







学会这招,小姐姐看你的眼神将不一样
- 前言
- 一、爬虫分析
- 二、爬取项目ID
- 1.抓取帖子的URL2.提取帖子中的UUID3.完整代码
- 三、爬取项目的数据
- 写在最后
私信小编01即可获取大量python学习资料
前言
今天某小丽同学来找我,有个实验需要用到轻松筹的数据进行一个分析。可是没有足够的数据,如何办是好?
乐于助人的我,当然不会置之不理~
(ps.毕竟是小姐姐嘛,拒绝了不好,对叭)
于是乎,我抄起家伙,说干就干。
一、爬虫分析
通过简单的分析,可以发现轻松筹提供了一个接口,可以返回某个项目的相关数据,具体如下:
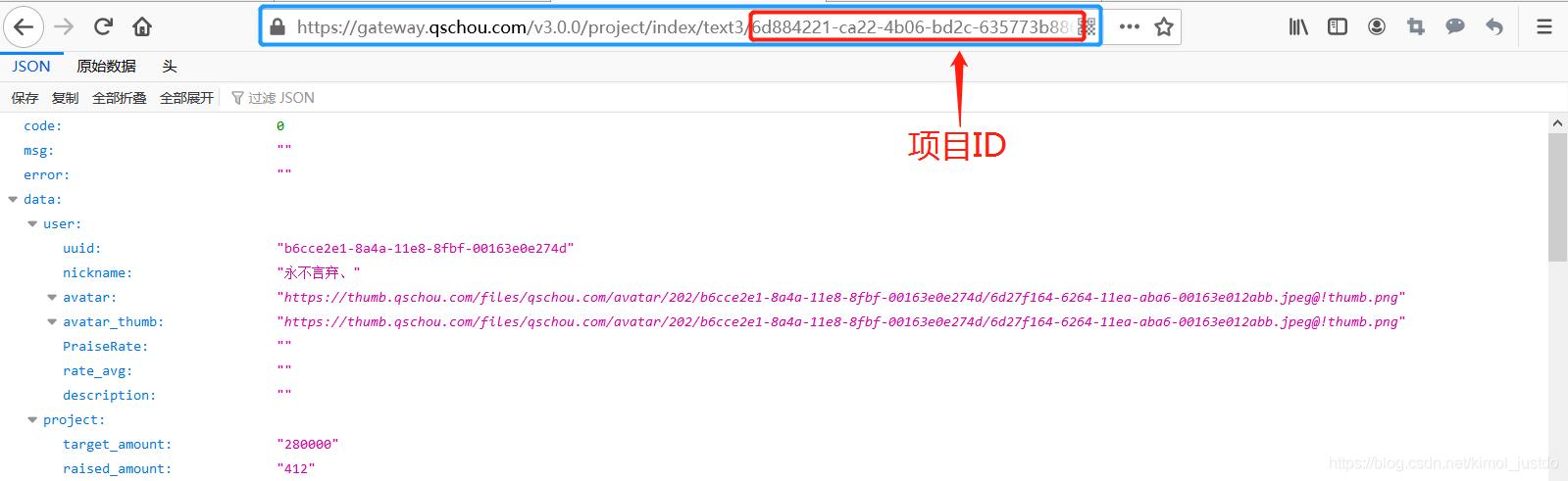
地址如下,xxxxxx表示项目的UUID:
https://gateway.qschou.com/v3.0.0/project/index/text3/xxxxxx
也就是说,我们只要有UUID,那么就可以通过requests发送请求很容易就能得到数据。这还不简单,我们对UUID进行遍历不就行了嘛?
然而,UUID的长度为32位,要是想遍历的话,等明年去叭…
解决问题(小声说:“获得小姐姐的青睐”)的关键就是想办法找到项目的UUID。
二、爬取项目ID
在官网搜寻了一番,并没有发现哪里有UUID。于是,我们只能另辟蹊径。最后,我决定从百度贴吧入手,搜索相关的帖子,并把帖子中的项目链接中的UUID提取出来。
1.抓取帖子的URL
遍历整个“轻松筹吧”,抓取每个帖子的URL:
url_tieba = 'https://tieba.baidu.com/f?kw=轻松筹&ie=utf-8&pn=%d'
# 贴吧页面,pn=0,50,100...p_href = 'href="/p/(.*?)"'hrefs = []for i in range(1):
# 爬取的页数
try:
pn = i*50
res = requests.get(url_tieba%pn)
html = res.text
list_herf = re.findall(p_href,html)
for h in list_herf:
hrefs.append('https://tieba.baidu.com/p/'+h)
print('第%d页获取成功'%(i+1))
except:
passwith open('tiezi_u 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









