







LTR介绍
搜索排序主要有两个步骤:
- query-doc匹配:寻找与当前输入的query相关度高的docs
- 高相关度docs精确排序:选取更多特征并按照用户点击该doc的可能性大小精确排序
Learning to Rank就是一类目前最常用的,通过机器学习实现步骤2的算法,它主要包含单文档方法(pointwise)、文档对方法(pairwise)和文档列表(listwise)三种类型。
pointwise
- 对于某一个query,将每个doc分别判断与这个query的相关程度,由此将docs排序问题转化为了分类(比如相关、不相关)或回归问题(相关程度越大,回归函数的值越大)。
- pointwise方法只将query与单个doc建模,建模时未将其他docs作为特征进行学习,也就无法考虑到不同docs之间的顺序关系。
pairwise
并不关心某一个doc与query相关程度的具体数值,而是将排序问题转化为任意两个不同docs [公式]和[公式]谁与当前query更相关的相对顺序的排序问题,一般分为 [公式]比[公式] 更相关、更不相关和相关程度相等三个类别,分别记为{+1, -1, 0},由此便又转化为了分类问题
listwise
将一个query对应的所有相关文档看作一个整体,作为单个训练样本
经典算法
RankNet
属于pairwise方法,使用{+1, -1, 0}作为对应的类别标签,然后使用文档对 < d o c i , d o c j > <doci,docj> <doci,docj>作为样本的输入特征,由此将排序问题转化为了分类问题
有一个好处:无需对每个doc与query的相关性进行精确标注(实际大规模数据应用场景下很难获得),只需获得docs之间的相对相关性,相对容易获得,可通过搜索日志、点击率数据等方式获得
xi和xj代表doci和docj的特征,f(x,w)代表打分函数,x和w分别代表输入特征和参数,则文档i和文档j的分数是
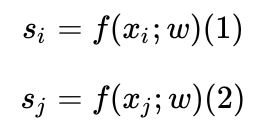
借用了sigmoid函数来定义doci比docj更相关:
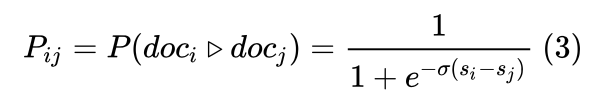
由于Pij是[0,1],但是真实标签是Sij {1,-1,0},所以要映射一下,真实概率:
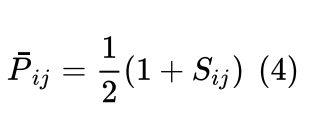
利用交叉熵作为损失函数:


所以Cij关于任一待优化参数 w 的偏导数为
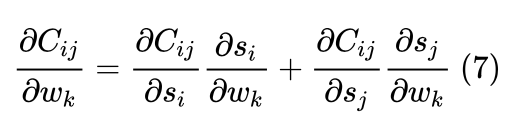
SGD优化:
由于式中的:

可以记
总loss
如何加速训练?
我们把所有文档对<doci,docj>,都把排序高的放前面,则Sij只有{1}
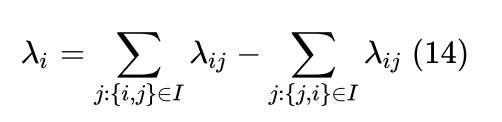
式(14)的含义是:对于文档i:我们首先找到所有相关性排在文档i后面的文档j(组成{i,j} ),并找到所有相关性排在文档i前面的文档k(组成 {k,i} )(排在前面的文档代表相关性更强);再ij求和,其组成了第一项,对所有的ki 求和,其组成了第二项。由于第一项和第二项的求和符号互不关联(互相没有联系),所以第二项中的k可改为j。
举例:


若使用他们进行优化迭代,便将SGD算法转化为了mini-batch SGD算法,如式(21)所示。此时,RankNet在单次迭代时会对同一query下所有docs遍历后更新权值,训练时间得以从
n
2
n^2
n2 降至
n
n
n ,n为单条query下docs的平均数,它被称为RankNet算法的加速训练
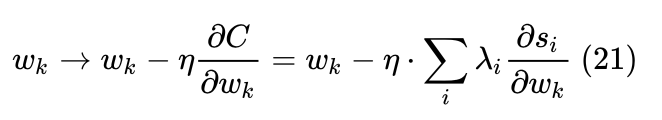
LambdaRank
RankNet以错误pair最少为优化目标,但是仅以错误pair数来评价排序的好坏是不够的,像NDCG或者ERR等信息检索中的评价指标就只关注top k个结果的排序。由于这些指标不可导或导数不存在,当我们采用RankNet算法时,往往无法以它们为优化目标(损失函数)进行迭代,所以RankNet的优化目标和信息检索评价指标之间还是存在差距的。以下图为例:
左边排序1,右边排序2

