







面试问题
- 什么是主从复制?
- 主从复制模式有哪些?
- 主从复制原理?
什么是主从复制
把一台MySQL主服务器(Master主节点)复制到另一台MySQL从服务器(Slove从节点),使两台服务器保持一致的过程叫做主从复制。
底层原理
复制方式
MySQL的主从复制支持两种方式:
- 基于语句(MySQL3.23之前)
- 基于行 (MySQL5.1之后)
本质都是基于主库的binlog来实现的,主库记录binlog,然后从库将binlog在自己的服务器上重放,从而保证了主、从的数据一致性。
binlog有三种存储格式,分别是Statement、Row和Mixed。
-
Statement
基于语句,只记录对数据做了修改的SQL语句,能够有效的减少binlog的数据量,提高读取、基于binlog重放的性能 -
Row
只记录被修改的行,所以Row记录的binlog日志量一般来说会比Statement格式要多。基于Row的binlog日志非常完整、清晰,记录了所有数据的变动,但是缺点是可能会非常多,例如一条update语句,有可能是所有的数据都有修改;再例如altertable之类的,修改了某个字段,同样的每条记录都有改动。 -
Mixed
Statement和Row的结合,怎么个结合法呢。例如像altertable之类的对表结构的修改,采用Statement格式。其余的对数据的修改例如update和delete采用Row格式进行记录。
为什么会有这么多方式呢?因为Statement只会记录SQL语句,但是并不能保证所有情况下这些语句在从库上能够正确的被重放出来。因为可能顺序不对。
MySQL什么时候会记录binlog呢?是在事务提交的时候,并不是按照语句的执行顺序来记录,当记录完binlog之后,就会通知底层的存储引擎提交事务,所以有可能因为语句顺序错误导致语句出错。
核心步骤
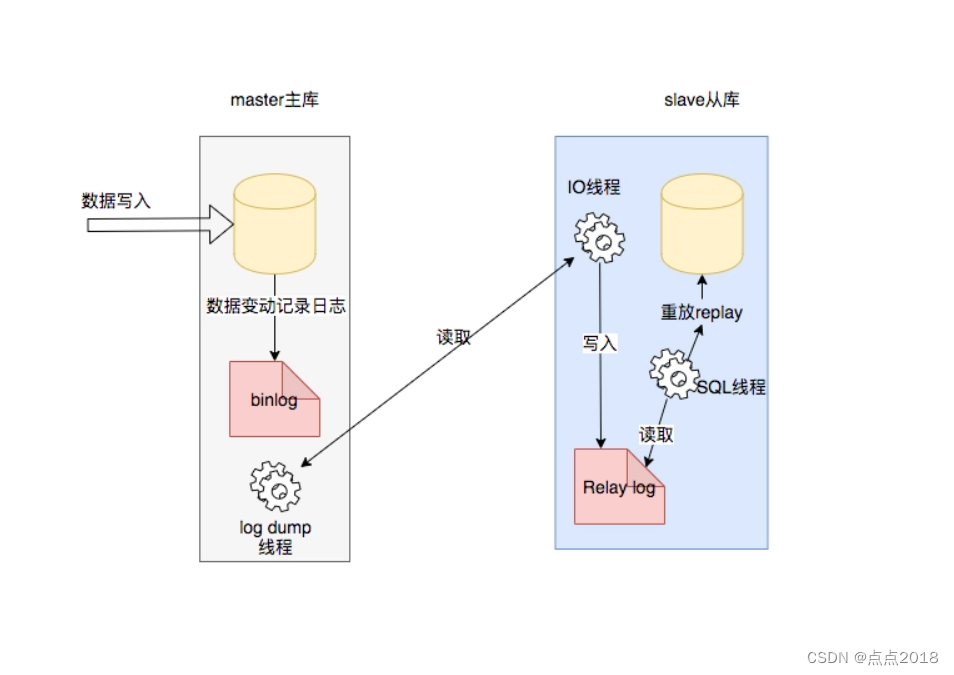
(1) Master的更新事件(update、insert、delete)会按照顺序写入bin-log中。当Slave连接到Master的后,Master机器会为Slave开启 binlog dump线程,该线程会去读取bin-log日志;
