







前言
Abstract
- 目的:提高bert速度,且尽可能减少性能损失
- 该模型在微调时采用了独特的自蒸馏机制(self-distillation ),从而进一步提高了计算效率,而性能损失却最小。
1、Introduction
- 提出了一种实用的速度可调BERT模型,即FastBERT,也就是速度可以自己调节,速度越快,效果越差。
- 结合样本自适应机制和自蒸馏机制,首次改善了NLP模型的推理时间。在十二个NLP数据集上验证了它的效果。
2、Related word
经典知识蒸馏方式:

下面的是我鬼扯的,可以直接跳过这部分。
一般情况这里的 L o s s ( P t , P s ) Loss(P_t, P_s) Loss(Pt,Ps) 是经过平滑处理后的交叉熵。另外在计算损失函数的时候,也有将真实标签用上的,也就是 L = L o s s ( P t , P s ) + L o s s ( Y , P s ) L= Loss(P_t, P_s) + Loss(Y, P_s) L=Loss(Pt,Ps)+Loss(Y,Ps)其中,Y为真实标签,再后来,一般通用的是上面公式前面的部分经过平滑,公式的后半部分的是正常的 softmax,这里就不展开讲了。
平滑处理一般是下面这个公式,也就是说当softmax输出的负标签的概率很小的时候,其对损失函数的贡献非常小,所以才有下面的操作,也就是将负标签的信息放大些,通常,在训练过程中student和teacher使用相同的T,在inference的时候,设置T为1:
q
i
=
e
z
i
/
T
∑
i
e
z
j
/
T
q_i = \frac{e^{z_i/T}}{\sum_i{e^{z_j/T}}}
qi=∑iezj/Tezi/T
比较经典的知识蒸馏就是下面这种方式:
