







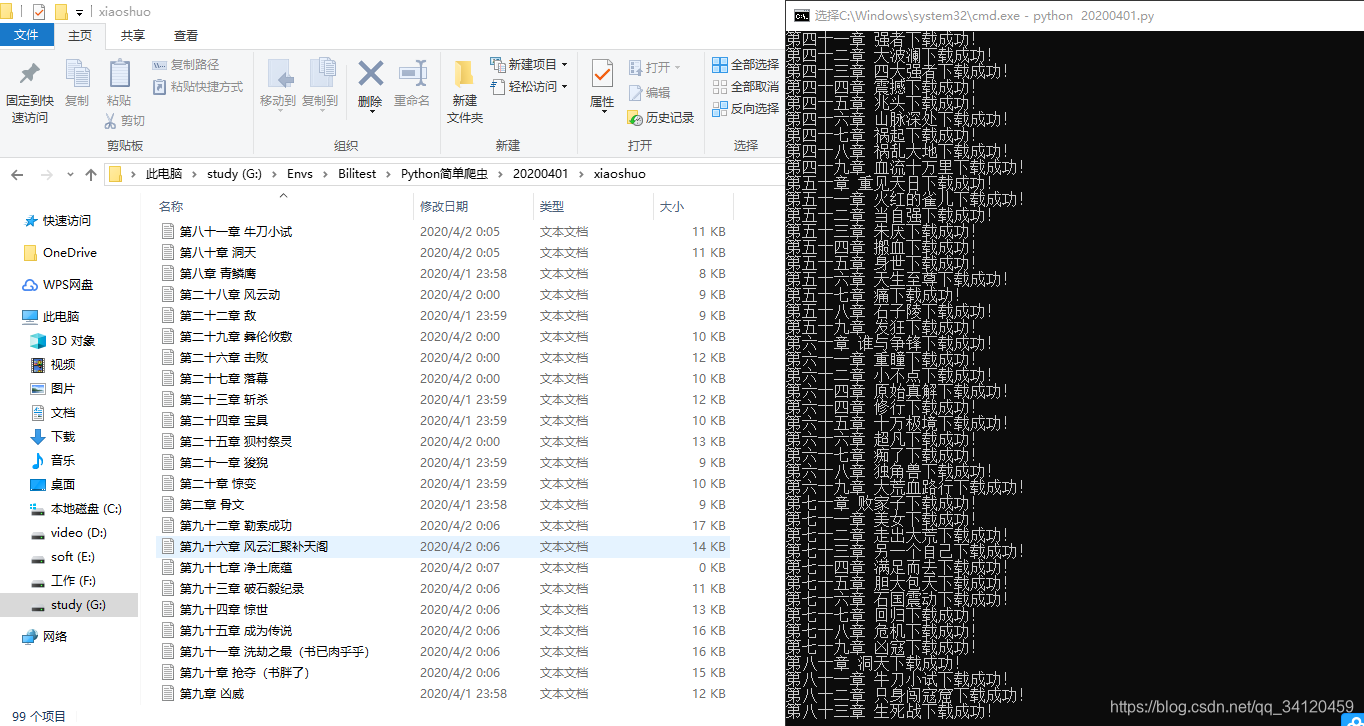
 本文介绍如何使用Python编写一个爬虫,从笔趣阁网站抓取小说内容,并以章节名称保存为TXT文件。教程详细讲解了获取章节URL、拼接章节详情页地址、提取章节内容及设置请求头避免反爬策略的过程。
本文介绍如何使用Python编写一个爬虫,从笔趣阁网站抓取小说内容,并以章节名称保存为TXT文件。教程详细讲解了获取章节URL、拼接章节详情页地址、提取章节内容及设置请求头避免反爬策略的过程。
hello大家好,我是你们的可爱丸,不知道你们有没有遇到过这种情况:
自己喜欢的小说竟然只能看不能下载???