(2) Slave连接到Master后,Slave库创建一个I/O线程,通过请求binlog dump,thread读取bin-log日志,然后写入从库的relay log日志中;
(3) Slave还有一个 SQL线程,实时监控 relay-log日志内容是否有更新,解析文件中的SQL语句,在Slave数据库中去执行SQL语句。
复制模型
一主多从(一主一从)
最简单的模型,适合少量写、大量读的情况。
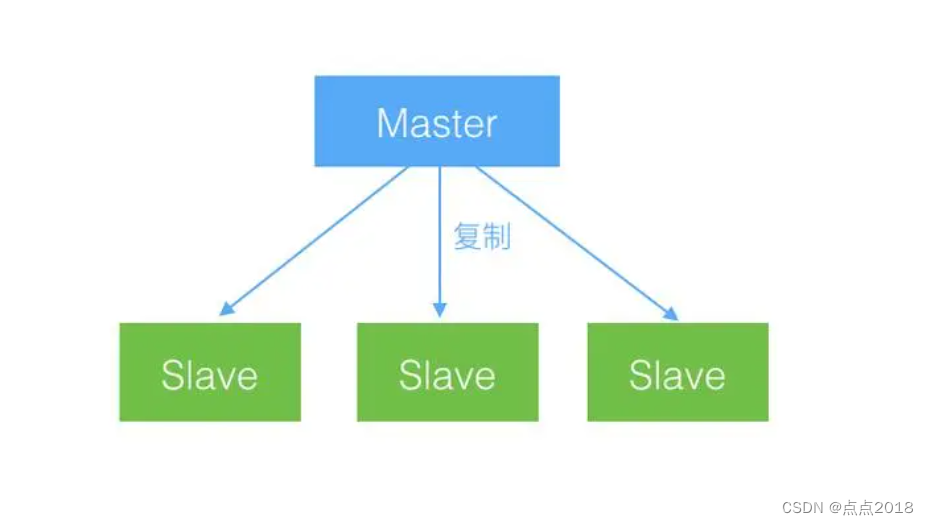
- 把从库当成一个读请求库,帮主库分散压力,提升读并发。
- 把从库当成一个灾备库,除了主从复制之外,没有其他任何的请求和数据传输。
- 把从库当成一个预发环境的数据库(是一种过于理想的用途,因为这还涉及到生产环境数据库的数据敏感性。不是所有人都能够接触到的,需要有完善的权限机制)。
值得注意的是,如果有n个从库,那么主库上就会有n个binlog dump线程。如果这个n比较大的话在复制的时候可能会造成主库的性能抖动。所以在从库较多的情况下可以采用级联复制。
级联复制
级联复制用大白话说就是套娃。
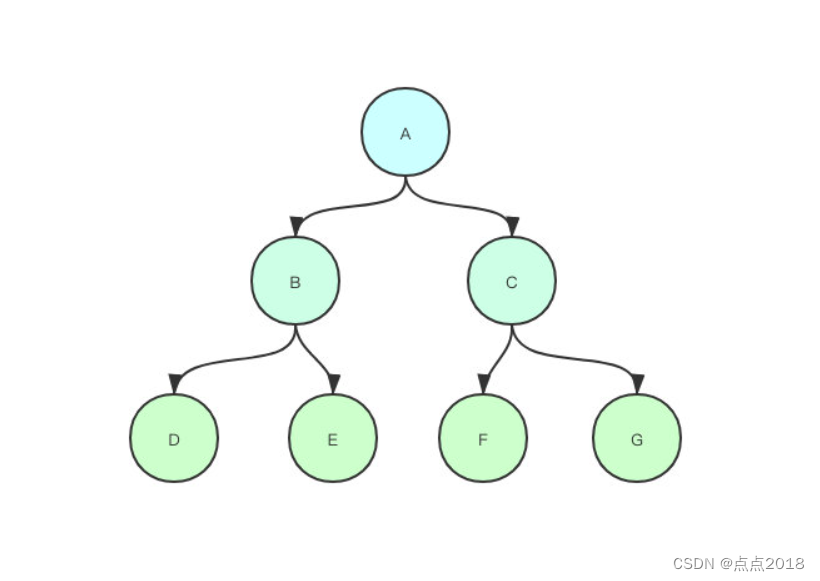
本来从库B、C、D、E、F、G都是复制的主库A,但是现在由于A的压力比较大,就不这么干了,调整成了如下的模式。
B、C复制A
D、E复制B
F、G复制C
- 优点:减轻主库压力,主库只需要关心与其有直接复制关系的从库,剩下的复制则交给从库即可。
- 缺点:由于层层嵌套的关系,如果在较上层出现了错误,会影响到挂在该服务器下的所有子库,这些错误的影响效果被放大了。
主主复制
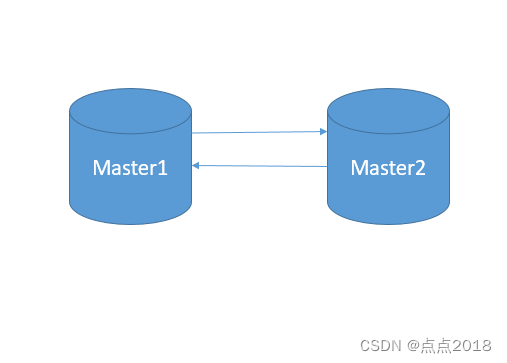
两个主库相互复制,客户端可以对任意一台主库进行写操作。
任何一台主库服务器上的数据发生了变化都会同步到另一台服务器上去。
优点:打破数据库性能瓶颈——横向扩展。
缺点:不可靠,两边的数据冲突的可能性很大。(复制停止,系统仍然在向两个主库中写入数据,一部分数据在A,另一部分的数据在B,但是没有相互复制,且数据也不同步。要修复这部分数据的难度就会变得相当大。)
所以我认为双主的更多的意义在于HA,而不是负载均衡。















 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