蓝色表示相关文档,灰色表示不相关文档,RankNet以Error pair(错误文档对数目)的方式计算cost。左边排序1排序错误的文档对(pair)共有13对,故cost为13,右边排序2通过把第一个相关文档下调3个位置,第二个相关文档上条5个位置,将cost降为11,但是像NDCG或者ERR等指标只关注top k个结果的排序,在优化过程中下调前面相关文档的位置不是我们想要得到的结果。上图排序2左边黑色的箭头表示RankNet下一轮的调序方向和强度,但我们真正需要的是右边红色箭头代表的方向和强度,即更关注靠前位置的相关文档的排序位置的提升。LambdaRank正是基于这个思想演化而来,其中Lambda指的就是红色箭头,代表下一次迭代优化的方向和强度,也就是梯度。
具体来说,由于需要对现有的loss或loss的梯度进行改进,而NDCG等指标又不可导,我们便跳过loss,直接简单粗暴地在RankNet加速算法形式的梯度上(式(22))再乘一项,以此新定义了一个Lambda梯度,如式(23)所示。其中Z表示评价指标,可取NDCG、ERR等指标。把交换两个文档的位置引起的评价指标的变化作为其中一个因子
损失函数的梯度代表了文档下一次迭代优化的方向和强度,由于引入了更关注头部正确率的评价指标,Lambda梯度得以让位置靠前的优质文档排序位置进一步提升。有效避免了排位靠前的优质文档的位置被下调的情况发生。LambdaRank相比RankNet的优势在于分解因式后训练速度变快,同时考虑了评价指标,直接对问题求解,效果更明显。此外需要注意的是,由于之前我们并未对得分函数s = f(x,w) 具体规定,所以它的选择比较自由,可以是RankNet中使用的NN,也可以是LambdaMART使用的MART,还可以是GBDT等
信息检索常用指标
MAP
- Precision
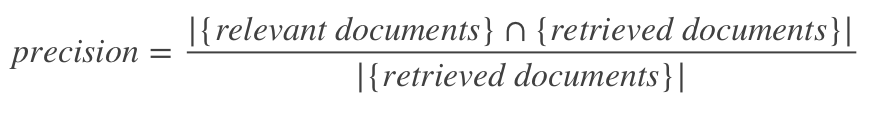
- Recall
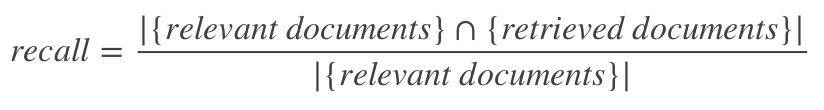
- Average precision(AveP)
把准确率看做是召回率的函数,即: P = f ( R ) P=f(R) P=f(R),也就是随着召回率从0到1,准确率的变化情况。AveP计算方式可以简单的认为是:
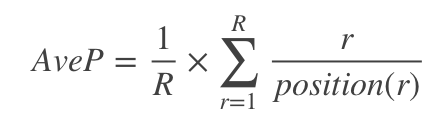
其中 R R R表示相关文档的总个数, p o s i t i o n ( r ) position(r) position(r)
表示,结果列表从前往后看,第 r r r个相关文档在列表中的位置。比如,有三个相关文档,位置分别为1、3、6,那么 A v e P = 1 / 3 × ( 1 / 1 + 2 / 3 + 3 / 6 ) AveP=1/3×(1/1+2/3+3/6) AveP=1/3×(1/1+2/3+3/6)。在编程的时候需要注意,位置和第i个相关文档,都是从1开始的,不是从0开始的
AveP意义是在召回率从0到1逐步提高的同时,对每个R位置上的P进行相加,也即要保证准确率比较高,才能使最后的AveP比较大
- Mean average precision(MAP):
通常会用多个查询语句来衡量检索系统的性能,所以应该对多个查询语句的AveP(the mean of average precision scores),求均值
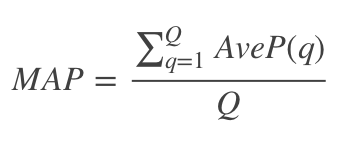
nDCG
在MAP计算公式中,文档只有相关不相关两种,而在nDCG中,文档的相关度可以分多个等级进行打分
- Cumulative Gain(CG)
表示前p个位置累计得到的效益,公式如下
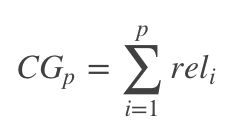
其中 r e l i reli reli表示第i个文档的相关度等级,如:2表示非常相关,1表示相关,0表示无关,-1表示垃圾文件 - Discounted cumulative gain(DCG)
由于在CGp的计算中对位置信息不敏感,比如检索到了三个文档相关度依次是{3,-1,1}和{-1,1,3},显然前面的排序更优,但是它们的CG相同,所以要引入对位置信息的度量计算
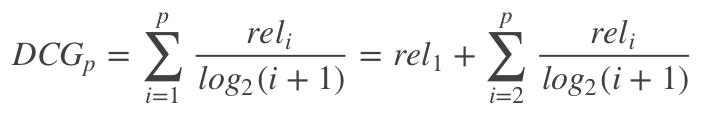
- Ideal DCG(IDCG)
IDCG是理想情况下的DCG,即对于一个查询语句和p来说,DCG的最大值
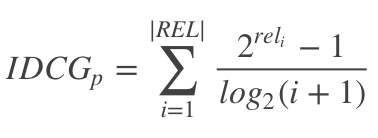
其中 ∣ R E L ∣ |REL| ∣REL∣表示,文档按照相关性从大到小的顺序排序,取前p个文档组成的集合。也就是按照最优的方式对文档进行排序 - Normalize DCG(nDCG)
由于每个查询语句所能检索到的结果文档集合长度不一,p值的不同会对DCG的计算有较大的影响。所以不能对不同查询语句的DCG进行求平均,需要进行归一化处理
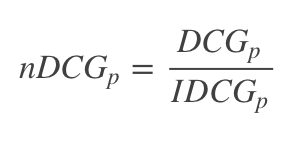
ERR
