







[(3, 1), (4, 2), (5, 3)]
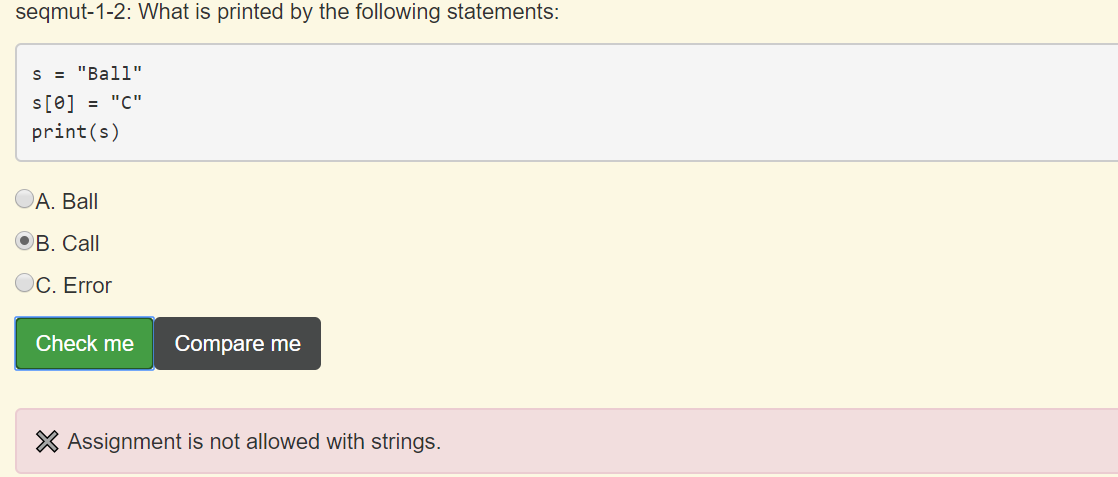
什么是嵌套数据结构 - a nested data structure
a nested data structure: dictionaries whose values are lists or other dictionaries. We call it a nested data structure.
文章目录
- 17.2 Nested Dictionaries 嵌套字典类型
- 17.3. Processing JSON results
- 17.4. [嵌套循环] Nested Iteration
- 17.5. 👩💻 Structuring Nested Data
- 17.6. [深、浅复制] Deep and Shallow Copies
- 17.7 👩💻 Extracting from Nested Data
- 23.1. Introduction: Map, Filter, List Comprehensions, and Zip
- 23.2. Map
- 23.3. Filter
- 23.4. 🔔List Comprehensions
- 23.5. Zip
17.2 Nested Dictionaries 嵌套字典类型
- 字典中的键key 必须是**不可变(immutable )**的数据类型(数字、字符串、元组)之一。
- 字典中的 值/value 可以是**任意(arbitrary)**类型的对象
正确答案 AC
17.3. Processing JSON results
Again, python provides a module for doing this. The module is called json. We will be using two functions in this module,
json.loads( )
json.loads()takes a string as input and produces a python object (a dictionary or a list) as output.
json.dumps( )
json.dumps( , sort_keys= , indent= )does the inverse ofloads. It takes a python object, typically a dictionary or a list, and returns a string, in JSON format.It has a few other parameters. Two useful parameters are sort_keys and indent.
When the value
Trueof is passed for thesort_keysparameter, the keys of dictionaries are output in alphabetic order with their values.The
indentparameter expects an integer. When it is provided, dumps generates a string suitable for displaying to people, with newlines and indentation for nested lists or dictionaries.
17.4. [嵌套循环] Nested Iteration
We’re going to call this the outer loop because it goes through the outer list. 外循环
nested1 = [['a', 'b', 'c'],['d', 'e'],['f', 'g', 'h']]
for x in nested1:
print("level1: ")
for y in x:
print(" level2: " + y)
【
break】if you remember the fancy break command that ends the inner iteration, the inner for loop. This will break us out of the innermost four loop that we’re in.