作为一个python学习者,这种情况当然不能忍,那么今天我就教大家用python写一个小说爬虫,轻轻松松的把全网小说都下载到你的电脑里。
视频教程地址:https://www.bilibili.com/video/bv1gQ4y1M7j7
本次案例我选取的是小说网站是:笔趣阁,首页地址为:https://www.52bqg.com/
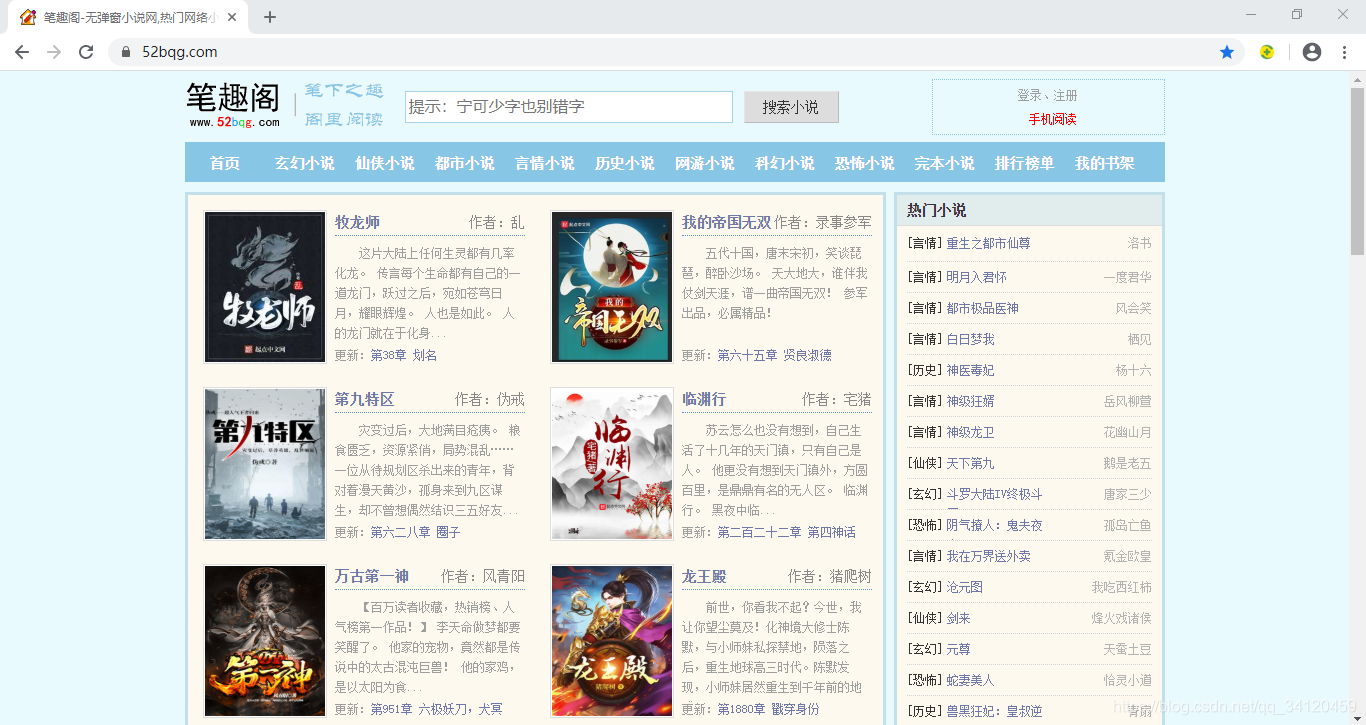
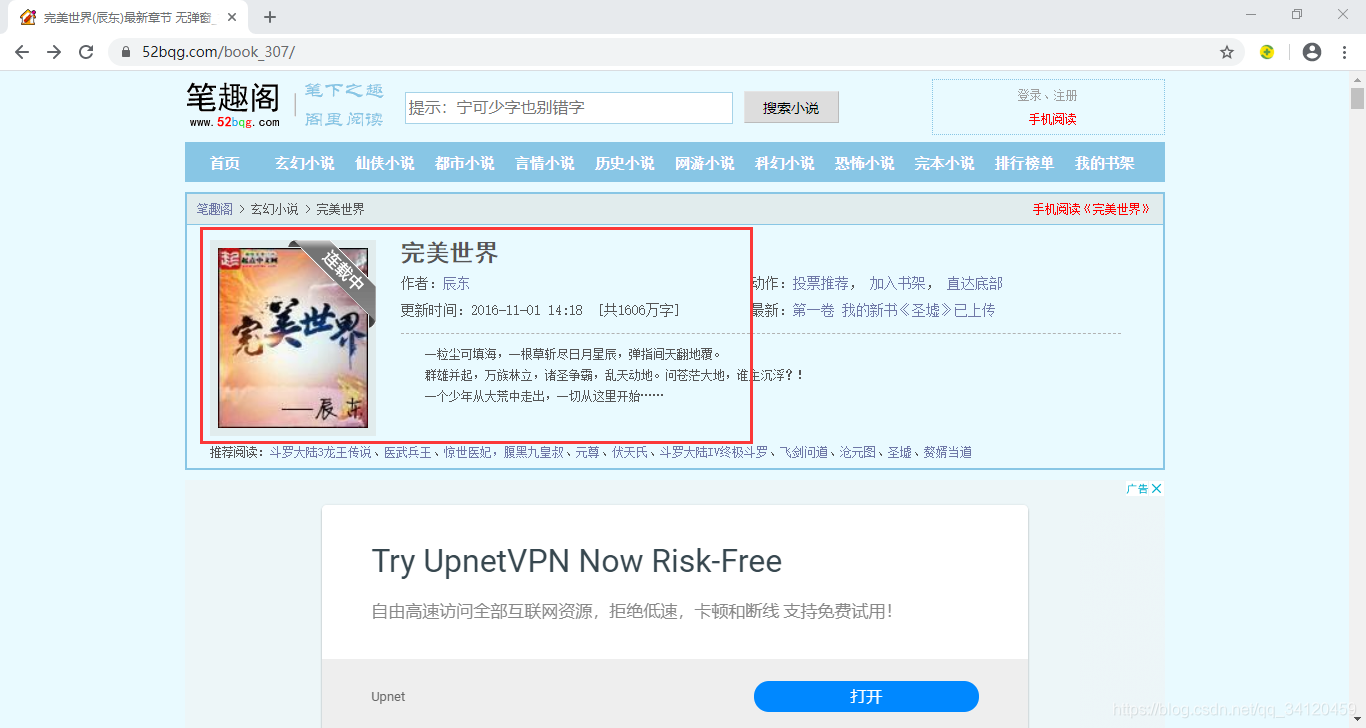
因为该小说网站上每一本小说的内容都很多,所以今天我就教大家设计针对单本小说的爬虫。在本案例中,我选取的是以下这本还在连载的小说,网页地址为:https://www.52bqg.com/book_307/
