






 本文介绍了Redis中四种常用的集合统计模式:聚合统计、排序统计、二值状态统计和基数统计。探讨了每种模式的特点及应用场景,并给出了针对大数据量情况下的优化建议。
本文介绍了Redis中四种常用的集合统计模式:聚合统计、排序统计、二值状态统计和基数统计。探讨了每种模式的特点及应用场景,并给出了针对大数据量情况下的优化建议。
要想选择合适的集合,我们就得了解常用的集合统计模式。
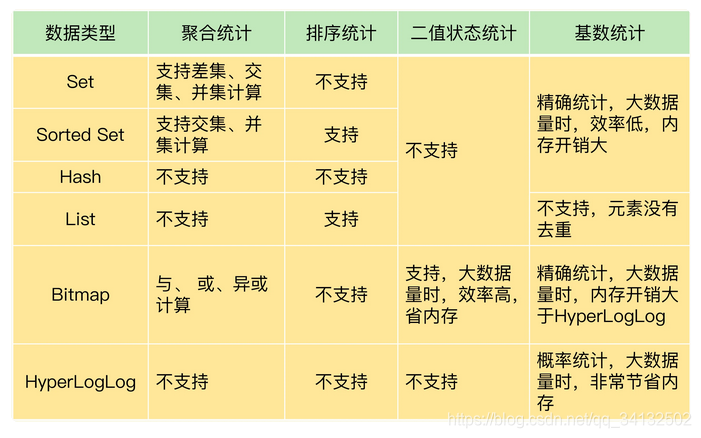
集合类型常见的四种统计模式,包括
- 聚合统计
- 排序统计
- 二值状态统计
- 基数统计
聚合统计
所谓的聚合统计,就是指统计多个集合元素的聚合结果,比如求交集、并集、差集
当你需要对多个集合进行聚合计算时,Set 类型会是一个非常不错的选择。不过,这里有一个潜在的风险。
Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。所以,我们可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计,这样就可以规避阻塞主库实例和其他从库实例的风险了。
排序统计
List 和 Sorted Set 就属于有序集合。
List 是按照元素进入 List 的顺序进行排序的,而 Sorted Set 可以根据元素的权重来排序,我们可以自己来决定每个元素的权重值。
二值状态统计
这里的二值状态就是指集合元素的取值就只有 0 和 1 两种。只需要一位就可以表示,所以我们可以选择bitmap。这是 Redis 提供的扩展数据类型。
基数统计
基数统计就是指统计一个集合中不重复的元素个数。
在 Redis 的集合类型中,Set 类型默认支持去重,所以看到有去重需求时,我们可能第一时间就会想到用 Set 类型。但是当数据量大时,set非常消耗空间。这时候,就要用到 Redis 提供的 HyperLogLog 了。
HyperLogLog 是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。在 Redis 中,每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。

















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