【print 区别】
print(" level2:"+y) print(" level2:",y) # 比使用+多一个空格在,的位置
17.5. 👩💻 Structuring Nested Data
当构建您自己的嵌套数据时,最好在每个级别保持结构一致。
例如,如果您有一个字典列表,那么每个字典应该具有相同的结构,这意味着所有字典中与特定关键字相关联的相同关键字和相同类型的值。这是因为所使用的结构中的任何偏差都需要额外的代码来处理这些特殊情况。结构偏离得越多,你就越需要使用特殊情况。
nested1 = [1, 2, ['a', 'b', 'c'],['d', 'e'],['f', 'g', 'h']]
for x in nested1:
print("level1: ")
for y in x:
print(" level2: {}".format(y))
在第一步的时候出错,因为整数类型不是可以迭代的数据类型
TypeError: 'int' object is not iterable on line 4
使用 if 语句进行判断
nested1 = [1, 2, ['a', 'b', 'c'],['d', 'e'],['f', 'g', 'h']]
for x in nested1:
print("level1: ")
if type(x) is list:
for y in x:
print(" level2: {}".format(y))
else:
print(x)
17.6. [深、浅复制] Deep and Shallow Copies
Shallow Copies
【可能会产生混淆的python结构 – 搞清楚】
在前面讨论 cloning and aliasing lists 时,我们曾提到过,简单地使用 [:] 克隆列表,最好注意到原始列表与赋值的列表之间 无意间相互连接的问题。
When you copy a nested list, you do not also get copies of the internal lists. This means that if you perform a mutation operation on one of the original sublists, the copied version will also change
复制嵌套列表时,您不会同时获得内部列表的副本。这意味着,如果您在一个原始子列表上执行一个变异操作,复制的版本也会改变。我们可以在下面的嵌套列表中看到这种情况,它只有两个级别。
original指向一个列表 高层/浅层
original[0]和original[1]指像内层深层列表
That’s shallow copies for you
original = [['dogs', 'puppies'], ['cats', "kittens"]]
# shallow copy
copied_version = original[:] # 浅层复制 只得到了 objects对应的列表,里面有两个元素
print(copied_version) # [['dogs', 'puppies'], ['cats', 'kittens']]
print(copied_version is original) # False
print(copied_version == original) # True
# mutation operation 对原始对象 【的 子元素】 变更, copy版本也会改变
original[0].append(["canines"])
print(original) # [['dogs', 'puppies', ['canines']], ['cats', 'kittens']]
print("-------- Now look at the copied version -----------")
print(copied_version) # [['dogs', 'puppies', ['canines']], ['cats', 'kittens']]
理解这句话:making shallow copies (copying a list at the highest level), you do not also get copies of the internal lists.
【误区】原来以为只要是 shallow copies 时候,改变了原对象,副本也一定会改变,实际上不是的,对于上面的例子来说:
- 若 original 改变后 变成 objects对应的列表变成三项四项,那么 copied_version 的输出不会改变
- 若 original 改变后 objects[0] 或者 object[1]改变了,即内存改变了, 那么 copied_version 的输出会跟着改变
这里第11行,就是第二种情况,改变了 internal lists. 由于我们没有真正 copy internal lists,我们得到的副本指向这两个list的内容,因此 copied_version 的输出读取这两个位置后会跟着改变:
original[0].append(["canines"])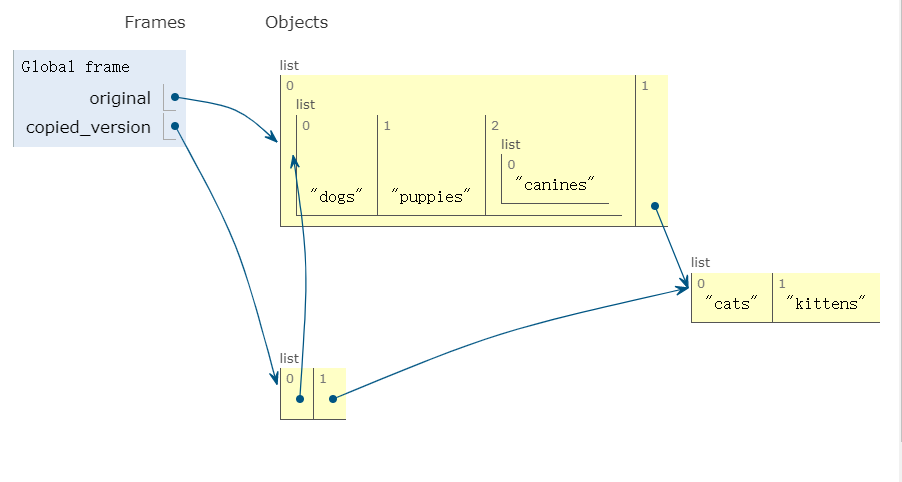
我们重新添加一行语句,我们真正在 highest level 浅层复制了一个副本,因此原列表浅层/最上层的变化,不会影响我们 copied_version 的输出值
original.append('highest level element')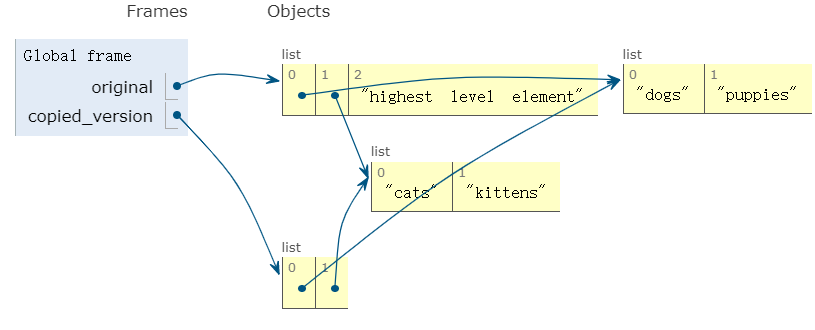
Deep Copies
如果你不想出现这种混淆的情况,你就要进行深层的复制,你需要执行 nested iteration 进入深层对每一个值复制一个副本
That’s what’s called a deep copy. We can do it with nested iteration, accumulating a copy of each inner list.
