







大数据挖掘研究
(1)基于内存数据分解的方式:随着数据集越来越大,计算机无法一次性地将大数据集读入内存,数据分解技术采用分而治之的思想,将大数据集分割成一块块小数据集读入内存,然后进行挖掘,最后合并挖掘结果,大大提高了挖掘效率
(2)基于磁盘存储的方式:由于内存空间较小,不能整体地将大数据集进行处理,因此需要将一部分数据存放在磁盘上,这样能够有更多的内存空间来处理后面的数据。
(3)基于采样的方式,采样方法是统计学经常采用的技术,我们可以从大规模数据集中抽取出能够反映大数据集的样本,然后对大数据集样本进行挖掘。
序列模式挖掘概念
概念:输入一个序列数据库,输出所有不小于最小支持度的序列的过程。
应用领域:预测用户购买行为、预测Web访问模式、预测天气变化、预测时长趋势。
序列模式挖掘和关联规则挖掘的区别
序列模式是找出序列数据库中数据之间的先后顺序。比如:用户访问某个网站各个网页的顺序。
关联规则是找出事务数据库中数据之间的并发关系。比如:啤酒和尿布
关联规则挖掘不关注事务之间的先后顺序,序列模式挖掘需要考虑序列间的先后顺序。
经典算法
AprioriAll算法
定义
每一次交易包含customer-id,transaction-time和items
序列s的支持度(support)是指所有序列中包含序列s的个数(百分比)
满足最小支持度(minimum support)的序列称为大序列(large sequence)。
大序列中的所有最长序列就称为序列模式(sequential pattern)
项集i的支持度是指所有序列中包含项集i的个数
满足最小支持度的项集称为大项集
算法
(1)排序阶段
对数据库进行排序整理,将原始数据库转换成序列数据库。例如交易数据库就以客户号(Cust_id)和交易时间(Tran_time)来排序。如下:
(2)大项集阶段
找出所有的频繁的项集(Litemset)。同时得到large 1-sequence的组合。在上面Table2给出的顾客序列数据库中,假设支持数为2,则大项集分别是(30),(40),(70),(40,70)和(90)。实际操作中,经常将大项集被映射成连续的整数。例如,上面得到的大项集映射成Table3对应的整数。当然,这样的映射纯粹是为了处理的方便和高效
(3)转换阶段
寻找序列模式时,我们需要检查给定的大序列(由litemsets组成的large sequence)是否包含在客户序列中,为了加速这一过程,就需要对复杂客户数据进行转化。即,将Table2 数据表使用Table3映射表进行转化,结果如Table4所示。



使用“大项集”阶段得到Litemsets(Table3)来替换交易数据中的每一件事务。规则1:如果该事务中不包含任何litemsets,则删除事务;原则2:如果一个顾客序列中不包含任何litemsets,则删除序列。例如ID-2中的事务(10 20)不包含任何litemsets,所以删除;而(40 60 70)被litemsets中的{(40) (70) (40 70)}替换。
(4)序列阶段
发现large sequence,设计算法AprioriAll和AprioriSome
Count-all算法遍历所有的largesequences,包括非最大序列(non-maximal sequences)。AprioriAll算计是基于Apriori算法查找大项集,扩展到序列挖掘。
Count-Some算法包括AprioriSome和DynamicSome。算法思想:因为我们只对maximalsequences感兴趣,如果我们先遍历longer sequences,则可以避免longer sequences的包含序列。Longer sequences是没经过支持度检查的候选集序列。
(5)最大序列阶段
在large sequences中发现maximal sequences(序列模式),此步骤可能包含在上步骤的算法中。

