMR的结果, 其中CodeCMR-demix表示通过使用源代码和由所有五个默认优化级别编译的五组IR来训练CodeCMR. 对于POJ-104和GCJ数据集, 除了使用MAP外, 我们还使用AP [13]作为指标. 在相关研究中, 这两个指标通常用于评估嵌入模型的性能. AP代表平均精度(Average Precision), 是一种结合查全率和查准率的排序检索方法.
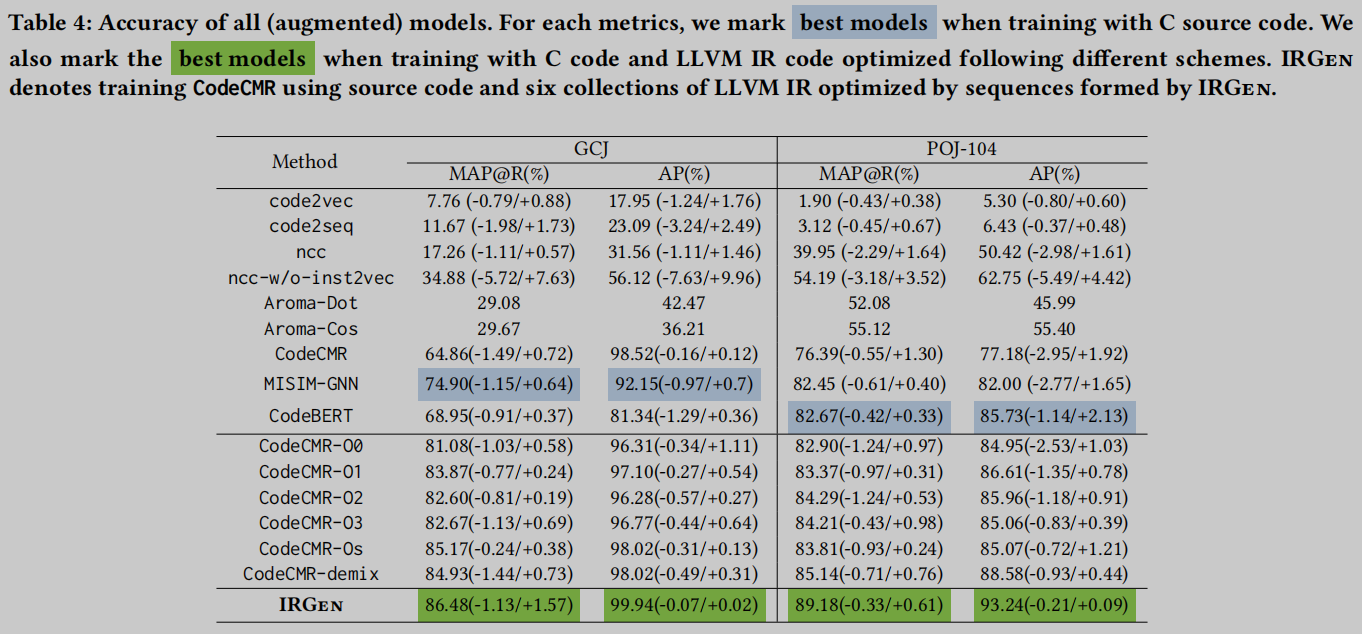
实验结果表明, 现代嵌入模型, 包括CodeBERT、CodeCMR和MISIM-GNN, 可以在很大程度上超过传统的代码匹配工具, 如Aroma-Dot和Aroma-Cos. 在通过C源代码学习时, 我们发现CodeBERT是POJ-104数据集性能最好的模型, 而MISIM-GNN为GCJ数据集提供了最佳性能. 相比之下, CodeCMR在所有评估指标上的表现都不如SOTA模型. 其中, Code2vec和code2seq的准确率较低.
CodeCMR-demix的设置比使用一组优化的IR代码增强CodeCMR表现出(略微)更好的性能, 尤其是在POJ-104设置上. 这也揭示了使用多种不同的IR代码集进行训练的作用.
当使用IRGen(表4的最后一行)的结果进行增强时, CodeCMR的性能不断明显优于所有其他设置. 评估结果非常令人鼓舞, 表明IRGen可以生成高质量的LLVM IR代码, 增强CodeCMR, 在所有指标上明显优于SOTA模型(CodeBERT和MISIM-GNN).
