







Prophet Quick Start
数据格式
Prophet 的输入必须包含两列的数据框:ds 和 y 。
- ds 列必须包含日期(YYYY-MM-DD)或者是具体的时间点(YYYY-MM-DD HH:MM:SS)。
- y 列必须是数值变量,表示我们希望去预测的量。
example_wp_log_peyton_manning.csv下载地址:
import pandas as pd
from prophet import Prophet
# 读入数据集
df = pd.read_csv('data/example_wp_log_peyton_manning.csv')
print(df.tail(5))
"""
ds y
2900 2016-01-16 7.817223
2901 2016-01-17 9.273878
2902 2016-01-18 10.333775
2903 2016-01-19 9.125871
2904 2016-01-20 8.891374
"""
建模流程
通过使用辅助的方法 Prophet.make_future_dataframe 来将未来的日期扩展指定的天数,得到一个合规的数据框。
m = Prophet()
m.fit(df)
# 构建待预测日期数据框,periods = 365 代表除历史数据的日期外再往后推 365 天
horizon = 365
future = m.make_future_dataframe(periods=horizon)
future.tail(5)
"""
ds
3265 2017-01-15
3266 2017-01-16
3267 2017-01-17
3268 2017-01-18
3269 2017-01-19
"""
# 预测
forecast = m.predict(future)
# 通过 Prophet.plot 方法传入预测得到的数据框,可以对预测的效果进行绘图。
fig1 = m.plot(forecast)
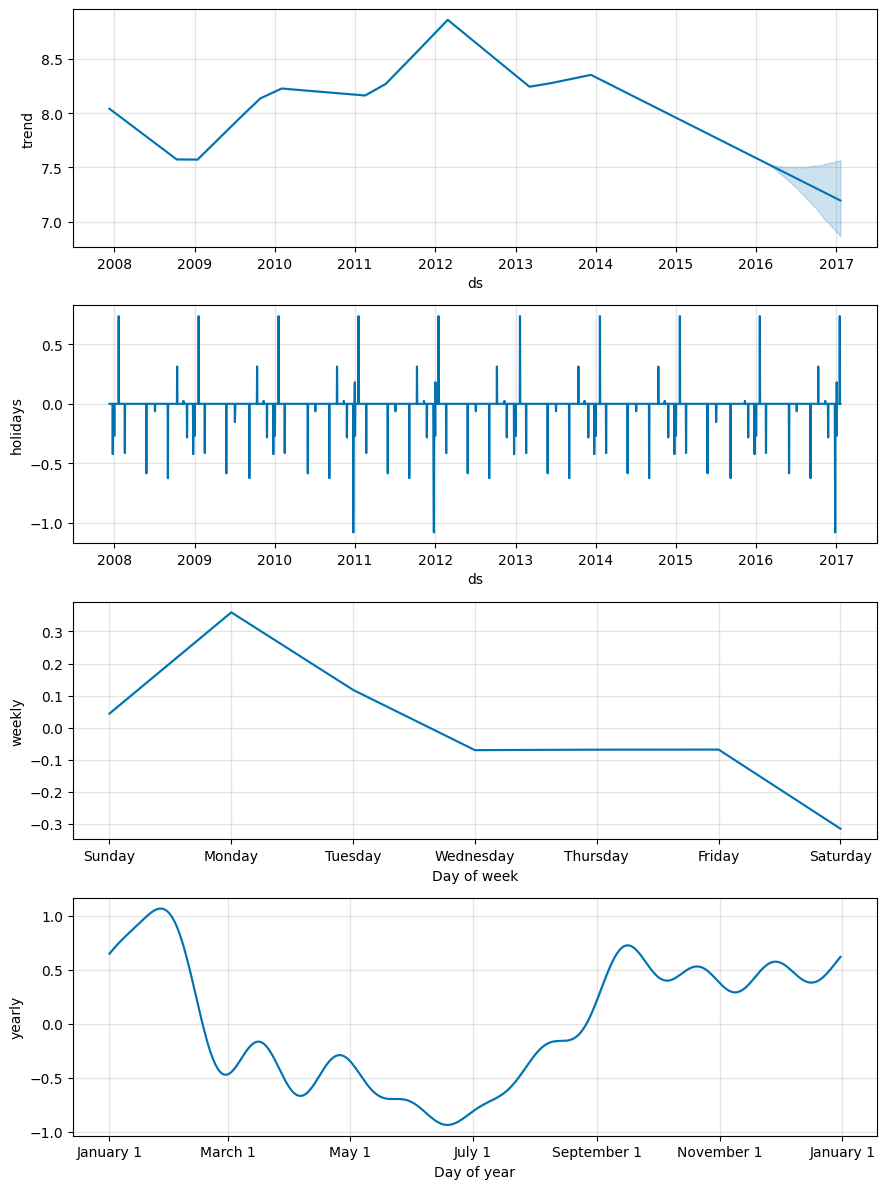
# 使用 Prophet.plot_components 方法。默认情况下,将展示趋势、时间序列的年度季节性和周季节性。如果之前包含了节假日,也会展示出来。
fig2 = m.plot_components(forecast)

