







第二章 用scikit-learn估计器分类
基于《python数据挖掘入门与实践》这一书的学习笔记,其中数据集和源码可以去图灵社区下载。
一、scikit-learn 估计器
scikit-learn把分类、聚类、回归分析等功能封装成估计器。
估计器主要包括以下两个函数:
fit(): 训练算法,设置内部参数。主要接收训练集,及其类别两个参数。
predict(): 参数为测试集。预测测试集类别,并返回一个包含测试集各条数据类别的数组。
1、近邻算法(KNN)
为了对一个测试集中的个体进行分类,首先把它和训练集中的对象进行匹配,找到和它最相似的对象,这些对象属于哪个类就把测试集中的个体归到哪一个类中。当然也会产生一种问题,有些个体会和训练集中多种对象匹配,就无法判断它属于哪一个类了。
KNN:计算特征值之间的距离,从而进行分类。也就是说如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。如下图所示,判断绿色圆形属于哪个类别。K=3时,红色三角形所占比重(2/3)最大,所以绿色圆形和红色三角形属于同一类别。当K=5时,蓝色正方形所占比重则最大。所以说K值的选取很重要。

2、距离度量
KNN算法中很重要的一环是计算距离。下面介绍几种常见的距离度量方法。
1)欧式距离:真实距离,两点之间的直线距离
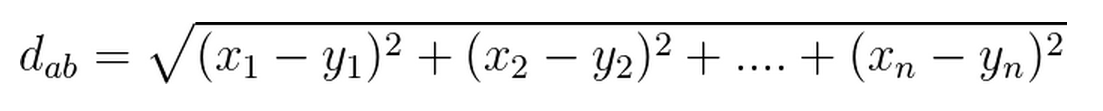
2)曼哈顿距离:两点在标准坐标系中绝对轴距之和
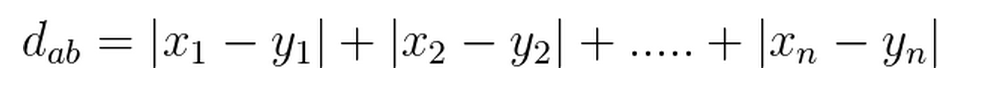
3)余弦距离:特征向量夹角的余弦值(两点看成是空间中的两个向量)
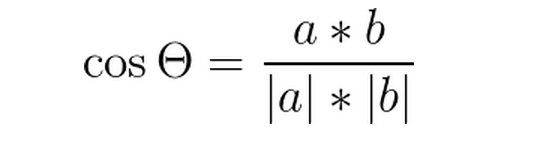
3、数据加载
电离层数据(Ionosphere),数据由高频天线收集的。目的是侦测在电离层和高层大气中存不存在自由电子组成的特殊结构。如果能证明存在特殊结构,就是好的用’g’表示,否则就是坏的,用’b’表示。
数据集下载:
http://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/
下载ionosphere.data和ionosphere.names文件
%matplotlib inline
data_filename = "ionosphere.data"
import csv
import numpy as np
X = np.zeros((351, 34), dtype='float')
y = np.zeros((351,), dtype='bool')
#传统的CSV读取方式,建议使用pandas
with open(data_filename, 'r') as input_file:
reader = csv.reader(input_file)
for i, row in enumerate(reader):
data = [float(datum) for datum in row[:-1]]
X[i] = data
# 如果类别为g,则为1,否则为0
y[i] = row[-1] == 'g'
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=14)
print("训练集有{}个".format(X_train.shape[0]))
print("测试集有{}个".format(X_test.shape[0]))
print("每个样本有{}个特征".format(X_train.shape[1]))
4、训练数据
#导入KNN,默认k=5
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier()
estimator.fit(X_train, y_train)#训练数据
#测试集上测试算法
y_predicted = estimator.predict(X_test)
accuracy = np.mean(y_test == y_predicted) * 100
print("准确率{0:.1f}%".format(accuracy))
结果为:
准确率86.4%
5、交叉验证
在测试集上测试有很大的偶然性,交叉验证能解决上述一次性测试所带来的问题。很简单,多次切分数据集进行试验即可。
1)将整个数据集分成几个部分
2)对于每一个部分进行下面操作:
将其中一部分作为当前测试集
用剩余部分训练算法
在测试集上测试算法
3)记录每次得分及平均得分
4)尽量保证每条数据在测试集中出现一次
sklearn.model_selection.cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’)
estimator:估计器
X:数据集
y:类别
soring:调用的方法(包括accuracy和mean_squared_error等等)
cv:交叉验证生成器或可迭代的次数
n_jobs:同时工作的cpu个数(-1代表全部)
verbose:详细程度
fit_params:传递给估计器的拟合方法的参数
pre_dispatch:控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。
from sklearn.model_selection import cross_val_score
scores = cross_val_score(estimator, X, y, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("准确率为{0:.1f}%".format(average_accuracy))
6、参数调整
KNN算法中影响因子为k的取值。k从1到20,重复多次实验。
avg_scores = []
all_scores = []
parameter_values = list(range(1, 21))
for n_neighbors in parameter_values:
estimator = KNeighborsClassifier(n_neighbors=n_neighbors)
scores = cross_val_score(estimator, X, y, scoring='accuracy')
avg_scores.append(np.mean(scores))
all_scores.append(scores)
from matplotlib import pyplot as plt
plt.figure(figsize=(10,6))
plt.plot(parameter_values, avg_scores, '-o', linewidth=5, markersize=10)

整体上看,随着k增大,正确率不断下降。















 5555
5555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