单更推荐使用 python 内置的 copy 模块执行 深层复制,特别是针对这种 数据,可以使得原本和副本完全解耦。
inside the copy module there is a deep copy function, and it just takes the sequence as its value.
original = [['canines', ['dogs', 'puppies']], ['felines', ['cats', 'kittens']]]
import copy
original = [['canines', ['dogs', 'puppies']], ['felines', ['cats', 'kittens']]]
# 浅层复制
shallow_copy_version = original[:]
# 深层复制
deeply_copied_version = copy.deepcopy(original)
# 浅层改变
original.append("Hi there")
# 深层改变
original[0].append(["marsupials"])
print("-------- Original -----------")
print(original)
print("-------- deep copy -----------")
print(deeply_copied_version)
print("-------- shallow copy -----------")
print(shallow_copy_version)
-------- Original -----------
[['canines', ['dogs', 'puppies'], ['marsupials']], ['felines', ['cats', 'kittens']], 'Hi there']
-------- deep copy -----------
[['canines', ['dogs', 'puppies']], ['felines', ['cats', 'kittens']]]
-------- shallow copy -----------
[['canines', ['dogs', 'puppies'], ['marsupials']], ['felines', ['cats', 'kittens']]]
17.7 👩💻 Extracting from Nested Data
总之,我的建议是,如果您需要从复杂的深度嵌套结构(a complicated deeply nested structure)中提取一些内容,那么一次开发一层代码。在每个步骤中,通过字典的键或第一项的打印表示中的前几个字符打印出您所拥有的内容。然后再提取一点。最后,您可以删除所有的打印语句,并将一些代码折叠成更复杂的表达式,从而得到像我们现在在屏幕上看到的那样紧凑的东西
一个普遍的问题,特别是在处理从网站返回的数据时,就是嵌套数据结构的内部深处提取某些元素。
最原则的方法就是:
- with lists, you use [] to index or a for loop to get them them all;
- with dictionaries, you get the value associated with a particular key using [] or iterate through all the keys, accessing the value for each.
但是,很容易在此过程中迷失方向,因此,我们创建了一种可用的技术来在调试过程中为您提供帮助
The process involves the following steps:
- Understand the nested data object.
- Extract one object at the next level down.