在正式开始讲解之前我先给大家讲解一下我的设计思路:
1、确定想要爬取的小说及入口url
2、在入口url通过解析获取小说所有章节名称及各章节href
3、通过字符串拼接得到所有章节详情页的地址
4、爬取每章具体内容的文本
5、将每章小说以章节名称命名并保存为txt文件
注意: 现在各大网站都有反爬机制,所以我们要对我们的爬虫进行伪装,让它模仿浏览器访问,这样网站就检测不到访问他的是爬虫程序啦。所以我们要给爬虫设置请求头,将网页的User-Agent复制到代码里
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
刚才我们已经确定了想要爬的小说以及入口url, 那怎么获取小说的章节名称和href呢? 方法是:点击鼠标右键,选择检查,然后选择左上角的小箭头,再把鼠标移动到我们想要获取的内容的位置,就能找到他们的代码啦!
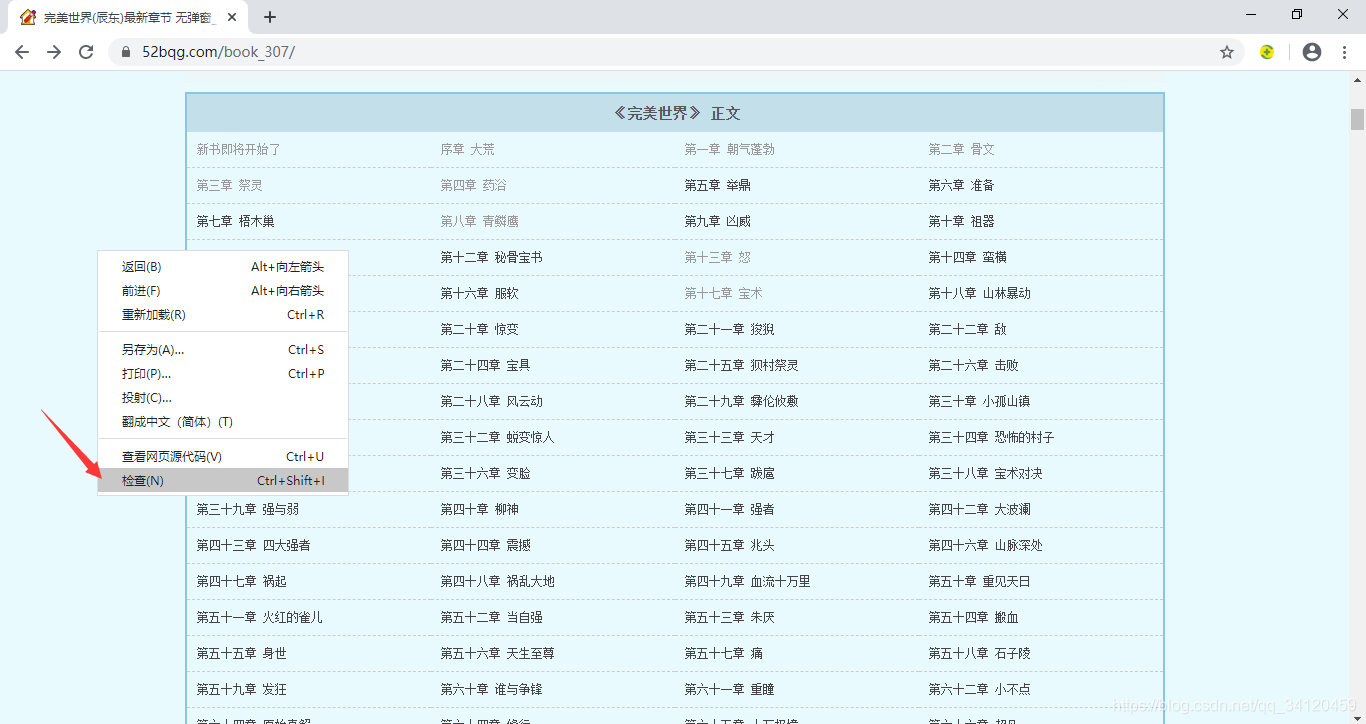
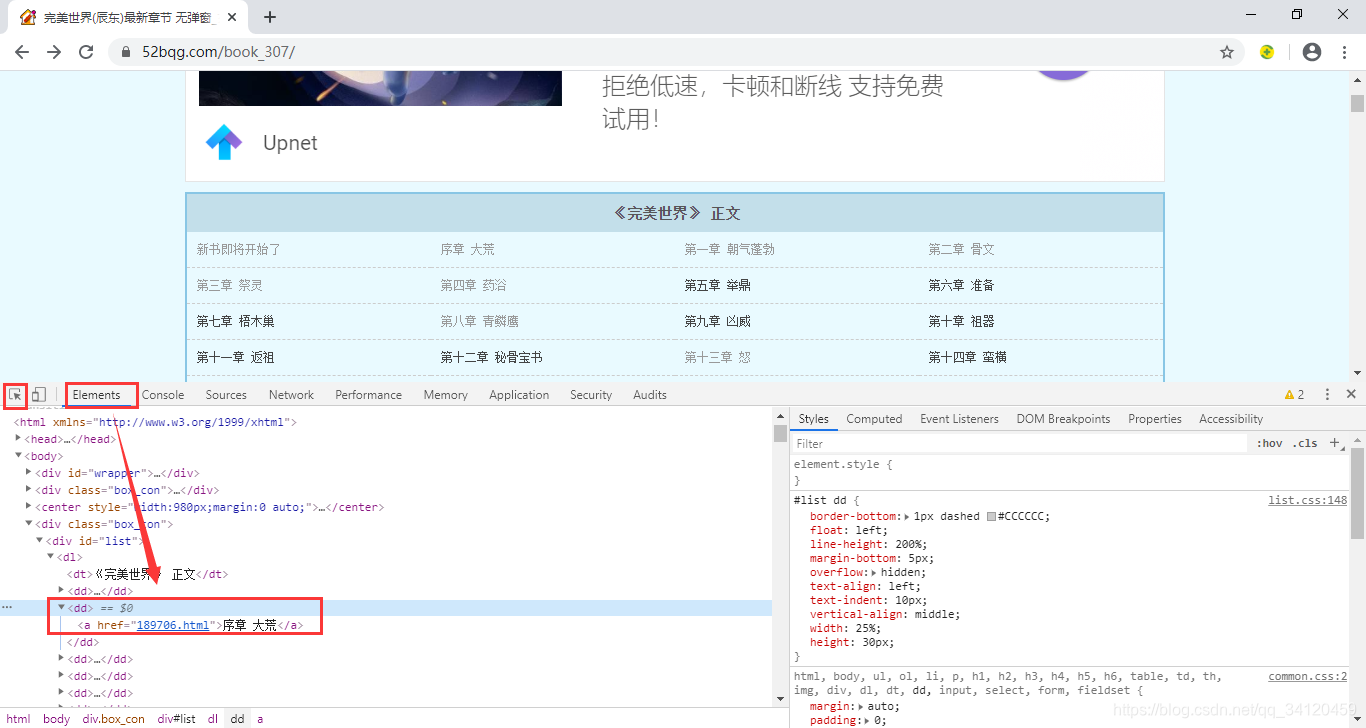
这里我们通过xpath的方式获取需要的内容 ,如果你对xpath不熟悉的话,那我们还可以通过如下的一个小妙招轻松获取xpath路径。
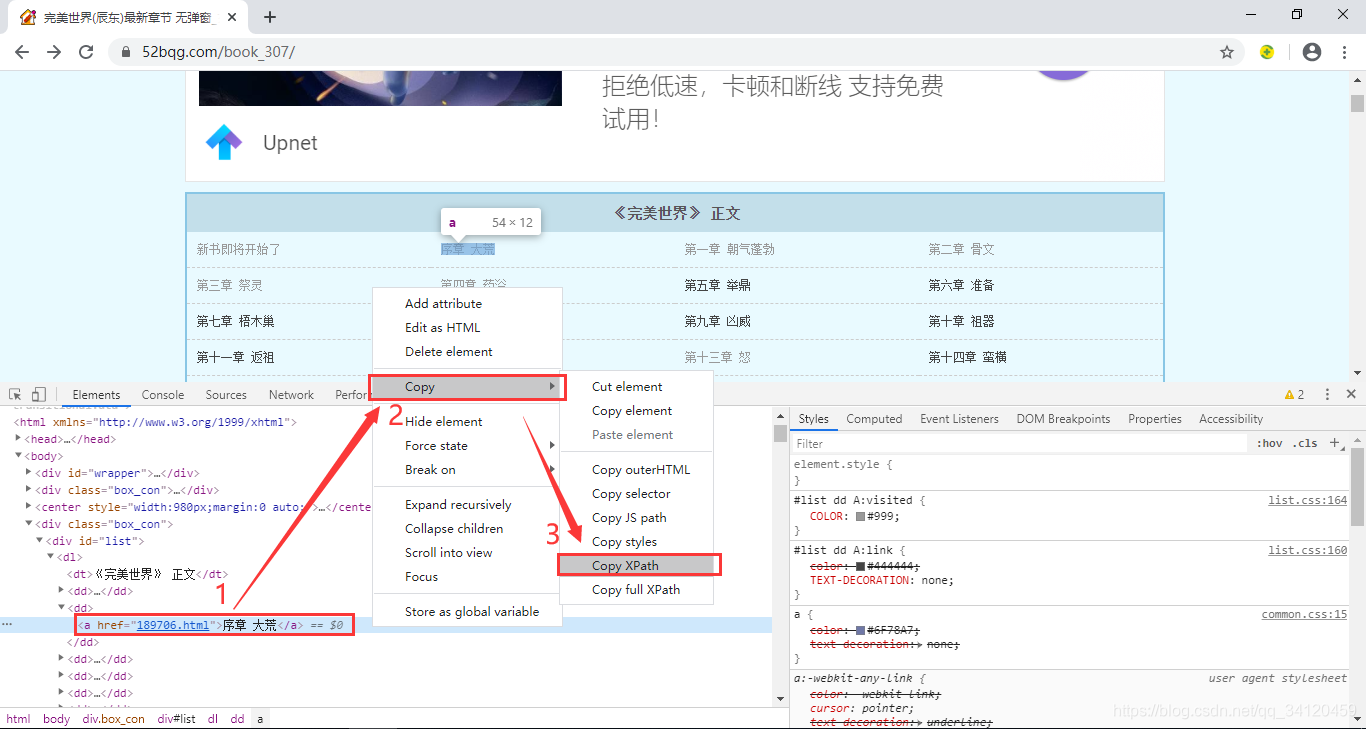
注意:dd[3]代表的是获取第三个dd标签的内容,如果你想获取所有章节名称,那把[3]去掉即可,即:
//*[@id="list"]/dl/dd[3]/a
变为:
//*[@id="list"]/dl/dd/a
代码如下:
#设置爬取小说的函数功能
def get_text(url):
response = requests.get(url, headers=headers)
#最常用的编码方式是utf-8以及gbk,出现乱码可以先尝试这两种
response.encoding = 'gbk'
selector = etree.HTML(response 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