Fitness Function
RQ2: IRGen采用的遗传算法(GA)有多精确?
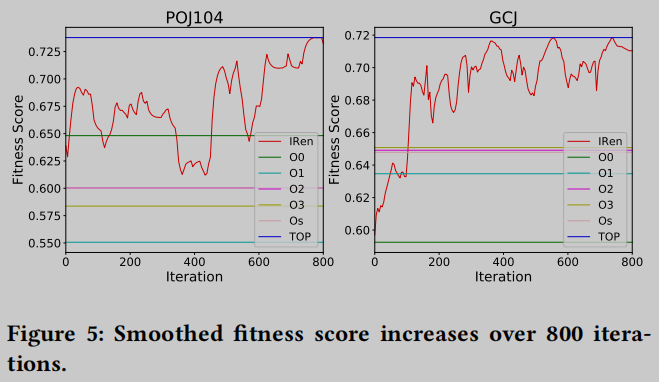
图5报告了每个GA执行中所有800次IRGen迭代的适应度分数的增长. 测试用例尽管功能多样, 但在优化搜索过程中表现出令人鼓舞和一致的趋势. 适应度分数不断增加, 并在大约410到600次迭代后达到饱和性能. 在适应度函数的指导下, IRGen可以为两个数据集找到表现良好的序列.
Potency of Optimization Flags
RQ3:最重要的优化标志及其特征是什么? 在不同的数据集上, 标志的最佳序列是否会改变?
对于POJ-104数据集, 具有最高适应度分数的top-1序列𝑆包含49个标志. 为了衡量它们的贡献, 我们首先使用C源代码和使用序列𝑆优化的LLVM IR训练CodeCMR, 并将基线精度记录为𝑎𝑐𝑐. 然后, 我们分别丢弃𝑆中的一个优化标志𝑓, 并测量使用剩余的48个标志序列的增强效果. 准确率的下降揭示了flag 𝑓的贡献.
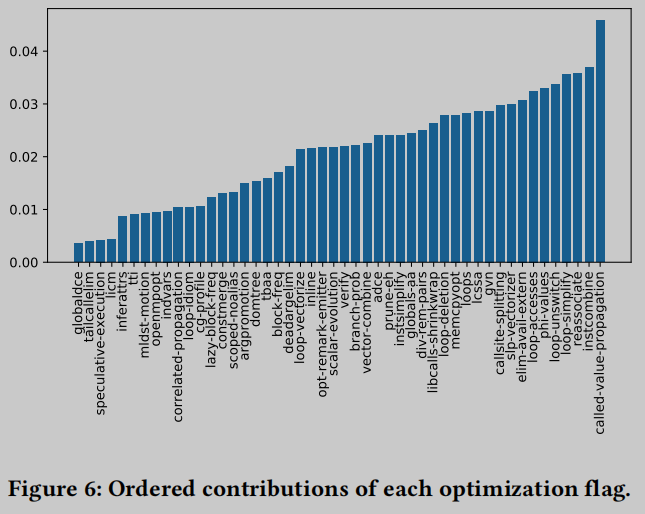
图6在𝑆中对每个flag的贡献进行排序. 总的来说, 我们认为在此评估中没有发现占据主导的优化标志. 所有这49个标志对模型扩展都有合理的贡献, 前10个标志总共贡献了34.38%. 因此得到一个关键结论: 重要的不是确定一个或几个显著有助于增强代码嵌入的主导标志, 而是优化标志的形成序列.
Generalization
RQ4:相对于其他模型和不同的学习算法, IRGen的泛化性如何?
本文通过增强另一个流行的神经嵌入模型ncc来证明IRGen的泛化性. 如前所述, ncc在LLVM IR代码上执行嵌入. 因此不需要改变ncc的实现. ncc增强评估结果见表5. 为了与IRGen形成的优化序列进行比较, 还准备了一个baseline, 表示一个包含随机选择的49个优化标志的序列. 这两个基线结果报告在第三行和第六行.
