






不多话,直接开干。
情景:需要在一台内网机器上部署deepseek-r1,用来支撑内部的智能化应用。内网机器不能联互联网,所有组件必须从外网下载,再转运到内网。内网机器为神州数码的坤泰主机,安装OpenEuler 20.03,内存128G,带4张华为NPU(i300-Duo)。
一、下载安装Ollama
根据Linux的版本下载对应版本的 Ollama
- 查看Linux CPU型号,使用下面的命令
#查看Linux版本号
cat /proc/version
#查看cpu架构
lscpu
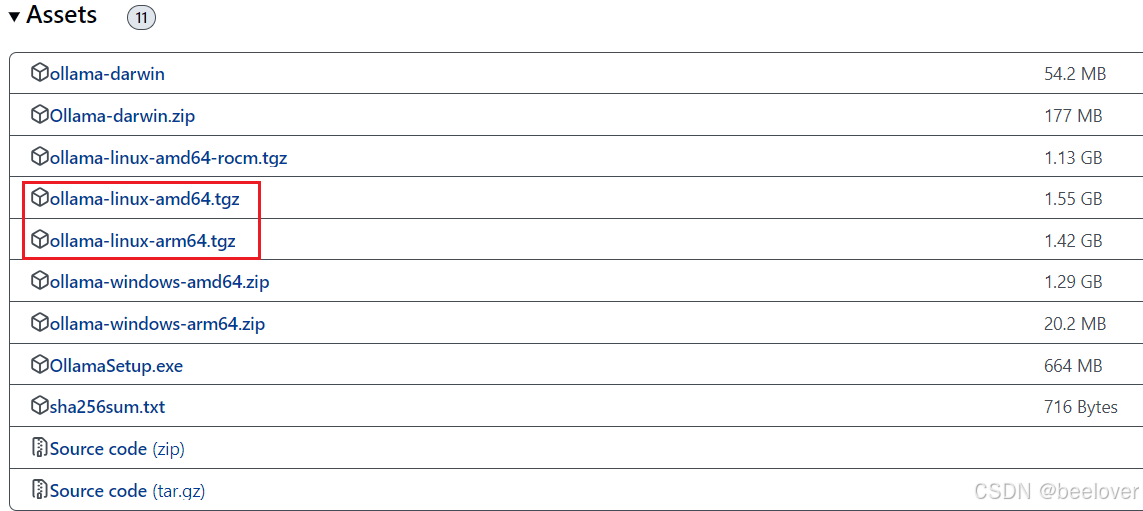
- x86_64 CPU选择下载ollama-linux-amd64;aarch64|arm64 CPU选择下载ollama-linux-arm64
我的机器是arm架构,所以下载了ollama-linux-arm64。
网址:Releases · ollama/ollama · GitHub,直接下载。文件较大,推荐使用迅雷等工具下载加速,本人下载用了12分钟。
二、安装并启动Ollama
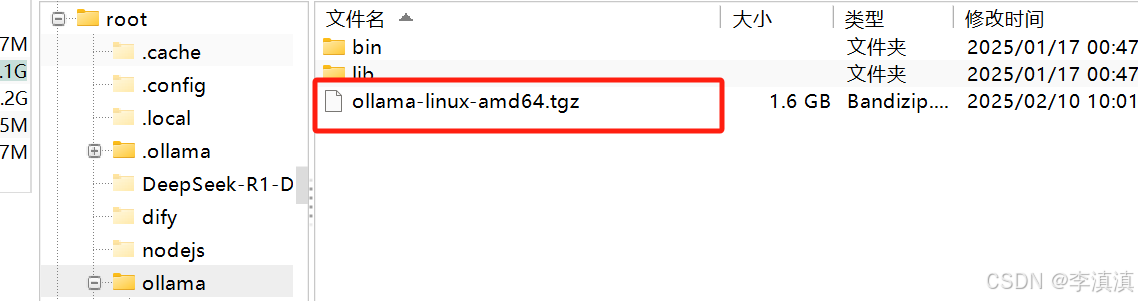
用光盘将下载的ollama-linux-arm64.tgz复制到内网机器。并在内网机器解压。
tar -xzf ollama-linux-amd64.tgz
- 1
- 2 启动 Ollama,使用下面的命令:
ollama serve
- 3 有坑:这时候,不出问题的话,Ollama会正常启动,但是这里往往会出现问题:/lib64/libstdc++.so.6: version `GLIBCXX_3.4.25‘ not found。
本人在这里就碰到了,一顿折腾。查找问题发现我安装的gcc-7.3,里面的动态库是GLIBCXX—3.1.17,所以必须更新gcc到gcc-9.2.0。
三、安装gcc-9.2.0
1.下载gcc-9.2.0
到 Index of /gnu/gcc 下载你要的gcc-9.2.0版本,我下载的是gcc-9.2.0.tar.gz
| https://ftp.gnu.org/gnu/gcc/gcc-9.2.0/gcc-9.2.0.tar.gz |
2.安装gcc所需组件。
因为是无网络状态,所以安装gcc的组件需要手动下载。
打开./contrib/download_prerequisites文件,发现里面有四个压缩包需要下载:具体是哪四个呢?