- Mean reciprocal rank (MRR)
MRR是指多个查询语句的排名倒数的均值,其中 r a n k i rank_i ranki表示第i个查询语句的第一个正确答案的排名
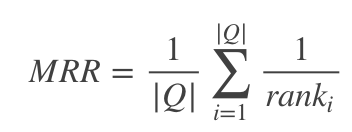
- Expected reciprocal rank (ERR)
区别RR是计算第一个相关文档的位置的倒数,ERR表示用户的需求被满足时停止的位置的倒数的期望。首先是计算用户在位置 r r r停止的概率 P P r PP_r PPr,如下所示
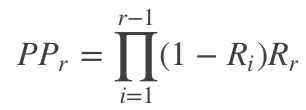
其中 R i R_i Ri是关于文档相关度等级的函数,可以选取如下的函数
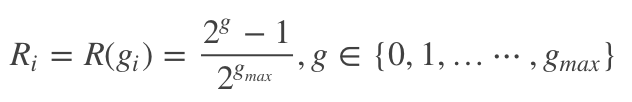
那么ERR的计算公式如下:
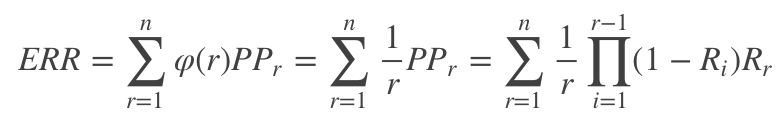
更通用一点,ERR不一定计算用户需求满足时停止的位置的倒数的期望,可以是其它基于位置的函数 φ ( r ) φ(r) φ(r),只要满足 φ ( 0 ) = 1 φ(0)=1 φ(0)=1,且 φ ( r ) → 0 φ(r)→0 φ(r)→0随着 r → ∞ r→∞ r→∞
指标代码实现
import numpy as np
def average_precision(gt, pred):
if not gt:
return 0.0
score = 0.0
num_hits = 0.0
for i,p in enumerate(pred):
if p in gt and p not in pred[:i]:
num_hits += 1.0
score += num_hits / (i + 1.0)
return score / max(1.0, len(gt))
def NDCG(gt, pred, use_graded_scores=False):
score = 0.0
for rank, item in enumerate(pred):
if item in gt:
if use_graded_scores:
grade = 1.0 / (gt.index(item) + 1)
else:
grade = 1.0
score += grade / np.log2(rank + 2)
norm = 0.0
for rank in range(len(gt)):
if use_graded_scores:
grade = 1.0 / (rank + 1)
else:
grade = 1.0
norm += grade / np.log2(rank + 2)
return score / max(0.3, norm)
def metrics(gt, pred, metrics_map):
out = np.zeros((len(metrics_map),), np.float32)
if ('MAP' in metrics_map):
avg_precision = average_precision(gt=gt, pred=pred)
out[metrics_map.index('MAP')] = avg_precision
if ('RPrec' in metrics_map):
intersec = len(gt & set(pred[:len(gt)]))
out[metrics_map.index('RPrec')] = intersec / max(1., float(len(gt)))
if 'MRR' in metrics_map:
score = 0.0
for rank, item in enumerate(pred):
if item in gt:
score = 1.0 / (rank + 1.0)
break
out[metrics_map.index('MRR')] = score
if 'MRR@10' in metrics_map:
score = 0.0
for rank, item in enumerate(pred[:10]):
if item in gt:
score = 1.0 / (rank + 1.0)
break
out[metrics_map.index('MRR@10')] = score
if ('NDCG' in metrics_map):
out[metrics_map.index('NDCG')] = NDCG(gt, pred)
return out
测试
gt_doc_ids = {0,1,2}
pred_doc_ids = [9,8,7,6,5,4,3,2,1,0]
result = metrics(
gt=gt_doc_ids, pred=pred_doc_ids, metrics_map=METRICS_MAP)
print(result)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