- Repeat the process with the extracted object
为了说明这一点,我们将逐步介绍从Twitter API返回的格式化数据中提取信息。【数据放另一个文件了】
17.7.1. Understand
在提取过程的首要任务是确保您了解所提取的当前对象,这里很少有选择:
-
打印整个对象。 如果尺寸足够小,也许可以直接理解打印输出。
如果稍大一点,您可能会发现“pretty-print”它会有所帮助,即缩进/indentation显示数据嵌套的级别。
我们无法在基于在线浏览器的环境中进行漂亮的打印,但是如果您使用完整的Python解释器运行代码,则可以使用 json 模块中的
dumps函数。 例如:import json print(json.dumps(res, indent=2)) -
如果打印整个对象使您感到有些笨拙/unwieldy,则可以使用其他选项来实现它。
-
使用在线工具解析:Copy and paste it to a site like https://jsoneditoronline.org/ which will let you explore and collapse levels
-
打印并先查看对象的类型:
-
如果是字典:打印键 If it’s a dictionary: print the keys
If it’s a list:
- 打印其长度 print its length
- 打印第一项的类型 print the type of the first item
- 如果尺寸可管理,则打印第一件 print the first item if it’s of manageable size
import json
# ①试着打印原信息的 前【100个】字符看看情况,注以 pretty
print(json.dumps(res, indent=2)[:100])
'''
{
"search_metadata":{
"count":3,
"completed_in":0.015,
"max_id_str":"536624519285583872",
"since_id_str":
'''
# ②打印数据类型
print("-----------")
print(type(res))
# ③如果是字典:打印键, 整个信息只有两个键
print(res.keys())
'''
<class 'dict'>
['search_metadata', 'statuses']'''
17.7.2. Extract
在提取阶段,您将深入 one level deeper into the nested data。
-
如果是字典,。 例如:res2 = res [‘statuses’]
print(type(res)) # 输出:<class 'dict'> print(res.keys()) # 输出:['search_metadata', 'statuses'] res2 = res['statuses'] # 请找出哪个键具有您要寻找的值,然后获取其值 -
如果是列表,那么您通常会希望对每个item都做一些事情(例如,从每个项目中提取一些内容并将其累积在列表中)。
为此,您需要一个for循环,例如
for res2 in res。但是,在探索阶段,如果只使用一项,则调试起来会更容易。
One trick for doing that is to iterate over a slice of the list containing just one item. For example:
for res2 in res[:1]
17.7.3. Repeat
现在,您将在下一级重复理解和提取过程。
https://fopp.umsi.education/books/published/fopp/NestedData/WPExtractFromNestedData.html
print(type(res))
print(res.keys())
res2 = res['statuses'] # 请找出哪个键具有您要寻找的值,然后获取其值
print("----Level 2-----") #
print(type(res2)) # 理解这一层对象的类型 it's a list!
print(len(res2)) # 理解 列表中有多少个元素: 3
这是一个包含三个项目的列表,因此很可能每个项目都代表一条推文。
现在再做Now extract, 由于是列表,因此我们希望处理每个项目,but to keep things manageable for now, let’s use the trick for just looking at the first item。 稍后,我们将切换到处理所有项目。
import json
print(type(res))
print(res.keys())
res2 = res['statuses']
print("----Level 2: a list of tweets-----")
print(type(res2)) # it's a list!
print(len(res2)) # looks like one item representing each of the three tweets
# 从这接续
for res3 in res2[:1]:
print("----Level 3: a tweet----") # 查看前30个字符 {"id":"536624519285583872","id
print(json.dumps(res3, indent=2)[:30]) # 发现列表里的元素是 字典 ---> keys
在深入一层,First understand.
import json
print(type(res))
print(res.keys())
res2 = res['statuses']
print("----Level 2: a list of tweets-----")
print(type(res2)) # it's a list!
print(len(res2)) # looks like one item representing each of the three tweets
for res3 in res2[:1]:
print("----Level 3: a tweet----")
print(json.dumps(res3, indent=2)[:30])
# 从这里接续
print(type(res3)) # it's a dictionary
print(res3.keys()) # 打印所有keys
['id', 'id_str', 'entities', 'lang', 'created_at', 'contributors', 'truncated', 'text', 'in_reply_to_status_id', 'favorite_count', 'source', 'retweeted', 'coordinates', 'in_reply_to_screen_name', 'in_reply_to_user_id', 'retweet_count', 'favorited', 'user', 'geo', 'in_reply_to_user_id_str', 'in_reply_to_status_id_str', 'place', 'metadata', 'retweeted_status']
然后提取第三层内容, 让我们提取有关谁发送了每个推文的信息。 可能是与 ‘user’ 键关联的值。
练习题
L = [[5, 8, 7], ['hello', 'hi', 'hola'], [6.6, 1.54, 3.99], ['small', 'large']]