GSP算法
FreeSpan算法
PrefixSpan算法
先明确什么是前缀和投影
PrefixSpan算法也类似,它从长度为1的前缀开始挖掘序列模式,搜索对应的投影数据库得到长度为1的前缀对应的频繁序列,然后递归的挖掘长度为2的前缀所对应的频繁序列,一直递归到不能挖掘到更长的前缀挖掘为止
举例说明:
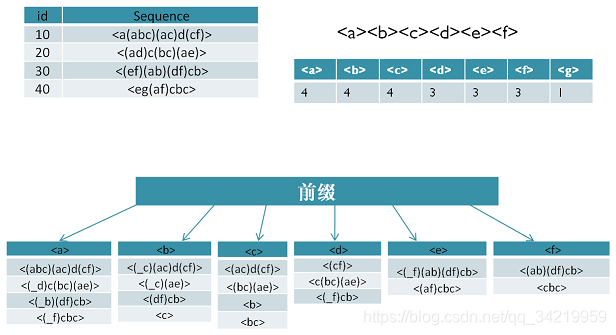
支持度阈值为50%。里面长度为1的前缀包括< a >, < b >, < c >, < d >, < e >, < f >,< g >我们需要对这6个前缀分别递归搜索找各个前缀对应的频繁序列。如下图所示,每个前缀对应的后缀也标出来了。由于g只在序列4出现,支持度计数只有1,因此无法继续挖掘。我们的长度为1的频繁序列为< a >, < b >, < c >, < d >, < e >,< f >。去除所有序列中的g,即第4条记录变成<e(af)cbc>
现在我们开始挖掘频繁序列,分别从长度为1的频繁项开始。这里我们以d为例子来递归挖掘,其他的节点递归挖掘方法和D一样。方法如下图,首先我们对d的后缀进行计数,得到{a:1, b:2, c:3, d:0, e:1, f:1,_f:1}。注意f和_f是不一样的,因为前者是在和前缀d不同的项集,而后者是和前缀d同项集。由于此时a,d,e,f,_f都达不到支持度阈值,因此我们递归得到的前缀为d的2项频繁序列为和。接着我们分别递归db和dc为前缀所对应的投影序列。首先看db前缀,此时对应的投影后缀只有<_c(ae)>,此时_c,a,e支持度均达不到阈值,因此无法找到以db为前缀的频繁序列。现在我们来递归另外一个前缀dc。以dc为前缀的投影序列为<_f>, <(bc)(ae)>, ,此时我们进行支持度计数,结果为{b:2, a:1, c:1, e:1, _f:1},只有b满足支持度阈值,因此我们得到前缀为dc的三项频繁序列为。我们继续递归以为前缀的频繁序列。由于前缀对应的投影序列<(_c)ae>支持度全部不达标,因此不能产生4项频繁序列。至此以d为前缀的频繁序列挖掘结束,产生的频繁序列为。
同样的方法可以得到其他以< a>, < b>, < c>, < e>, < f>为前缀的频繁序列


算法比较
Apriori All 算法会产生大量的候选项集,尤其是当挖掘频繁序列长度增加时,产生的候选项集呈现指数式增长,因此需要消耗大量的存储空间。此外还需要扫描投影数据库,也需要消耗大量的扫描时间。
尽管 GSP算法和Apriori All算法都属于Apriori类,但是GSP算法能够在一定程度上减少候选序列的数量,因此总体效率比Apriori All算法高很多。
Free Span算法是基于模式增长的算法,不会产生大量的候选项集,并且每一次仅仅扫描投影数据库,而不是扫描原数据库的候选序列,比类 Apriori 的算法效率要高的多,尤其在支持度较低时更为明显。Free Span 的缺点有两个方面:(1)在挖掘的过程中会产生大量的投影数据库。(2)产生的候选序列很多,需要考虑每一个候选序列的组合情况,因此造成了很大的开销。
Prefixspan算法是对Free Span算法的改进,不会产生候选序列模式,另外Prefix Span算法也需要构造大量的投影数据库,造成较大的开销但Prefix Span算法比Free Span算法的收缩速度快,它能够大大缩减搜索空间,缩小投影数据库的规模。

所以最推荐使用Prefixspan算法,使用大数据平台的分布式计算能力也是加快PrefixSpan运行速度一个好办法。比如Spark的MLlib就内置了PrefixSpan算法














 4692
4692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