如果想查看预测的成分分析,可以使用 Prophet.plot_components 方法。默认情况下,将展示趋势、时间序列的年度季节性和周季节性。如果之前包含了节假日,也会展示出来。

Prophet详解
在前面的文章【Prophet代码实战(一)趋势项调节】和【Prophet代码实战(二)季节项调节】介绍了Prophet算法的趋势项和季节项。接下来我们开始介绍Prophet算法的外部变量
外部变量(需要线性相关)
Prophet内置的节假日
- prophet里内置了python包"holidays"(https://github.com/dr-prodigy/python-holidays)里的所有国家;所有日期的节假日。
- Prophet会将节假日转换为0-1变量,用线性回归的方式判断节假日对观测值的影响。
m = Prophet()
m.add_country_holidays(country_name="US")
m.fit(df)
horizon = 365
future = m.make_future_dataframe(periods=horizon)
# 查看节假日
m.train_holiday_names
"""
0 New Year's Day
1 Martin Luther King Jr. Day
2 Washington's Birthday
3 Memorial Day
4 Independence Day
5 Labor Day
6 Columbus Day
7 Veterans Day
8 Thanksgiving
9 Christmas Day
10 Christmas Day (Observed)
11 Veterans Day (Observed)
12 Independence Day (Observed)
13 New Year's Day (Observed)
dtype: object
"""
fig = m.plot_components(forecast)
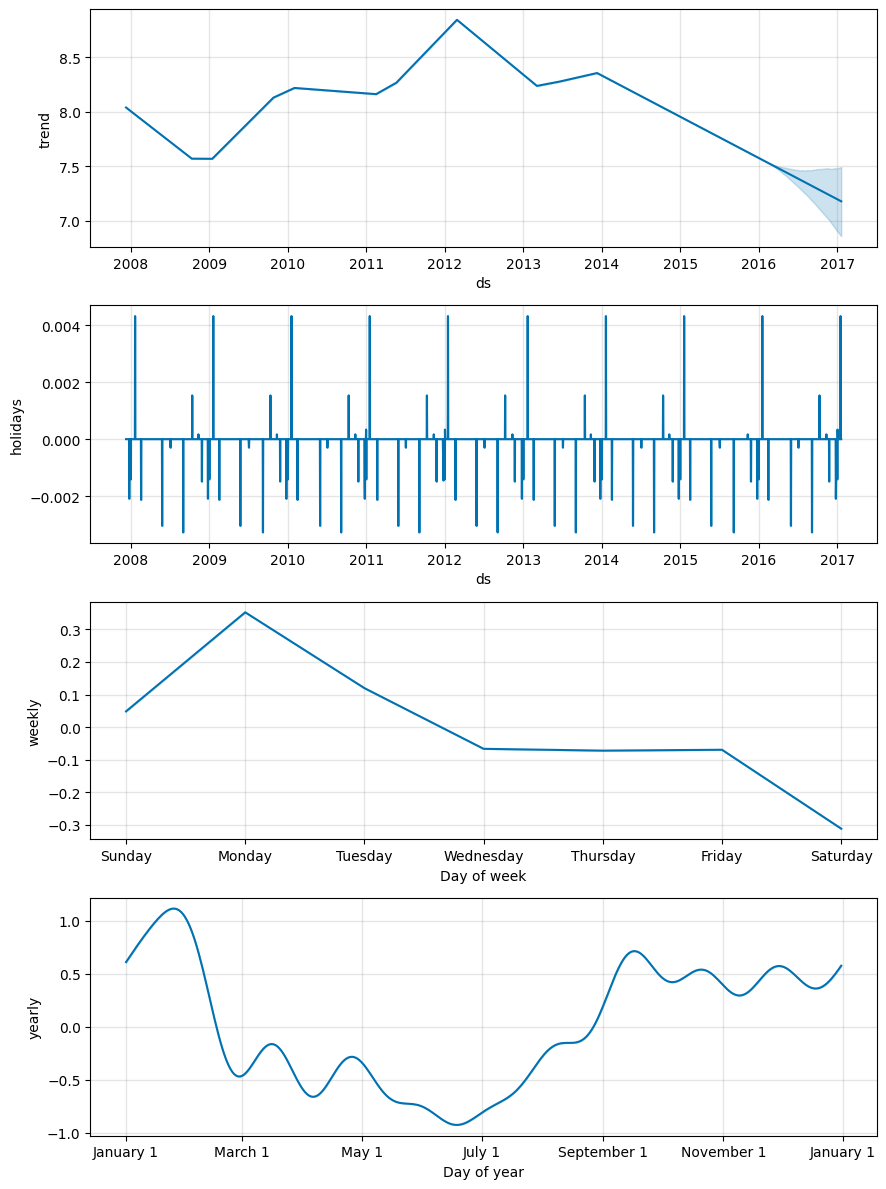
超参数holidays_prior_scale
- 节假日系数先验概率,默认0.1,越大会导致模型结果中节假日影响越大,越容易过拟合,反之欠拟合。
m = Prophet(holidays_prior_scale=0.001)
