






一 ,基本概念 :
1 ,hive 中的表的构成 :
- 真实数据 : 以文件的形式,存储在 hdfs / s3 上
- 元数据 : 将表映射到文件,元数据存储在 mysql / oracle 中
2 ,内部表 :
- hive 自己维护真实数据
- 删除 : 元数据删除,真实数据删除
3 ,外部表 :
- hdfs / s3 维护真实数据
- 删除 : 只删除元数据,不删除真实数据
4 ,建表 :
create table student(tid int,tname string);
5 ,查看表结构 :
desc student;
二 ,内部表 : csv
1 ,创建内部表 :
create table t1 (tid int,tname string,age int);
2 ,查看所有表 :
show tables;
3 ,查看表结构 :
desc t1;
4 ,默认位置 : HDFS
例如 :
hdfs://ip-172-31-18-72.cn-northwest-1.compute.internal:8020/user/hive/warehouse/t1
5 ,mysql 查看存储信息 :
找到这张表 : SDS
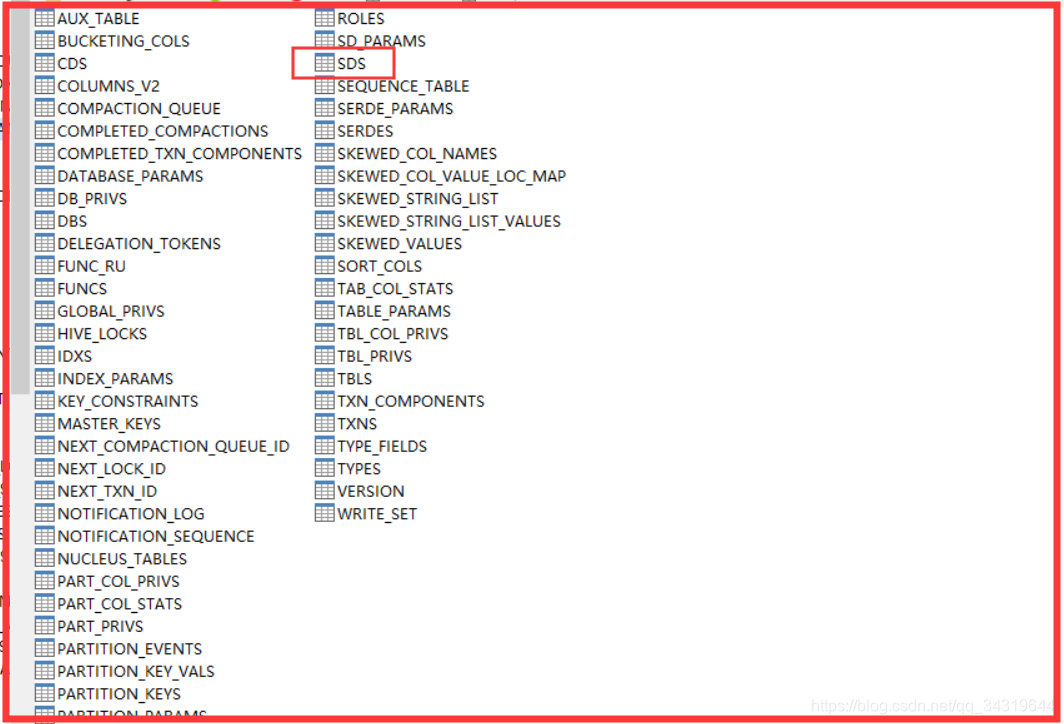
6 ,建内部表,指定位置 : ( 注意 s3a / s3 )
create table t2 (tid int,tname string,age int) location ‘s3://lifecyclebigdata/dataWareHouse/BALABALA/06_hive_inner/t2’;
7 ,内部表,位置,分隔符 :
create table t3(tid int,tname string,age int) row format delimited fields terminated by ‘,’ location ‘s3://lifecyclebigdata/dataWareHouse/BALABALA/06_hive_inner/t3’;
8 ,建表 student :
use default;
create table student(tid int,tname string,tage int,taddr string,tclass string,tcourse string,tstore int) row format delimited fields terminated by ',' location 's3://lifecyclebigdata/dataWareHouse/BALABALA/06_hive_inner/student';
9 ,造数据 : student.csv
1,sfl,206,yingkou,314,yuwen,98
2,wtt,207,yingkou,324,shuxue,99
3,sswen,806,yingkou,314,yuwen,18
4,sswu,296,yingkou,344,shuxue,28
5,sjw,2010,yingkou,354,yuwen,93
6,sjy,226,yingkou,316,shuxue,94
7,ssx,236,yingkou,317,yuwen,95
8,wdd,246,tongliao,384,shuxue,68
9,stm,256,tongliao,394,yuwen,97
10,stx,606,tongliao,114,shuxue,18
11,szx,706,tongliao,124,yuwen,92
10 ,将数据上传搭配 s3 :
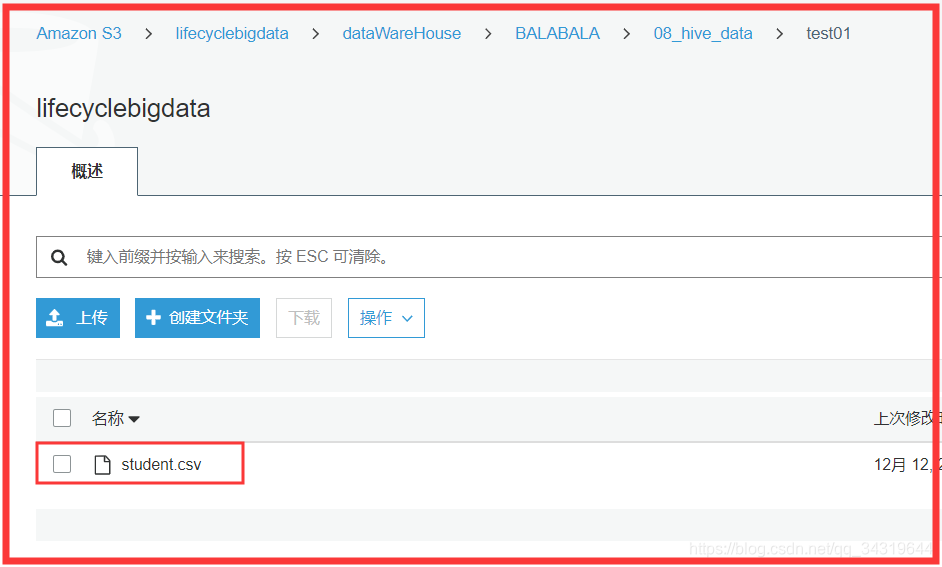
11 ,转换成 parquet :
package lifecycle00_test
import lifecycle01_tool.{Tool}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
// 文件格式转换 :
// snappy,parquet
object Test01 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = Tool.getLocalSpark()
import spark.implicits._
import spark.sqlContext.implicits._
// 1 ,读文件 :
// 1,sfl,206,yingkou,314,yuwen,98
val rdd: RDD[Row] = spark.sparkContext.textFile("s3a://lifecyclebigdata/dataWareHouse/BALABALA/08_hive_data/test01")
.map(_.split(","))
.map(line => Row(line(0).toInt,line(1),line(2).toInt,line(3),line(4).toInt,line(5),line(6).toInt))
// 2 ,元数据
val structType = StructType(Array( StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true),
StructField("addr", StringType, true),
StructField("clazz", IntegerType, true),
StructField("course", StringType, true),
StructField("score", IntegerType, true)))
// 3 ,建表 :
