







文章目录
1. 概念
在数学中,连续型随机变量的概率密度函数(在不至于混淆时可以简称为密度函数)是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。而随机变量的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分。当概率密度函数存在的时候,累积分布函数是概率密度函数的积分。概率密度函数一般以小写标记。
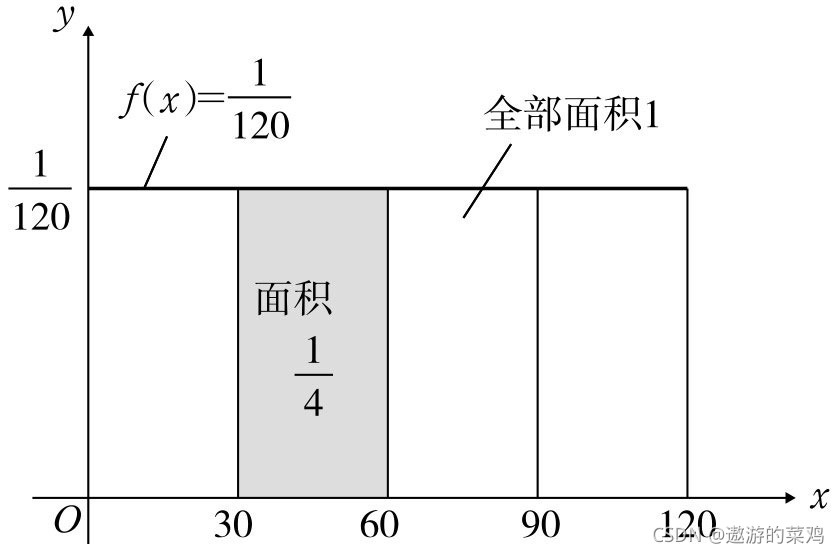
例子:外卖在两个小时内送达,送达时间的概率图表示如下,阴影部分为第30~60分钟内送达的概率,对30 ~ 60区域求积分:
根据概率密度函数提供的概率分布信息来生成随机变量的一个取值,这就是采样。 平时我们接触比较多的场景是,给定一堆样本数据,求出这堆样本的概率分布p(x)。而采样刚好是个逆命题:给定一个概率分布p(x),如何生成满足条件的样本?
2.采样
2.1 均匀分布采样
均匀分布式是一种最简单的分布。在计算机中生成[0,1]之间的伪随机数序列,就可以看做是一种均匀分布。
2.2 离散分布
离散分布是比均匀分布稍微复杂一点的情况。例如令p(x)=[0.1,0.2,0.3,0.4],那么我们可以把概率分布的向量看做一个区间段,然后从
x
∼
U
(
0
,
1
)
x ∼ U_{(0,1)}
x∼U(0,1)
分布中采样,判断x落在哪个区间内。区间长度与概率成正比,这样当采样的次数越多,采样就越符合原来的分布。
举个例子,假设p ( x ) = [ 0.1 , 0.2 , 0.3 , 0.4 ],分别为"hello", “java”, “python”, "scala"四个词出现的概率。我们按照上面的算法实现看看最终的结果:
import numpy as np
from collections import defaultdict
dic = defaultdict(int)
def sample():
u = np.random.rand()
if u <= 0.1:
dic["hello"] += 1
elif u <= 0.3:
dic["java"] += 1
elif u <= 0.6:
dic["python"] += 1
else:
dic["scala"] += 1
def sampleNtimes():
for i in range(10000):
sample()
for k,v in dic.items():
print k,v
sampleNtimes()
结果:
python 3028
java 2006
hello 971
scala 3995
2.3 接受拒绝采样(Acceptance-Rejection sampling)
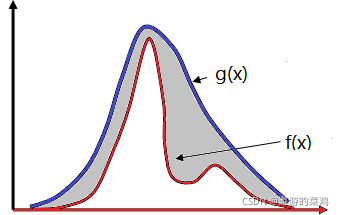
又简称拒绝抽样,直观地理解,为了得到一个分布的样本,我们通过某种机制得到了很多的初步样本,然后其中一部分初步样本会被作为有效的样本(即要抽取的分布f(x)的样本),一部分初步样本会被认为是无效样本舍弃掉。这个算法的基本思想是:我们需要对一个分布f(x)进行采样,但是却很难直接进行采样,所以我们想通过另外一个容易采样的分布g(x)的样本,用某种机制去除掉一些样本,从而使得剩下的样本就是来自与所求分布f(x)的样本。总结:假设我们已经可以抽样高斯分布g(x),我们按照一定的方法拒绝某些样本,达到接近f(x)分布的目的。
它有几个条件:1)对于任何一个x,有 f ( x ) < = M ∗ g ( x ) f(x)<=M*g(x) f(x)<=M∗g(x); 2) g(x)容易采样;3) g(x)最好在形状上比较接近f(x)。具体的采样过程如下:
-
对于g(x)进行采样得到一个样本xi, xi ~ g(x);
-
对于均匀分布采样 ui ~ U(a,b);
-
如果 u i < = f ( x ) / [ M ∗ g ( x ) ] u_i<= f(x)/[M*g(x)] ui<=f(x)/[M∗g(x)], 那么认为xi是有效的样本;否则舍弃该样本; (# 这个步骤充分体现了这个方法的名字:接受-拒绝)
-
反复重复步骤1~3,直到所需样本达到要求为止。
这个方法可以如图所示:
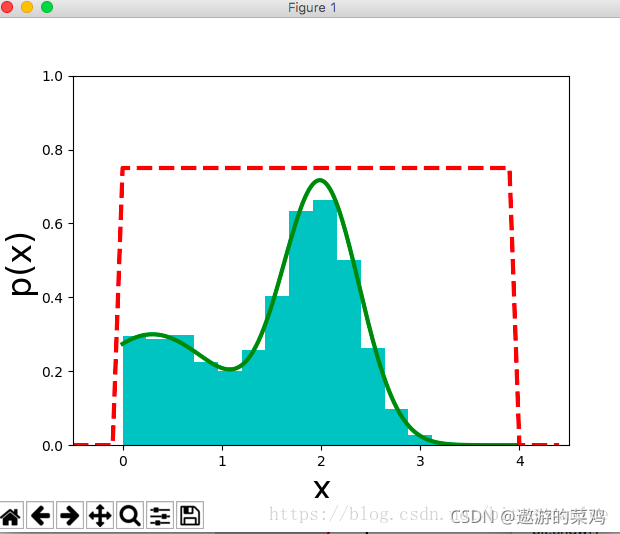
代码思路:
1.首先,确定常量M,使得f(x)总在Mg(x)的下方。
2.x轴的方向:从g(x)分布抽样取得a。但是a不一定留下,会有一定的几率被拒绝。