# Test if 'hola' is in the list L. Save to variable name test1
test1 = 'hola' in L
# Pass False False Testing that test1 has the correct value.
理解错了 还以为 in 可以深入匹配
23.1. Introduction: Map, Filter, List Comprehensions, and Zip
我们已经在这个专业领域看到了很多叠加模式(the accumulation pattern) 。你有一个列表,你一个接一个地检查项目,更新一个累加器变量,在累加器变量的末尾作为你的结果。
我们首先复习一下 7.6. The Accumulator Pattern ,
The anatomy of the accumulation pattern includes:
- initializing an “accumulator” variable to an initial value (such as 0 if accumulating a sum)
- iterating (e.g., traversing the items in a sequence)
- updating the accumulator variable on each iteration (i.e., when processing each item in the sequence)
This pattern of iterating the updating of a variable is commonly referred to as the accumulator pattern. 这种迭代更新变量的模式通常被称为累加器。模式这种模式会反复出现。 请记住,使其成功运行的关键是确保在开始迭代之前初始化变量。
built-in 函数
range()的介绍:print("range(5): ") for i in range(5): print(i) print("range(0,5): ") for i in range(0, 5): print(i) # Notice the casting of `range` to the `list` # 关于python3中的range函数,如果我们想在迭代之外使用它,我们必须使用list()将它转换为一个列表。 # 实际上好像不用 ??? # range() 函数不包括结尾数字 print(list(range(5))) print(list(range(0,5)))range(5): 0 1 2 3 4 range(0,5): 0 1 2 3 4 [0, 1, 2, 3, 4] [0, 1, 2, 3, 4]# Write code to create a list of integers from 0 through 52 ou can do this in one line of code! numbs = list(range(53))
We have frequently taken a list and produced another list from it that contains either a subset of the items or a transformed version of each item. When each item is transformed we say that the operation is a mapping, or just a map of the original list. When some items are omitted, we call it a filter.
我们经常获取一个列表,并从中产生另一个列表,该列表包含原列表元素的子集或每个元素的转换版本。
当每个项目都被被转换时,我们说这种操作是原始列表的一个映射(map)。
当有一些项目被省略时,我们称这个操作为过滤(filter)。
封装了两种常用的 accumulation pattern 为函数函数
- One is a map operation. It transforms each item in the original, and accumulates the transformed item into a new list of the same length.
- The other is a filter operation. It selects a subset of the items from the original list.
Python 提供了内置的函数 map 和 filter。 Python还提供了一种称为列表集成( list comprehensions)的新语法,可让您表达映射和/或过滤操作。
就像命名函数和 lambda 表达式一样,一些学生似乎觉得
map和filter函数更容易,而其他学生则更容易阅读和编写 list comprehensions。大多数python程序员都使用列表推导 list comprehensions,因此请确保您学会了阅读这些。
23.2. Map
map 有两个参数,第一个参数是一个函数,第二个参数是一个序列数据类型。 函数是用于变换项序列中的元素的映射器。 它会自动应用于序列中的每个元素。
Note
Technically, in a proper Python 3 interpreter, the
mapfunction produces an “iterator”, which is like a list but produces the items as they are needed. Most places in Python where you can use a list (e.g., in a for loop) you can use an “iterator” as if it was actually a list. So you probably won’t ever notice the difference. If you ever really need a list, you can explicitly turn the output of map into a list:list(map(...)).
Now, map expects a transformer function, we can have a named function like triple(自定义), but we can also have a lambda expression just like we did when we were passing a function to the sorted function, and apply this transformer function to every single item in the sequence.
# 命名函数
def triple(value):
return 3*value
# 1. map 使用命名函数
def tripleStuff(a_list):
new_seq = map(triple, a_list)
return list(new_seq)
# 2. map使用lambda函数
def quadrupleStuff(a_list):
new_seq = map(lambda value: 4*value, a_list)
return list(new_seq)
things = [2, 5, 9]
things3 = tripleStuff(things)
print(things3)
things4 = quadrupleStuff(things)
print(things4)
# Using map, create a list assigned to the variable greeting_doubled that doubles each element in the list lst.
lst = [["hi", "bye"], "hello", "goodbye", [9, 2], 4]
greeting_doubled = map(lambda ele: 2*ele, lst)
---
[['hi', 'bye', 'hi', 'bye'], 'hellohello', 'goodbyegoodbye', [9, 2, 9, 2], 8]
# Use map to produce a new list called abbrevs_upper that contains all the same strings in upper case.
abbrevs = ["usa", "esp", "chn", "jpn", "mex", "can", "rus", "rsa", "jam"]
abbrevs_upper = map(lambda st: st.upper(), abbrevs)
---
['USA', 'ESP', 'CHN', 'JPN', 'MEX', 'CAN', 'RUS', 'RSA', 'JAM']
23.3. Filter
Now consider another common pattern: going through a list and keeping only those items that meet certain criteria. This is called a filter,filter a sequence. You start with some items and you end up with fewer of them
filter takes two arguments.
The first parameter that we pass in is that whole expression.