m.add_country_holidays(country_name="US")
m.fit(df)
horizon = 365
future = m.make_future_dataframe(periods=horizon)
forecast = m.predict(future)
fig = m.plot_components(forecast)
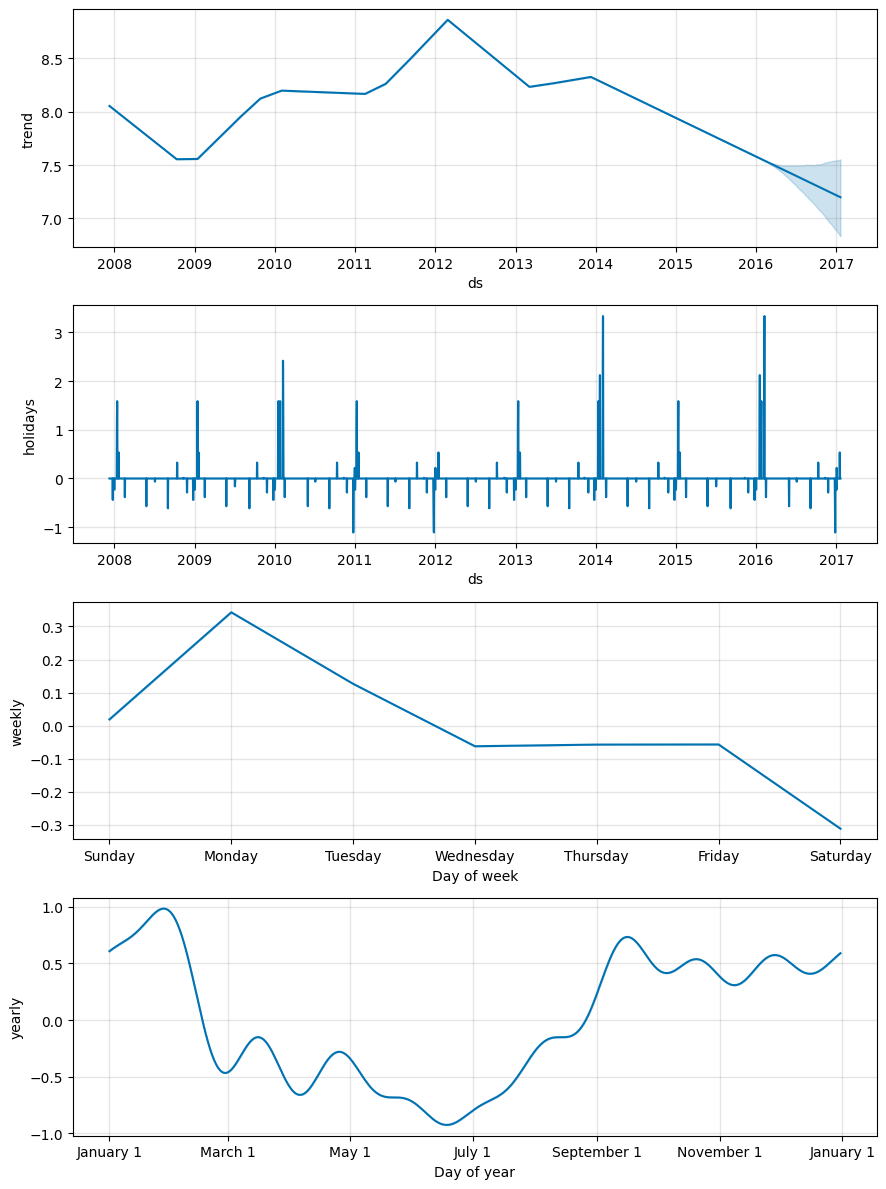
自定义节假日、特殊日期
- 用户可以提供自定义的节假日名称、日期、影响范围(节前几天、节后几天)
- Prophet会将节假日前后的日期转化为0-1变量,用线性回归的方式判断节假日对观测值的影响。
# 自定义两个对运动员的热度具有很大影响的特殊日期:休赛期和超级碗
playoffs = pd.DataFrame({
"holiday":"playoff",
"ds":pd.to_datetime(["2008-01-13", "2009-01-13", "2010-01-16",
"2010-01-24", "2010-02-07", "2011-01-08",
"2013-01-12", "2014-01-12", "2014-01-19",
"2014-02-02", "2015-01-11", "2016-01-17",
"2016-01-24", "2016-02-07"]),
"lower_window":0,
"upper_window":1
})
superbowls = pd.DataFrame({
"holiday":"superbowl",
"ds":pd.to_datetime(["2010-02-07", "2014-02-02", "2016-02-07"]),
"lower_window":0,
"upper_window":1
})
holidays = pd.concat([playoffs,superbowls])
m = Prophet(holidays=holidays)
m.add_country_holidays(country_name="US") # 同时考虑传统节假日和自定义节假日
m.fit(df)
horizon = 365
future = m.make_future_dataframe(periods=horizon)
