








1.ollama简介
ollama通过融合开源社区的模块化设计理念(如Docker容器化部署)和商业公司的API标准化经验,实现了学术研究与工程实践的有效结合。其技术路线验证了低成本AI本地化部署的可行性,为后续大模型研究提供了可复用的方法论框架。
2.deepseek32b模型简介

参数量为320亿(32B),介于中小型模型(7B-14B)与超大规模模型(671B)之间,属于轻量化设计的“残血版”。
专注资源效率:相比满血版671B模型(需专业服务器和百万级硬件成本),32B版本可在消费级GPU(如RTX 3090 24G显存)上运行,显存占用约22-24GB。
推理速度提升40%,显存占用降低30%,支持量化技术(如Q4量化降低显存需求至12G左右)。动态批处理技术和FlashAttention优化加速计算,适合实时响应任务。
支持本地化部署,数据无需上传云端,满足金融、医疗等高隐私要求场景。开放微调接口,可针对企业知识库或特定任务进行定制化训练。
3.ollama部署deepseek32b
3.1.1.下载ollama
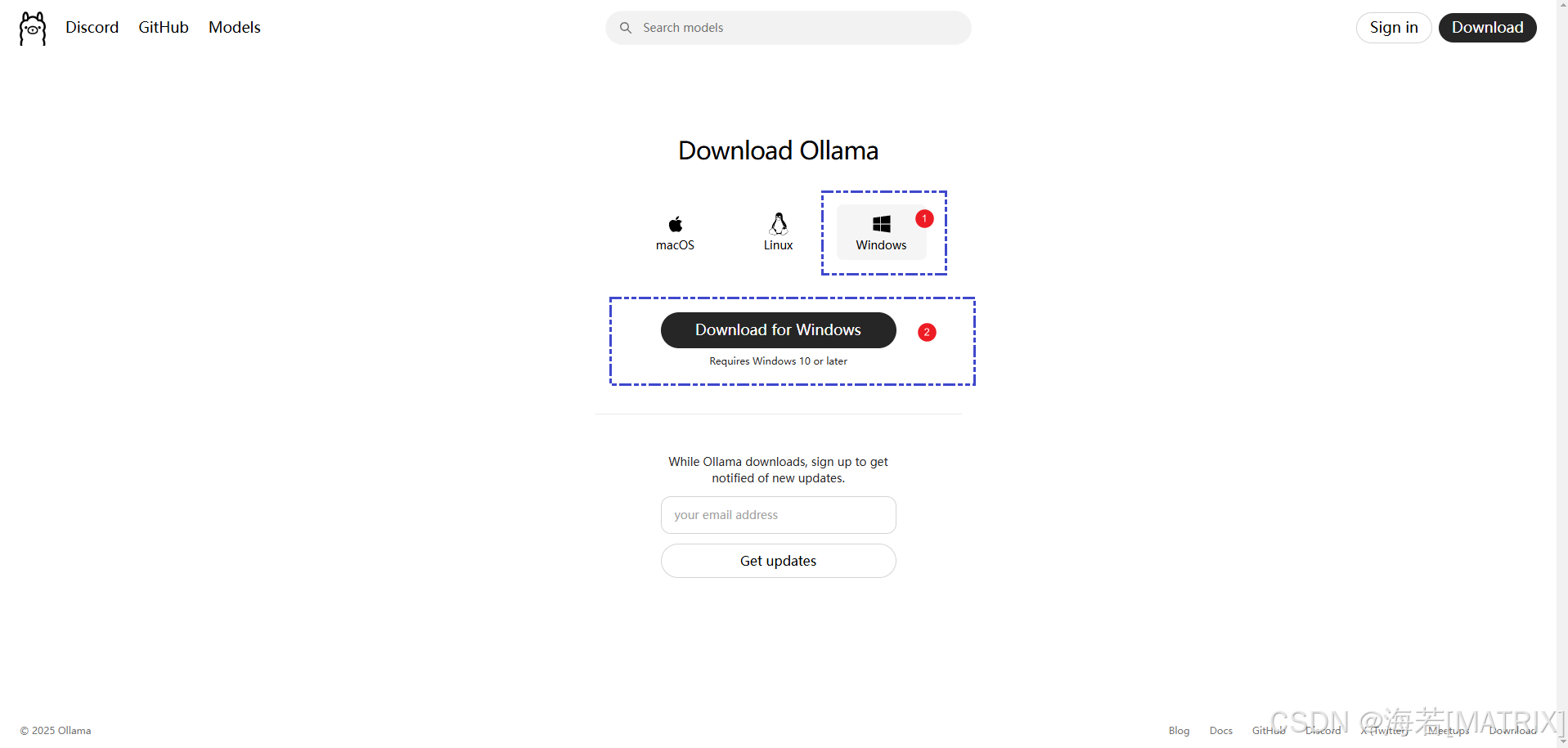
3.1.2.安装ollama

