







padas的基本使用
| Pandas基于两种数据类型:series 与 dataframe |
- series 一维的数据类型,其中每一个元素都有一个标签。(是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象等),轴标签统称为索引)
- dataframe 二维的表结构,相当于一个series的字典项
padas的引入:import padas as pd
读取csv文件:info = pd.read_csv(“food_info.csv”)
查看头部数据:print(info.head(3)) #打印出前三条的信息
查看尾部数据:.tail()
转置:.T
添加与修改
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d']
df['e'] = 10
df.loc[4] = 20
print(df)
# 新增列/行并赋值
df['e'] = 20
df[['a','c']] = 100
print(df)
# 索引后直接修改值
删除:del或者drop()
1.删除列
- del df[“a”]
- df.drop[“a”]
2.删除行
df.drop(0)
df.drop([1,2,3])
数据对齐
print(df1 + df2) DataFrame对象之间的数据自动按照列和索引(行标签)对齐
| 排序(重点) |
1.通过值排序:.sort_values
# 排序1 - 按值排序 .sort_values
# 同样适用于Series
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df1)
print(df1.sort_values(['a'], ascending = True)) # 以"a"列为基准,升序
print(df1.sort_values(['a'], ascending = False)) # 以"a"列为基准,降序
print('------')
# ascending参数:设置升序降序,默认升序
# 单列排序
df2 = pd.DataFrame({'a':[1,1,1,1,2,2,2,2],
'b':list(range(8)),
'c':list(range(8,0,-1))})
print(df2)
print(df2.sort_values(['a','c']))#先以“a”所在列排序,在以“b”所在列排序
# 多列排序,按列顺序排序
# 注意inplace参数
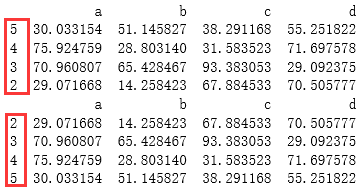
2 按照索引的大小排序:sort_index()
# 排序2 - 索引排序 .sort_index
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = [5,4,3,2],
columns = ['a','b','c','d'])
print(df1)#乱序的索引
print(df1.sort_index())#将索引按照从小到大的顺序排列
结果:
series的创建
1.通过一维数组创建
s = pd.Series(np.random.rand(5))
print(s)
结果为: 对应的索引和一维数组组成,与字典的结构很类似,索引的原理也和字典一致
0 0.934164
1 0.061777
2 0.220865
3 0.976883
4 0.072075
2.通过字典创建
# Series 创建方法一:由字典创建,字典的key就是index,values就是values
dic = {'a':1 ,'b':2 , 'c':3, '4':4, '5':5}
s = pd.Series(dic)
print(s)
结果为:左边为索引值index、右边为value
a 1
b 2
c 3
4 4
5 5
dtype: int64
Dataframe的创建
Dataframe相当于一个表格形的数据结构
1.Dataframe带有index(行标签)和columns(列标签)
data = {'name':['Jack','Tom','Mary'],
'age':[18,19,20],
'gender':['m','m','w']}
frame = pd.DataFrame(data)
print(frame)
结果为:
age gender name
0 18 m Jack
1 19 m Tom
2 20 w Mary
由此可知到: 数据类型dataframe的查看
- .index查看行标签
- .columns查看列标签
- .values查看值,数据类型为ndarray
print(frame.index,'\n该数据类型为:',type(frame.index))
print(frame.columns,'\n该数据类型为:',type(frame.columns))
print(frame.values,'\n该数据类型为:',type(frame.values))
RangeIndex(start=0, stop=3, step=1)
该数据类型为: <class 'pandas.core.indexes.range.RangeIndex'>
Index(['name', 'age', 'gender'], dtype='object')
该数据类型为: <class 'pandas.core.indexes.base.Index'>
[['Jack' 18 'm']
['Tom' 19 'm']
['Mary' 20 'w']]
该数据类型为: <class 'numpy.ndarray'>
2.创建方法1:通过字典创建如上所示
3.创建方法2:通过二维数组创建
# Dataframe 创建方法三:通过二维数组直接创建
ar = np.random.rand(9).reshape(3,3)
df2 = pd.DataFrame(ar, index = ['a', 'b', 'c'], columns = ['one','two','three']) # 可以尝试一下index或columns长度不等于已有数组的情况
print(df2)
# 通过二维数组直接创建Dataframe,得到一样形状的结果数据,如果不指定index和columns,两者均返回默认数字格式
如果不指定:则默认行列为数字0,1,2,。。。
one two three
a 0.339401 0.773847 0.253083
b 0.281513 0.028760 0.751607
c 0.347467 0.252451 0.689796
3.创建方法3:通过Series创建
data2 = {'one':pd.Series(np.random.rand(2), index = ['a','b']),
'two':pd.Series(np.random.rand(3),index = ['a','b','c'])} # 设置了index的Series
print(data2)
df2 = pd.DataFrame(data2)
print(df1)
print(df2)