3.y轴的方向:从均匀分布(0, Mg(a))中抽样得到u。如果u>f(a),也就是落到了灰色的区域中,拒绝,否则接受这次抽样。
import numpy as np
import matplotlib.pyplot as plt
def qsample():
"""使用均匀分布作为q(x),返回采样"""
return np.random.rand() * 4.
def p(x):
"""目标分布"""
return 0.3 * np.exp(-(x - 0.3) ** 2) + 0.7 * np.exp(-(x - 2.) ** 2 / 0.3)
def rejection(nsamples):
M = 0.72 # 0.8 k值
samples = np.zeros(nsamples, dtype=float)
count = 0
for i in range(nsamples):
accept = False
while not accept:
x = qsample()
u = np.random.rand() * M
if u < p(x):
accept = True
samples[i] = x
else:
count += 1
print "reject count: ", count
return samples
x = np.arange(0, 4, 0.01)
x2 = np.arange(-0.5, 4.5, 0.1)
realdata = 0.3 * np.exp(-(x - 0.3) ** 2) + 0.7 * np.exp(-(x - 2.) ** 2 / 0.3)
box = np.ones(len(x2)) * 0.75 # 0.8
box[:5] = 0
box[-5:] = 0
plt.plot(x, realdata, 'g', lw=3)
plt.plot(x2, box, 'r--', lw=3)
import time
t0 = time.time()
samples = rejection(10000)
t1 = time.time()
print "Time ", t1 - t0
plt.hist(samples, 15, normed=1, fc='c')
plt.xlabel('x', fontsize=24)
plt.ylabel('p(x)', fontsize=24)
plt.axis([-0.5, 4.5, 0, 1])
plt.show()
在高维的情况下,Rejection Sampling有两个问题,导致拒绝率很高:
1.合适的q分布很难找
2.很难确定一个合理的k值
2.4 重要性抽样(Importance sampling)
https://zhuanlan.zhihu.com/p/41217212
https://blog.csdn.net/lmm6895071/article/details/78713304?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-4.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-4.no_search_link
2.5 MCMC(Markov Chain Monte Carlo)采样
https://blog.csdn.net/bitcarmanlee/article/details/82795137
2.6 吉布斯采样(Gibbs)
https://blog.csdn.net/bitcarmanlee/article/details/82795137
3.参考
概率密度函数:
https://www.zhihu.com/question/263467674
https://baike.baidu.com/item/%E6%A6%82%E7%8E%87%E5%AF%86%E5%BA%A6%E5%87%BD%E6%95%B0/5021996?fr=aladdin
均匀、离散、接受-拒绝采样:
https://blog.csdn.net/bitcarmanlee/article/details/82795137
接受-拒绝、重要性采样:
https://blog.csdn.net/u010159842/article/details/48636823/














 6820
6820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









