







使用开发工具idea2022,java1.8版本,利用spire.pdf往一个现成的pdf中写入文本信息,经过一番研究,实现了,现在贴出代码分享:
首先导入Spire.Pdf.jar到maven汇总,因为我采用他的官网在pom中加依赖老是失败,所以就直接下载了jar包,然后导入到程序中,jar下载链接如下:
思路:
找到你需要写入的文本旁边的一个关键信息,然后计算那个关键信息的坐标,稍微加一些偏移,就完成了:你需要先提供好一个需要操作的pdf文档
import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import com.spire.pdf.*; import com.spire.pdf.PdfDocument; import com.spire.pdf.general.find.*; import com.spire.pdf.graphics.*; import java.awt.*; import java.awt.geom.Rectangle2D;
/*获取冰蓝spire.pdf某个文字坐标系的方法
txt:某个需要找到的文字坐标
newText:某个需要写入的内容
原理为找到txt所在的坐标,适当做一些偏移,就可以写入新的内容了
*/
private static void replaceTxt(String txt,String newText){
//创建 PdfDocument 类的对象
PdfDocument doc = new PdfDocument();
//载入PDF文档
doc.loadFromFile("E:\\check.pdf");
//获取文档的第一页
PdfPageBase page = doc.getPages().get(0);
//搜索需要替换的旧文本
PdfTextFindCollection collection = page.findText(txt,false);
//创建 PdfTrueTypeFont 类的对象以设置字体
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("华文中宋", Font.PLAIN, 12));
PdfTextFind findObj=collection.getFinds()[0];
Rectangle2D.Float rec = (Rectangle2D.Float) findObj.getBounds();
//page.getCanvas().drawRectangle(PdfBrushes.getWhite(), rec);//此处会将找到的地方刷白,覆盖掉
//绘制文本
page.getCanvas().drawString(newText, font, PdfBrushes.getBlack(), rec.getX()+50, rec.getY() - 3);
String result = "E:\\check666.pdf";
//保存文档
doc.saveToFile(result, FileFormat.PDF);
}
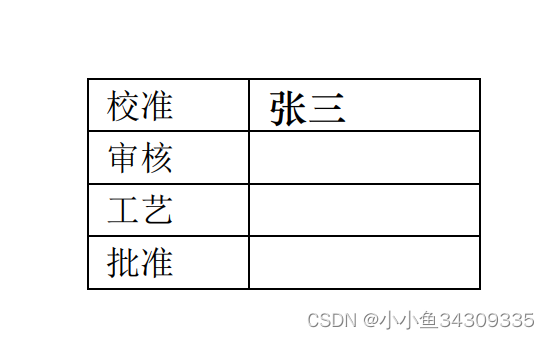
写入前:

写入后:















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