# 由Seris组成的字典 创建Dataframe,columns为字典key,index为Series的标签(如果Series没有指定标签,则是默认数字标签)
# Series可以长度不一样,生成的Dataframe会出现NaN值
如果不指定index则默认为数字0,1,2.。。,并且,没有值的位置会显示nan
one two
a 0.920073 0.826446
b 0.215178 0.983392
c NaN 0.187749
索引与切片
索引
列索引:直接[加上索引名]
行索引:.loc[索引名1,索引名2…]或者.iloc[索引的下标,或者切片下标]
行索引:.loc亦可使用切片的方式。如:
data5 = df1.loc[‘one’:‘three’]
data6 = df2.loc[1:3](表现选取行1,2,3)与iloc有一定的区别,
# 选择行与列
df = pd.DataFrame(np.random.rand(12).reshape(3,4)*100,
index = ['one','two','three'],
columns = ['a','b','c','d'])
print(df)
data1 = df['a']
data2 = df[['a','c']]
print(data1,type(data1))
print(data2,type(data2))
print('-----')
# 按照列名选择列,只选择一列输出Series,选择多列输出Dataframe
data3 = df.loc['one']
data4 = df.iloc[0:2]
print(data2,type(data3))
print(data3,type(data4))
# 按照index选择行,只选择一行输出Series,选择多行输出Dataframe
切片
1.指定位置选取
# df.iloc[] - 按照整数位置(从轴的0到length-1)选择行
# 类似list的索引,其顺序就是dataframe的整数位置,从0开始计
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('------')
print(df.iloc[0])#选择第一行
print(df.iloc[-1])#选取最后一行
#print(df.iloc[4])
print('单位置索引\n-----')
# 单位置索引
# 和loc索引不同,不能索引超出数据行数的整数位置
print(df.iloc[[0,2]])#选择第一、第三行
print(df.iloc[[3,2,1]])#选取第三、第二、第一行
print('多位置索引\n-----')
2.通过:来选取
print(df.iloc[1:3])#选择1,2
print(df.iloc[::2])#从0开始间隔为2选取
3.bool类型的选取
# 布尔型索引
# 多用于索引行
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('------')
b1 = df < 20
print(b1,type(b1))
print(df[b1]) # 也可以书写为 df[df < 20]
print('------')
# 不做索引则会对数据每个值进行判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
b2 = df['a'] > 50
print(b2,type(b2))
print(df[b2]) # 也可以书写为 df[df['a'] > 50]
print('------')
# 单列做判断
# 索引结果保留 单列判断为True的行数据,包括其他列
b3 = df[['a','b']] > 50
print(b3,type(b3))
print(df[b3]) # 也可以书写为 df[df[['a','b']] > 50]
print('------')
# 多列做判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
# 注意这里报错的话,更新一下pandas → conda update pandas
b4 = df.loc[['one','three']] < 50
print(b4,type(b4))
print(df[b4]) # 也可以书写为 df[df.loc[['one','three']] < 50]
print('------')
# 多行做判断
# 索引结果保留 所有数据:True返回原数据,False返回值为NaN
数值处理
object类型的列不能参与数值运算:可通过:df[‘key3’].dtype查看
行列汇总
m2 = df.mean(axis=1)
print(m2)
print('--列计算---')
# axis参数:默认为0,以列来计算,axis=1,以行来计算,这里就按照行来汇总了
m3 = df.mean(skipna=False)
print(m3)
print('--是否忽略nan---')
# skipna参数:是否忽略NaN,默认True,如False,有NaN的列统计结果仍未NaN
主要的数学计算方法
统计非Na值的数量:.count()
统计最小值:.min()
quantile统计分位数:.quantile(q=0.75)
求和:.sum()
平均值:.mean()
中位数:.median()
标准差:.std()
skew样本的偏度:.skew()
kurt样本的峰度:.kurt()
cumsum样本的累计和:.cumsun()
cumprod样本的累计积:cumprod()
字符串的常用方法
# 字符串常用方法(1) - lower,upper,len,startswith,endswith
s = pd.Series(['A','b','bbhello','123',np.nan])
print(s.str.lower(),'→ lower小写\n')
print(s.str.upper(),'→ upper大写\n')
print(s.str.len(),'→ len字符长度\n')
print(s.str.startswith('b'),'→ 判断起始是否为a\n')
print(s.str.endswith('3'),'→ 判断结束是否为3\n')
print(s.str.strip()) # 去除字符串中的空格
print(s.str.lstrip()) # 去除字符串中的左空格
print(s.str.rstrip()) # 去除字符串中的右空格
replace替换的使用
df.columns = df.columns.str.replace(’ ‘,’-’)#将字符串中的" “用”-"替换
字符串的分割
split
s = pd.Series(['a,b,c','1,2,3',['a,,,c'],np.nan])
print(s.str.split(','))
print('-----')
# 类似字符串的split
print(s.str.split(',')[0])
print('-----')
# 直接索引得到一个list
print(s.str.split(',').str[0])
print(s.str.split(',').str.get(1))
print('-----')
# 可以使用get或[]符号访问拆分列表中的元素