val res: DataFrame = spark.createDataFrame(rdd, structType)
// 4 ,写出
res.write.option("compression","snappy").option("delimiter",",").parquet("s3a://lifecyclebigdata/dataWareHouse/BALABALA/08_hive_data/test02")
spark.close()
}
}
12 ,导入数据 :csv
load data inpath "s3://lifecyclebigdata/dataWareHouse/BALABALA/08_hive_data/test01/student.csv" into table student;
13 ,查询数据 : hive-cli
select * from student;
1 sfl 206 yingkou 314 yuwen 98
2 wtt 207 yingkou 324 shuxue 99
3 sswen 806 yingkou 314 yuwen 18
4 sswu 296 yingkou 344 shuxue 28
5 sjw 2010 yingkou 354 yuwen 93
6 sjy 226 yingkou 316 shuxue 94
7 ssx 236 yingkou 317 yuwen 95
8 wdd 246 tongliao 384 shuxue 68
9 stm 256 tongliao 394 yuwen 97
10 stx 606 tongliao 114 shuxue 18
11 szx 706 tongliao 124 yuwen 92
14 ,spark-cli :
结果 :
+---+-----+----+--------+------+-------+------+
|tid|tname|tage| taddr|tclass|tcourse|tstore|
+---+-----+----+--------+------+-------+------+
| 1| sfl| 206| yingkou| 314| yuwen| 98|
| 2| wtt| 207| yingkou| 324| shuxue| 99|
| 3|sswen| 806| yingkou| 314| yuwen| 18|
| 4| sswu| 296| yingkou| 344| shuxue| 28|
| 5| sjw|2010| yingkou| 354| yuwen| 93|
| 6| sjy| 226| yingkou| 316| shuxue| 94|
| 7| ssx| 236| yingkou| 317| yuwen| 95|
| 8| wdd| 246|tongliao| 384| shuxue| 68|
| 9| stm| 256|tongliao| 394| yuwen| 97|
| 10| stx| 606|tongliao| 114| shuxue| 18|
| 11| szx| 706|tongliao| 124| yuwen| 92|
+---+-----+----+--------+------+-------+------+
代码 :
spark.sql("use default")
spark.sql("select * from student").show()
执行 :
spark-submit --master yarn --num-executors 5 --executor-cores 3 --executor-memory 6144m --deploy-mode client --class lifecycle05_SparkOnHive.SparkOnHive01 s3://lifecyclebigdata/dataWareHouse/BALABALA/00jar/03_hive/veryOK-1.0-SNAPSHOT.jar
14 ,导入数据后 :
- 原来的位置,数据没了
- 数据被剪切到了内部表的位置
15 ,如果再次导入数据 :
依然成功
数据增加
三 ,内部表 : parquet :
1 ,删表 :
drop table student;
2 ,删表的后果 :
数据全部没了
3 ,建表,分隔符,位置 :
use default;
create table student(tid int,tname string,tage int,taddr string,tclass string,tcourse string,tstore int) row format delimited fields terminated by ',' location 's3://lifecyclebigdata/dataWareHouse/BALABALA/06_hive_inner/student';
4,hive 仅支持单一存储方式 :
要么文本 ( txt,csv )
要么 parquet
不可以混合存储
5,csv 转换成 parquet ,snappy :
package lifecycle00_test
import lifecycle01_tool.{Tool}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
// 文件格式转换 :
// snappy,parquet
object Test01 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = Tool.getLocalSpark()
import spark.implicits._
import spark.sqlContext.implicits._