forecast = m.predict(future)
fig = m.plot_components(forecast)
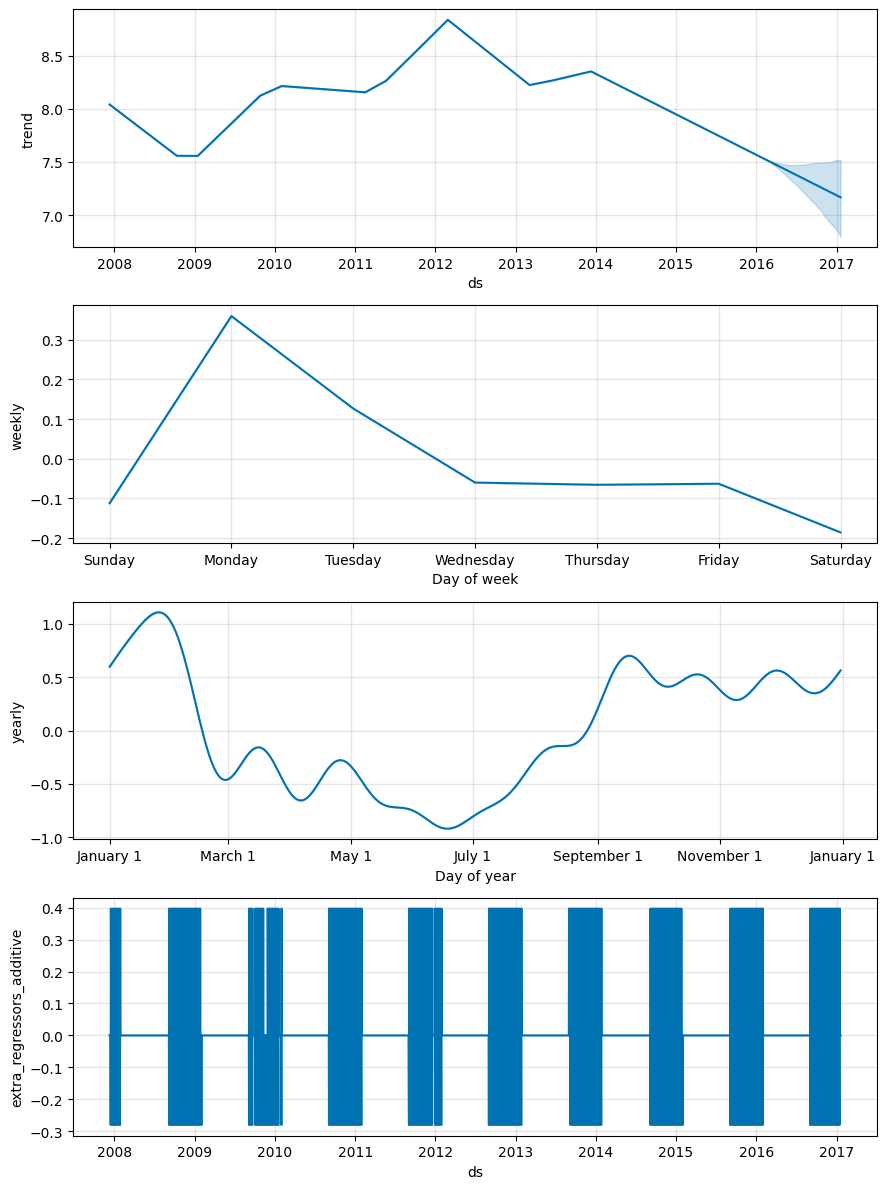
其他外部变量
- 用户可以直接在训练集和测试集的dateframe中加入其他的外部变量字段
- Prophet会用线性回归的方式拟合外部变量对观测值的影响
- 必须保证外部变量在历史和未来都能找到对应的日期和取值
# 添加外部变量:是否时橄榄球赛季的周六、周日
def nfl_sunday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 6 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
def nfl_saturday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 5 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
df["nfl_sunday"] = df["ds"].apply(nfl_sunday)
df["nfl_saturday"] = df["ds"].apply(nfl_saturday)
m = Prophet()
m.add_regressor("nfl_sunday")
m.add_regressor("nfl_saturday")
m.fit(df)
horizon = 365
future = m.make_future_dataframe(periods=horizon)
# 未来日期也需要外部变量的值
future["nfl_sunday"] = future["ds"].apply(nfl_sunday)
future["nfl_saturday"] = future["ds"].apply(nfl_saturday)
forecast = m.predict(future)
fig = m.plot_components(forecast)
超参数调整建议
可调整的超参数
- changepoint_prior_scale:这可能是影响最大的参数,他决定的趋势的灵活性,特别是趋势变化点的变化程度。如果太小,趋势容易欠拟合,过大容易过拟合。0.05是默认值适用大多数时间序列,但可以进行灵活的调整;调整范围[0.001-0.5]