replit
print(s.str.split(',', expand=True))
print(s.str.split(',', expand=True, n = 1))
print(s.str.rsplit(',', expand=True, n = 1))
print('-----')
# 可以使用expand可以轻松扩展此操作以返回DataFrame
# n参数限制分割数
# rsplit类似于split,反向工作,即从字符串的末尾到字符串的开头
df = pd.DataFrame({'key1':['a,b,c','1,2,3',[':,., ']],
'key2':['a-b-c','1-2-3',[':-.- ']]})
print(df['key2'].str.split('-'))
# Dataframe使用split

字符串的索引
s = pd.Series(['A','b','C','bbhello','123',np.nan,'hj'])
df = pd.DataFrame({'key1':list('abcdef'),
'key2':['hee','fv','w','hija','123',np.nan]})
print(s.str[0]) # 取第一个字符串
print(s.str[:2]) # 取前两个字符串
print(df['key2'].str[0])
# str之后和字符串本身索引方式相同
padas处理操作
1.合并:merge
print(pd.merge(df1, df2, on='key'))
print('------')
# left:第一个df
# right:第二个df
# on:参考键
print(pd.merge(df3, df4, on=['key1','key2']))
# 多个链接键
---------------------------------------重点:合并的方法how-------------------------------------------------------
print(pd.merge(df3, df4,on=['key1','key2'], how = 'inner'))
print('------')
# inner:默认,取交集
print(pd.merge(df3, df4, on=['key1','key2'], how = 'outer'))
print('------')
# outer:取并集,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'left'))
print('------')
# left:按照df3为参考合并,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'right'))
# right:按照df4为参考合并,数据缺失范围NaN
--------------------------------------指定左右key--------------------------------------------------------
df1 = pd.DataFrame({'lkey':list('bbacaab'),
'data1':range(7)})
df2 = pd.DataFrame({'rkey':list('abd'),
'date2':range(3)})
print(pd.merge(df1, df2, left_on='lkey', right_on='rkey'))
print('------')
# df1以‘lkey’为键,df2以‘rkey’为键
print(pd.merge(df1, df2, left_on='key', right_index=True))
# df1以‘key’为键,df2以index为键
2 连接:concat
s1 = pd.Series([1,2,3])
s2 = pd.Series([2,3,4])
print(pd.concat([s1,s2]))
print('-----')
# 默认axis=0,行+行
print(pd.concat([s3,s4], axis=1))
print('-----')
# axis=1,列+列,成为一个Dataframe
3 去重
s = pd.Series([1,1,1,1,2,2,2,3,4,5,5,5,5])
print(s.duplicated())
print(s[s.duplicated() == False])
print('-----')
# 判断是否重复
# 通过布尔判断,得到不重复的值

数据分组
groupby()
数据读取
read_table, read_csv, read_excel















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