双击一路默认即可
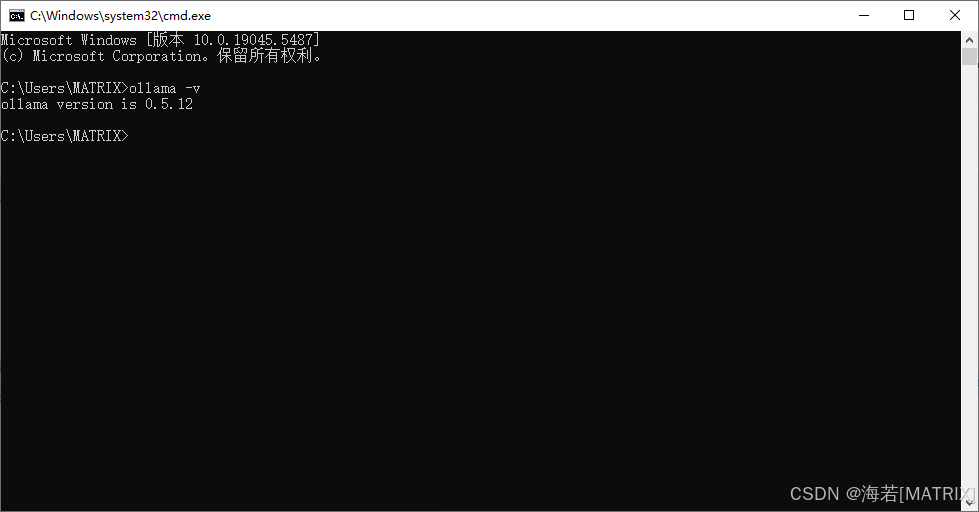
命令行校验,出现如下提示,说明已安装。
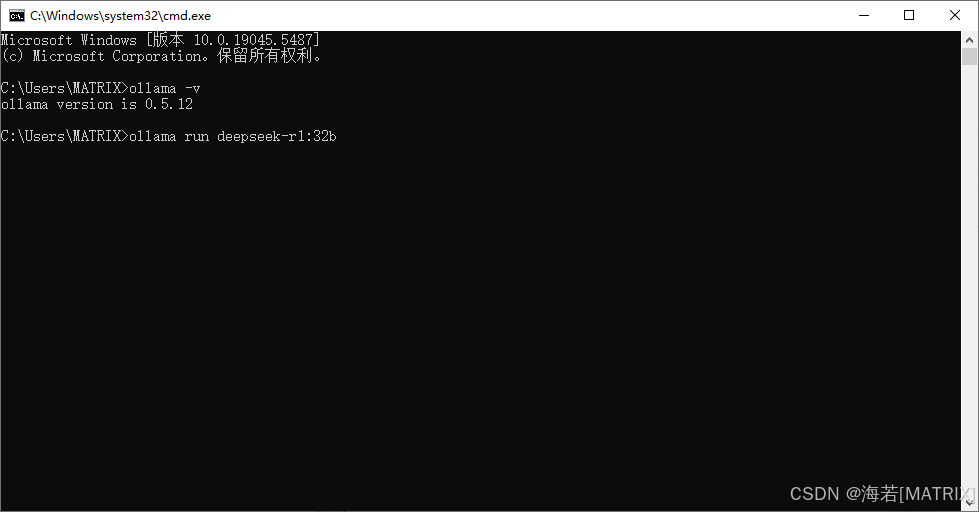
3.1.3.部署deepseek32b
cmd执行:
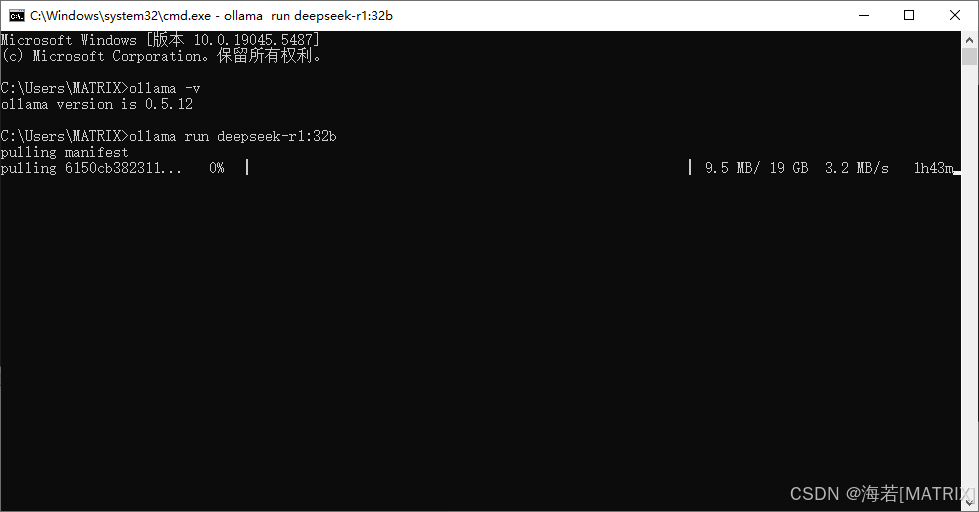
ollama run deepseek-r1:32b
等待安装完,即可对话
4.写在最后
推荐主机至少要有显卡,显卡最好gtx4060以上,如果要流畅运行deepseek32b,至少rtx4090。



















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