- seasonality_prior_scale:这控制了季节性效应的灵活性,大值可以让季节性适合大的波动,小值可以缩小季节性幅度。默认值是10。通常合理的范围在[0.01-10]
- holidays_prior_scale:这控制了拟合节假日的灵活性。作用与seasonality_prior_scale类似,默认值是10,通常合理的范围在[0.01-10]
- seasonality_mode:选项为[“additive”,“multiplicative”]。默认值是"additive"。商业预测通常选择乘法模式
也许可以调整的超参数
- changepoints_range: 这是历史数据允许趋势变化的最大比例。默认0.8。通常选择[0.8-0.95]
基本不用调整的参数
- growth:选项是"logistic",“linear”,“flat”。有上下限用逻辑斯蒂,有趋势用线性,无趋势用flat
- changepoints:用于手动指定变更趋势的位置点,根据实际业务确定
- n_changepoints:变化点的数量,默认25个足以捕捉典型时间序列的趋势变化,与其增加或者减少变化点的数量,不如专注增减或者减少趋势变化的灵活性,这可能会更加有效,这可以通过调整changepoint_prior_scale实现
- yearly_seasonality:选项是[“auto”,Ture,False]。如果有超过一年的数据建议开启,并通过调整seasonality_prior_scale来调整季节性的影响。默认"auto",数据有一年自动开启,否则关闭
- weekly_seasonality 和 daily_seasonality 同年度季节性超参数一样
- holiday:传递一个指定假期的dataframe
- mcmc_samples:是否需要对季节性分量进行区间估计
- interval_width:预测值置信区间的置信度,默认0.8
- stan_backend:如果同时设置了pystan和cmdstanpy set up, 可以指定后台,预测回事一样的,这个不会被调整



















 2980
2980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