The second parameter that we’re passing in is the sequence.
here we’re not transforming the input. We’re just making a binary decision about it. 这里我们不转换输入。 我们只是对此做出二元决策
Is it true? Meaning keep it in: True - 保留它
or is it false? Meaning filter it out: False - 将其过滤掉
def keep_evens(nums):
new_seq = filter(lambda num: num % 2 == 0, nums)
return list(new_seq)
print(keep_evens([3, 4, 6, 7, 0, 1]))
---
[4, 6, 0]
# Write code to assign to the variable filter_testing all the elements in lst_check that have a w in them using filter.
lst_check = ['plums', 'watermelon', 'kiwi', 'strawberries', 'blueberries', 'peaches', 'apples', 'mangos', 'papaya']
filter_testing = filter(lambda word: 'w' in word, lst_check)
23.4. 🔔List Comprehensions
In Python, there’s actually a simpler syntax for doing the map and filter patterns and even for combining them. It’s called list comprehensions.
The general syntax is: 基本模板
[<transformer_expression> for <loop_var> in <sequence> if <filtration_expression>]
- 我们首先有方括号[]:我们使用方括号创建一个列表,但是我们放入其中的不是实际对象,而是一个Python 表达式,它将进行评估,它将产生列表的所有内容。
- 在 for 循环前面 是 the transformer expression,类似 map 函数
- then the word for, we’ll have some variable name, the word in
- 实现filter:have an “if” clause.
在一行代码中你就能看到 变量的 map(转换)表达,变量的 filter(筛选)表达以及我们对哪一个 sequence(序列)执行这些操作。
You can see where the transformer expression is,
you can see where the filtration expression is,
and you can easily see which sequence it is that we’re doing these operations on.
与常规for循环的另一个区别是,每次对表达式求值时,结果值都会附加到列表中。这是自动发生的,无需程序员明确初始化一个空列表或附加每个项目。
# For example, the following list comprehension will keep only the even numbers from the original list.
def keep_evens(nums):
new_list = [num for num in nums if num % 2 == 0]
return new_list
print(keep_evens([3, 4, 6, 7, 0, 1]))
注意
<transformer_expression>这一句,不对它进行转换:we don’t want to transform the number. We just want the number as it was, so we say “num” rather than “num” star two or some other transformation.
将 map 与 filter 联合使用的两种方法:
things = [3, 4, 6, 7, 0, 1]
# chaining together filter and map:
# 1. first, filter to keep only the even numbers 肯定先进行filter 再把结果 map
# double each of them
print(map(lambda x: x*2, filter(lambda y: y % 2 == 0, things)))
# 2. list comprehension version
print([x*2 for x in things if x % 2 == 0])
【这个例子关注对于嵌套数据结构 - 使用3步法逐层解析,更容易】
tester = {'info': [{"name": "Lauren", 'class standing': 'Junior', 'major': "Information Science"},{'name': 'Ayo', 'class standing': "Bachelor's", 'major': 'Information Science'}, {'name': 'Kathryn', 'class standing': 'Senior', 'major': 'Sociology'}, {'name': 'Nick', 'class standing': 'Junior', 'major': 'Computer Science'}, {'name': 'Gladys', 'class standing': 'Sophomore', 'major': 'History'}, {'name': 'Adam', 'major': 'Violin Performance', 'class standing': 'Senior'}]}
# 1.理解
inner_list = tester['info']
#print(inner_list)
import json
print(json.dumps(inner_list, indent=2))
#compri = [<transfors_experssion> for dict in tester['info'] if <filteration_experession>]
# 【完成】
tester = {'info': [{"name": "Lauren", 'class standing': 'Junior', 'major': "Information Science"},{'name': 'Ayo', 'class standing': "Bachelor's", 'major': 'Information Science'}, {'name': 'Kathryn', 'class standing': 'Senior', 'major': 'Sociology'}, {'name': 'Nick', 'class standing': 'Junior', 'major': 'Computer Science'}, {'name': 'Gladys', 'class standing': 'Sophomore', 'major': 'History'}, {'name': 'Adam', 'major': 'Violin Performance', 'class standing': 'Senior'}]}
# 1.理解
inner_list = tester['info']
#print(inner_list)
# 1. 确定我们循环的 seq对象是谁;2. 确定我们对lst中元素的trans_operation是什么;返还每个元素操作后组成的列表:map操作
compri = [dict['name'] for dict in tester['info'] if True]
第11题没说输入是list啊 如果输入是直接一个string的话 能输出正确的结果吗
23.5. Zip
除累积之外,列表的另一种常见模式是逐步浏览两个列表(或几个列表),对所有的对应位置的元素进行操作(加减乘除等 transformation)它使您进行成对比较或成对组合的操作变得容易。It’s called zip
The zipfunction takes two or more sequences and it makes a list of tuples. Each tuple gathers together the items from the corresponding position in the list.