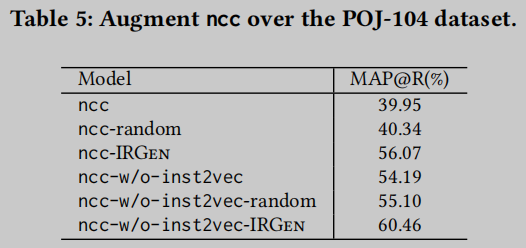
正如预期的那样, IRGen显著提高了ncc和ncc-w/o-inst2vec的质量. 特别是后一个模型的MAP分数提高到60.46%, 甚至高于Aroma的两个变体的得分. 相比之下, 我们发现两种随机方案的增强可以忽略不计. 总的来说, 这个评估表明IRGen为神经代码嵌入模型提供了具有泛化性的增强, 而不考虑具体的模型设计.
Augmentation with Small Training Data
RQ5:当只有有限的源代码样本可用时, IRGen还能实现增强吗?
考虑一种常见情况, 即程序嵌入受到有限的训练数据的限制. 我们认为这是一种常见的情况, 例如在漏洞分析中, 只有有限的漏洞代码样本可用. 在这些情况下, 预测使用优化的IR代码扩展训练数据集和增强嵌入模型的可行性和有用性.
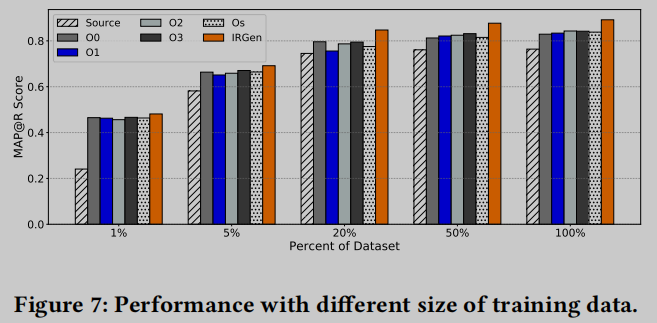
选择1%的数据集子集来进行训练, 图7展示了小训练集的模型精度结果. 在不扩展数据集时, 精度为24.08%, 而使用IRGen选择的不同标准优化水平和优化序列后, MAP准确率提高到40%以上, 几乎是原来MAP得分的两倍. 除了极端的1%样本测试外, 我们还随机选择了5%、20%和50%的POJ-104训练数据并重新训练CodeCMR. 如图7所示, 我们使用相同的标准优化标志和IRGen选择的标志进一步扩充每个子集的模型. 我们一直取得了有希望的增强结果. 特别是, IRGen发现的优化标志在所有这些小型训练数据集上的性能优于所有其他增强方案. 这些直观和非常有希望的评估结果表明, IR代码可以用来显著和可靠地增强代码嵌入, 特别是在只有非常有限的数据时. 与标准优化水平相比, IRGen选择的优化序列可以获得更高的增强效果.
总结
References
[9] Uri Alon, Shaked Brody, Omer Levy, and Eran Yahav. 2018. code2seq: Generating sequences from structured representations of code. arXiv preprint arXiv:1808.01400 (2018).
[10] Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. 2018. A general pathbased representation for predicting program properties. ACM SIGPLAN Notices 53, 4 (2018), 404–419.
[11] Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. 2019. Code2Vec: Learning Distributed Representations of Code. Proc. ACM Program. Lang. 3,POPL (Jan. 2019).
[13] Ricardo A. Baeza-Yates and Berthier A. Ribeiro-Neto. 1999. Modern Information Retrieval. ACM Press / Addison-Wesley
[16] Tal Ben-Nun, Alice Shoshana Jakobovits, and Torsten Hoefler. 2018. Neural Code Comprehension: A Learnable Representation of Code Semantics. Advances in Neural Information Processing Systems 31 (2018), 3585–3597.
[17] Sahil Bhatia and Rishabh Singh. 2016. Automated correction for syntax errors in programming assignments using recurrent neural networks. arXiv preprint arXiv:1603.06129 (2016).
[18] Sahil Bhatia and Rishabh Singh. 2016. Automated correction for syntax errors in programming assignments using recurrent neural networks. arXiv preprint arXiv:1603.06129 (2016).
[27] S. H. Ding, B. M. Fung, and P. Charland. 2019. Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization. In IEEE S&P.
[31] Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. CodeBERT: A pre-trained model for programming and natural languages. arXiv preprint arXiv:2002.08155 (2020).