怎么下载呢?上这个网站下载。Index of /sites/sourceware.org/pub/gcc/infrastructure (mirrorservice.org)
WARNING:光把这四个安装包拷贝回去还不够,你还需要把他们解压并且改名。具体操作为:
tar -xzvf mpc-1.0.3.tar.gz
mv mpc-1.0.3 mpc
tar -jxvf gmp-6.1.0.tar.bz2
mv gmp-6.1.0 gmp
tar -jxvf mpfr-3.1.4.tar.bz2
mv mpfr-3.1.4 mpfr
tar -jxvf isl-0.18.tar.bz2
mv isl-0.18 isl
然后手动安装gmp、mpc、mpfr、isl这4个包,可以根据提示自己安装。
安装方法很简单,以mpc为例:
tar -jxvf mpc-1.0.3.tar.gz
mv mpc-1.0.3 mpc
cd mpc
./configure
make
sudo make install
最后一步,大家注意一下用sudo,有些系统你可能没有权限把包放到lib下面。按照上面的方法依次按照需要的包即可。
3.安装gcc
安装好组件后,就可能安装gcc-9.2.0了。
## 配置makefile, prefix=安装路径
mkdir build && cd build
../configure --prefix=/usr/gcc-9.2.0 --enable-language=c,c++,fortran --disable-multilib --enable-bootstrap --enable-checking=releasemake安装
# 这一步需要非常久的时间
make -j4
# 千万别忘了make install!!!!!!!!!!!!!!!!!
make install4.添加环境变量
它的作用是以后只需要source这个env_gcc-9.2.0的文件就可以使用gcc-9.2.0了。
vi env_gcc-9.2.0
# 下面的内容拷贝进env_gcc-9.2.0中
# 唯一需要修改的地方就是your_path要和第四步configure配置的一致。
GCCHOME=/usr/gcc-9.2.0
export PATH=$GCCHOME/bin:$PATH
export LD_LIBRARY_PATH=$GCCHOME/lib/gcc/x86_64-pc-linux-gnu/9.2.0/:$GCCHOME/lib64:$GCCHOME/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=$GCCHOME/lib:$LIBRARY_PATH
export C_INCLUDE_PATH=$GCCHOME/include:$C_INCLUDE_PATH
export CPLUS_INCLUDE_PATH=$GCCHOME/include/c++/9.2.0:$CPLUS_INCLUDE_PATH5.使用
source env_gcc-9.2.0
gcc --version四、运行Ollama
这时候,还有一步:关联库
默认情况下,这个库会安装到/usr/local/lib64下面,而且代码引用的时候,会自动找libstdc++.so.6,这个是一个软链接,知道我们安装的包上的。可以通过ls -l 查看。
-rw-r--r-- 1 root staff 45407954 Sep 23 21:57 libstdc++.a
-rw-r--r-- 1 root staff 12002194 Sep 23 21:57 libstdc++fs.a
-rwxr-xr-x 1 root staff 905 Sep 23 21:57 libstdc++fs.la
-rwxr-xr-x 1 root staff 965 Sep 23 21:57 libstdc++.la
lrwxrwxrwx 1 root staff 19 Sep 23 21:57 libstdc++.so -> libstdc++.so.6.0.27
lrwxrwxrwx 1 root staff 19 Sep 23 21:57 libstdc++.so.6 -> libstdc++.so.6.0.27
-rwxr-xr-x 1 root staff 17730016 Sep 23 21:57 libstdc++.so.6.0.27
你可以通过如下命令查看GLIBCXX的版本情况。
strings /usr/lib64/libstdc++.so.6 | grep GLIBC
如果你的最新的库没有被关联到libstdc++.so.6上,可以做一下软链接。
$ sudo rm -rf /usr/local/lib64/libstdc++.so.6
$ sudo ln -s /usr/local/lib64/libstdc++.so.6.0.27 /usr/local/lib64/libstdc++.so.6
这个时候你就可以正常使用最新版本的C++了,也就可以运行Ollama了。

















 4068
4068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