后续的操作是 使用 x1,x2=(tuples) 这个称为 tuple的unpacking,然后 做operation
例如,给定两个数字列表,您可能希望将它们成对相加,取[3,4,5]和[1,2,3]得出[4,6,8]。
【方式一】我们可以使用 for循环:
L1 = [3, 4, 5]
L2 = [1, 2, 3]
L3 = []
for i in range(len(L1)):
L3.append(L1[i] + L2[i])
print(L3)
【方式二】zip函数输入多个列表,并将它们变成一个元组列表,将所有第一项都作为一个元组,所有第二项都作为一个元组,并且 以此类推。 然后,我们可以遍历这些元组,并对所有第一项,所有第二项等等执行一些操作。
L1 = [3, 4, 5]
L2 = [1, 2, 3]
L4 = list(zip(L1, L2))
print(L4)
---
[(3, 1), (4, 2), (5, 3)]
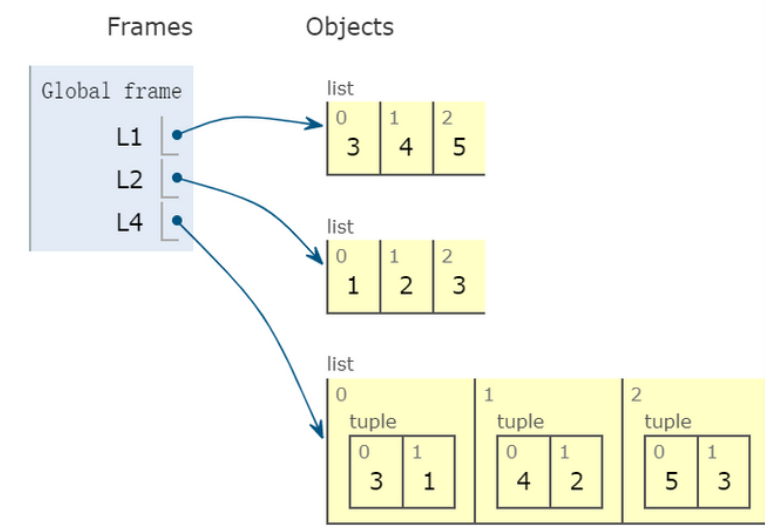
【这些函数实际上返回的是一个 iterator,类似列表如果我们想要一个真正的列表 需要在外边给出 list()】
当您遍历元组L4时,会发生以下情况。【关键是使用元组对变量对应赋值】
L1 = [3, 4, 5]
L2 = [1, 2, 3]
L3 = []
L4 = list(zip(L1, L2))
# 使用元组对变量对应赋值
for (x1, x2) in L4:
L3.append(x1+x2)
print(L3)
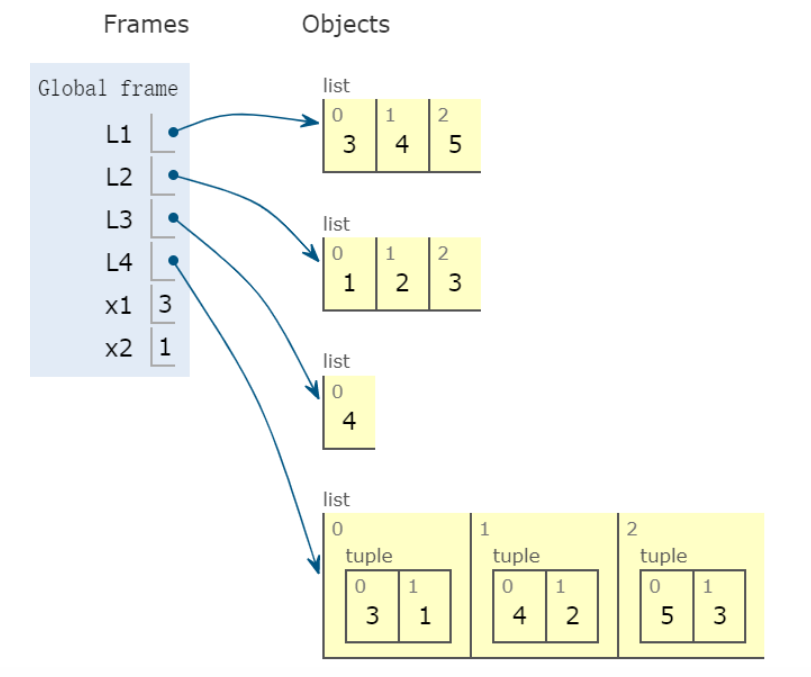
或者,简化和使用 list comprehension:
L1 = [3, 4, 5]
L2 = [1, 2, 3]
L3 = [x1 + x2 for (x1, x2) in list(zip(L1, L2))]
print(L3)
我们将两个列表 zip 在一起,然后使用 list comprehension 来遍历该zip list(一个元组列表)。 对于每个元组,我们通过将两个元素加在一起来转换元组(转换成一个整数),然后将这些和集累积到最终列表中
【方式3】Or, using map and not unpacking the tuple (是指 把元组里的值分别赋值给 (x1, x2))
L1 = [3, 4, 5]
L2 = [1, 2, 3]
L3 = map(lambda x: x[0] + x[1], zip(L1, L2))
print(L3)
a game of hangman
Consider a function called possible, which determines whether a word is still possible to play in a game of hangman, given/已知 the guesses that have been made and the current state of the blanked word.