// 1 ,读文件 :
// 1,sfl,206,yingkou,314,yuwen,98
val rdd: RDD[Row] = spark.sparkContext.textFile("s3a://lifecyclebigdata/dataWareHouse/BALABALA/08_hive_data/test01")
.map(_.split(","))
.map(line => Row(line(0).toInt,line(1),line(2).toInt,line(3),line(4).toInt,line(5),line(6).toInt))
// 2 ,元数据
val structType = StructType(Array( StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true),
StructField("addr", StringType, true),
StructField("clazz", IntegerType, true),
StructField("course", StringType, true),
StructField("score", IntegerType, true)))
// 3 ,建表 :
val res: DataFrame = spark.createDataFrame(rdd, structType)
// 4 ,写出
res.write.option("compression","snappy").option("delimiter",",").parquet("s3a://lifecyclebigdata/dataWareHouse/BALABALA/08_hive_data/test02")
spark.close()
}
}
6 ,建表,存储格式 ( snappy,parquet )
create table student(id int,name string,age int,addr string,clazz int,course string,score int)
row format delimited fields terminated by ','
stored as parquet
location 's3://lifecyclebigdata/dataWareHouse/BALABALA/06_hive_inner/student'
TBLPROPERTIES ('parquet.compress'='SNAPPY');
7 ,导入数据 : snappy ,parquet
load data inpath "s3://lifecyclebigdata/dataWareHouse/BALABALA/08_hive_data/test02" into table student;
8 ,查看数据 : hive-cli
select * from student;
9 ,查看数据 :spark
spark.sql("select * from "+tableName).show()
10 ,执行 :
spark-submit --master yarn --num-executors 5 --executor-cores 3 --executor-memory 6144m --deploy-mode client --class lifecycle05_SparkOnHive.SparkOnHive02_show s3://lifecyclebigdata/dataWareHouse/BALABALA/00jar/03_hive/veryOK-1.0-SNAPSHOT.jar student
11 ,结果 :
+---+-----+----+--------+-----+------+-----+
| id| name| age| addr|clazz|course|score|
+---+-----+----+--------+-----+------+-----+
| 1| sfl| 206| yingkou| 314| yuwen| 98|
| 2| wtt| 207| yingkou| 324|shuxue| 99|
| 3|sswen| 806| yingkou| 314| yuwen| 18|
| 4| sswu| 296| yingkou| 344|shuxue| 28|
| 5| sjw|2010| yingkou| 354| yuwen| 93|
| 6| sjy| 226| yingkou| 316|shuxue| 94|
| 7| ssx| 236| yingkou| 317| yuwen| 95|
| 8| wdd| 246|tongliao| 384|shuxue| 68|
| 9| stm| 256|tongliao| 394| yuwen| 97|
| 10| stx| 606|tongliao| 114|shuxue| 18|
| 11| szx| 706|tongliao| 124| yuwen| 92|
+---+-----+----+--------+-----+------+-----+
四 ,复制数据会怎样 : 进入表中
1 , 把数据直接复制到制定目录会怎么样 : 同样使用
2 , 数据量增加。
3 , 跟导入数据是同样的原理。
五 ,结论 :
1 ,内部表本质 :
把数据映射到 S3 文件夹
2 ,数据直接复制到内部表文件夹 :
跟导入同样效果
3 ,删除内部表 :
会删除文件夹中数据














 2495
2495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