[35] Palash Goyal and Emilio Ferrara. 2018. Graph embedding techniques, applications, and performance: A survey. Knowledge-Based Systems 151 (2018), 78–94.
[37] Rahul Gupta, Soham Pal, Aditya Kanade, and Shirish Shevade. 2017. Deepfix: Fixing common c language errors by deep learning. In Thirty-First AAAI Conference on Artificial Intelligence.
[41] Vincent J Hellendoorn, Charles Sutton, Rishabh Singh, Petros Maniatis, and David Bieber. 2019. Global relational models of source code. In International conference on learning representations.
[45] Rie Johnson and Tong Zhang. 2017. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 562–570.
[46] Rafael-Michael Karampatsis, Hlib Babii, Romain Robbes, Charles Sutton, and Andrea Janes. 2020. Big code!= big vocabulary: Open-vocabulary models for source code. In ICSE. IEEE, 1073–1085
[58] Sifei Luan, Di Yang, Celeste Barnaby, Koushik Sen, and Satish Chandra. 2019. Aroma: Code recommendation via structural code search. Proceedings of the ACM on Programming Languages 3, OOPSLA (2019), 1–28.
[66] Lili Mou, Ge Li, Lu Zhang, Tao Wang, and Zhi Jin. 2016. Convolutional neural networks over tree structures for programming language processing. In Thirtieth AAAI Conference on Artificial Intelligence
[67] Lili Mou, Ge Li, Lu Zhang, Tao Wang, and Zhi Jin. 2016. Convolutional neural networks over tree structures for programming language processing. (2016).
[73] Chris Piech, Jonathan Huang, Andy Nguyen, Mike Phulsuksombati, Mehran Sahami, and Leonidas Guibas. 2015. Learning program embeddings to propagate feedback on student code. In ICML.
[89] Ke Wang, Rishabh Singh, and Zhendong Su. 2018. Dynamic Neural Program Embeddings for Program Repair. In 6th International Conference on Learning Representations.
[90] Ke Wang and Zhendong Su. 2019. Learning blended, precise semantic program embeddings. In POPL.
[94] Kilian Q Weinberger and Lawrence K Saul. 2009. Distance metric learning for large margin nearest neighbor classification. Journal of machine learning research 10, 2 (2009).
[97] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. 2020. A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems 32, 1 (2020), 4–24.
[98] Fangke Ye, Shengtian Zhou, Anand Venkat, Ryan Marucs, Nesime Tatbul, Jesmin Jahan Tithi, Paul Petersen, Timothy Mattson, Tim Kraska, Pradeep Dubey, et al. 2020. MISIM: An end-to-end neural code similarity system. arXiv preprint arXiv:2006.05265 (2020).
[99] Zeping Yu, Rui Cao, Qiyi Tang, Sen Nie, Junzhou Huang, and Shi Wu. 2020. Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection. (2020).
[100] Zeping Yu, Wenxin Zheng, Jiaqi Wang, Qiyi Tang, Sen Nie, and Shi Wu. 2020. CodeCMR: Cross-Modal Retrieval For Function-Level Binary Source Code Matching. Advances in Neural Information Processing Systems 33 (2020).
Insights
OOV问题
(1) 通过在迭代GA时引入高OOV比率的惩罚机制, 使结果更倾向于选择低OOV的代码优化序列.
(2) BPE子token化技术可以解决OOV问题, 不过在IR上开销过大实际不适用.
联想
(3) 受CV和NLP领域中数据增强的启发, 在程序分析领域中的数据增强可以借助编译器的不同优化序列获得更大的数据集, 而采用GA对编译优化序列进行选择得到更有表达力和对嵌入模型训练更有效的数据集.
(4) 遗传算法可以用来选择序列, 能不能用来选择代码分支, 比如构造fuzzer时使用遗传算法触发不同的执行路径…
作者
(6) 通过使用不同的优化序列生成的IR代码来扩展有限的数据集.
(7) 有更先进的优化算法 ---- 进化算法可用. 特别是, 两个适应度目标可以单独优化, 即使用多目标优化.
(8) 从整体上看, 寻找最优序列是一个马尔可夫决策过程(Markov Decision Process, MDP). 复杂的mdp(例如, 自动驾驶)可能可以用强化学习(RL)技术来解决.
















 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