设计一个名为 possible的函数,实现决定一个 word 是否仍有可能玩游戏,已知 已经做过的猜测以及当前 空白单词的状态。
# a function called possible that take three inputs:word-准确单词;blanked-当前单词状态含空白;guesses_made-已经猜过的字母
def possible(word, blanked, guesses_made):
# 1.判断猜的单词和正确单词的长度是否一致,不一致说明存在问题,肯定不可能得到正确的答案。
if len(word) != len(blanked):
return False
# 2. 遍历单词的每个字母,word和blanked 意义对应
for i in range(len(word)):
blc = blanked[i]
woc = word[i]
# 空位-对应的正确的字母如果已经属于猜过的字母 --> False
if blc == '_' and woc in guesses_made:
return False
# 非空位-字母不等于正确的字母 --> False
elif blc != '_' and blc != woc:
return False
# 除此以外 单词仍有可能被猜出来 -->True
return True
# 实验
print(possible('wonderwall', '_on_r_ll', 'otnqurl')
print(possible("wonderwall", "_on__r__ll", "wotnqurl"))
【生么样的情况下返回 False?】
- 可以排除 wonderwall 这个词,如果它有一个字母已经被猜测,但还没有被揭示,就像w。因为w已经被猜测了(属于gusses_made),但这里还没有被显示(在blanked中),那么wonderwall是不可能被正确猜出,返回 False。
- 我们还检查当
blanked不是下划线时,被显示出来的字母是否和 正确单词对应的字母一致
当遍历完所有位置时,since we didn’t find it in compatibility anywhere, we’re okay, and we can now return true
【这种一一对应的问题可以改写zip语句,第7,8,9行】
# a function called possible that take three inputs:word-准确单词;blanked-当前单词状态含空白;guesses_made-已经猜过的字母
def possible(word, blanked, guesses_made):
# 1.判断猜的单词和正确单词的长度是否一致,不一致说明存在问题,肯定不可能得到正确的答案。
if len(word) != len(blanked):
return False
# 2. 遍历单词的每个字母,word和blanked 意义对应
for (blc,woc) in zip(blanked, word):
# 空位-对应的正确的字母如果已经属于猜过的字母 --> False
if blc == '_' and woc in guesses_made:
return False
# 非空位-字母不等于正确的字母 --> False
elif blc != '_' and blc != woc:
return False
# 除此以外 单词仍有可能被猜出来 -->True
return True
# 实验
print(possible('wonderwall', '_on_r_ll', 'otnqurl')
print(possible("wonderwall", "_on__r__ll", "wotnqurl"))
【习题 - 三合一】
# Below we have provided two lists of numbers, L1 and L2. Using zip and list comprehension, create a new list, L3, that sums the two numbers if the number from L1 is greater than 10 and the number from L2 is less than 5. This can be accomplished in one line of code.
L1 = [1, 5, 2, 16, 32, 3, 54, 8, 100]
L2 = [1, 3, 10, 2, 42, 2, 3, 4, 3]
# L3 = [<trans_expression> for <loop_var> in ls if <filtration_expression>]
L3 = [n1+n2 for (n1,n2) in list(zip(L1,L2)) if n1>10 and n2<5]
That was the zip function. You can use it whenever you want to do pairwise operations. For example, if you wanted to take three lists of words and generate a single list that had the longest of the three words in each position, you could first zip all three lists together to generate a list of tuples, then you could write a list comprehension to do a mapping operation, transforming each tuple of three words into a single string, the longest of the three words















 1656
1656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