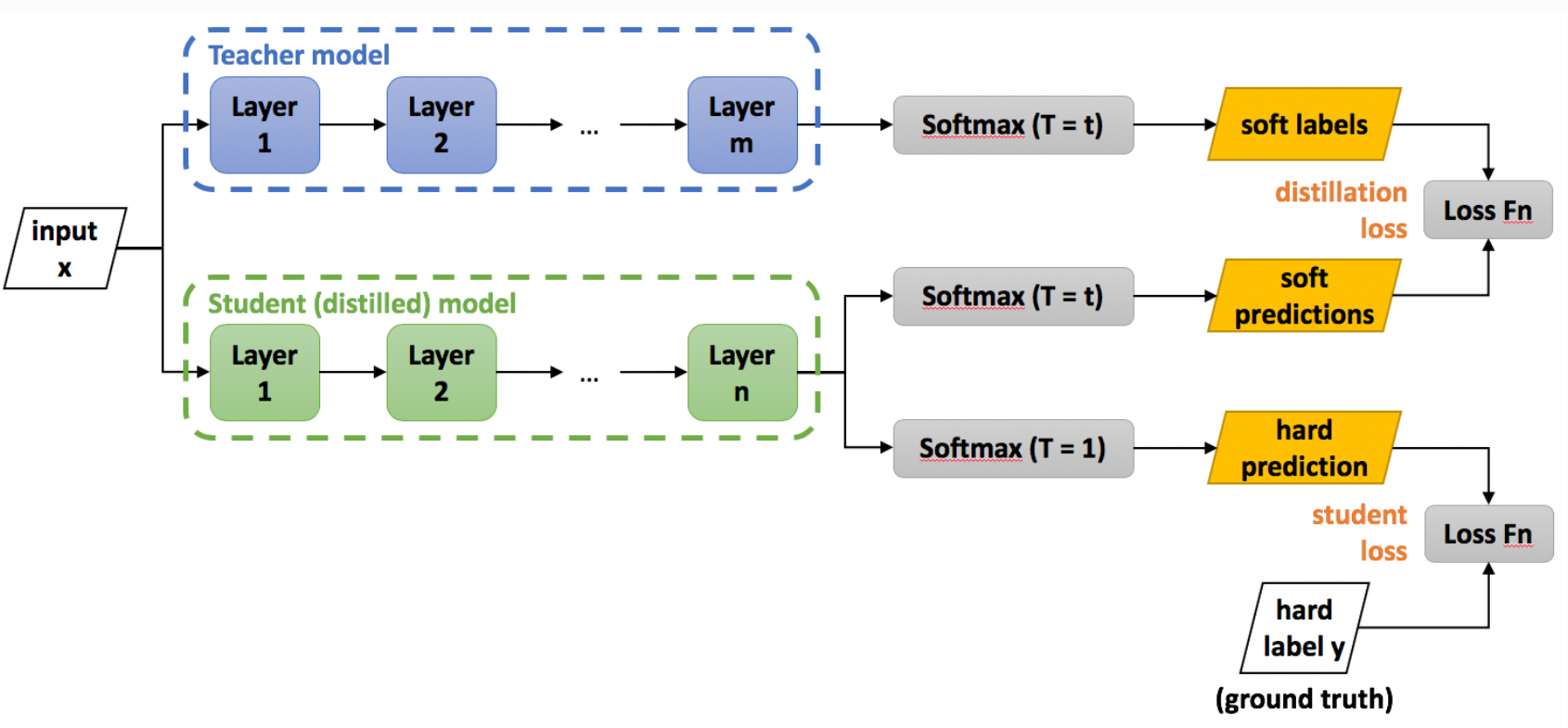
使用知识蒸馏之所以可能会有效果,是因为利用了softmax层输出的所有信息,也就是不止是让那个为真的概率最大(个人理解,有误请指出)。
3、Methodology
总体模型图如下:
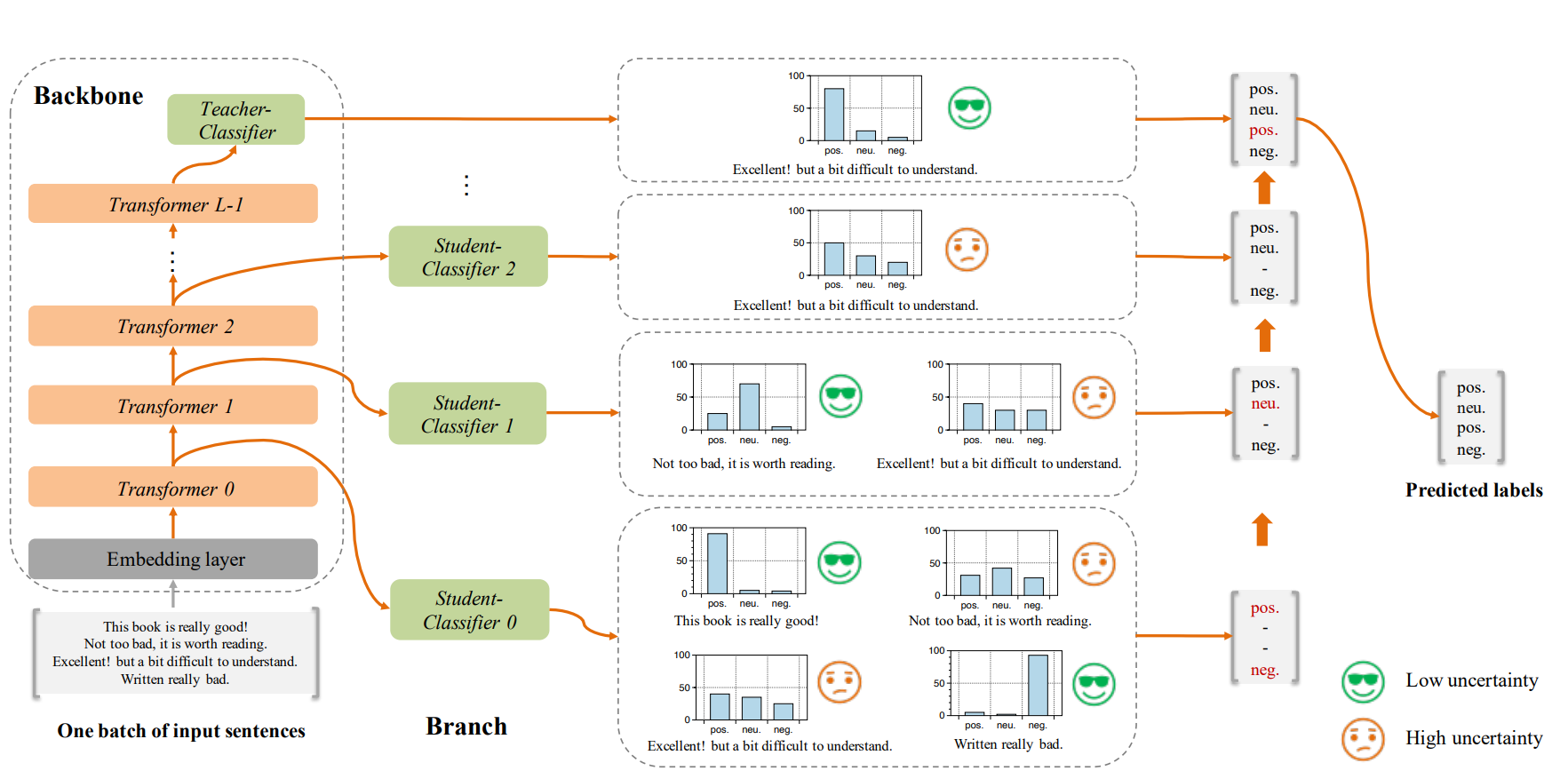
上面是举的例子,每一个 Student-Classifier 都来进行一次分类,确定性高的就直接分类了,确定性不高的就继续往后走。
总体过程:
- 1、初始训练,即训练好teacher分类器,这个就跟Bert一样。
- 2、蒸馏训练,即freeze主干网络和最后层的teacher分类器,每层的子模型拟合teacher分类器,损失函数为KL散度,具体后面会写。
- 2、inference阶段,根据样本输入,子分类器置信度高则提前返回。
网络结构和基本步骤都确定了,现在就来看它的蒸馏阶段的训练,也就是计算学生分类器和老师分类器的输出的KL散度:
D
K
L
(
p
s
,
p
t
)
D_{KL}(p_s, p_t)
DKL(ps,pt)
公式不展开写,其中
p
s
p_s
ps 为老师分类器的输出概率,
p
t
p_t
pt 为学生分类器的输出概率。 很显然,这部分训练使用无标注的数据就可以了。
最后就是训练好的模型怎么用它了,这时候,就需要有一个衡量的标准,来衡量学生分类器的的不确定性,这里用归一化熵:

熵越大则不确定性越大,通过调节这个阈值,就能改变速度。
4、Experimental results
实验部分不太想看,过。
5、个人总结
- 对速度提升显著。
- 只能用于分类任务。















 2573
2573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









