







CS 224n Assignment #2: word2vec (written部分)
understanding word2vec
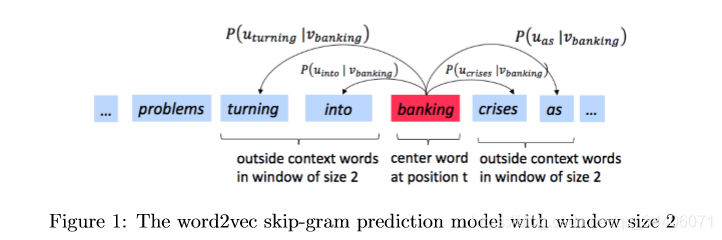
==The key insight behind word2vec is that ‘a word is known by the company it keeps’. == Concretely, suppose we have a ‘center’ word c and a contextual window surrounding c. We shall refer to words that lie in this contextual window as ‘outside words’. For example, in Figure 1 we see that the center word c is ‘banking’. Since the context window size is 2, the outside words are ‘turning’, ‘into’, ‘crises’, and ‘as’.
The goal of the skip-gram word2vec algorithm is to accurately learn the probability distribution P ( O ∣ C ) P(O|C) P(O∣C). Given a specific word o and a specific word c, we want to calculate P ( O = o ∣ C = c ) P(O = o|C = c) P(O=o∣C=c), which is the probability that word o is an ‘outside’ word for c, i.e., the probability that o falls within the contextual window of c.
In word2vec, the conditional probability distribution is given by taking vector dot-products and applying the softmax function:
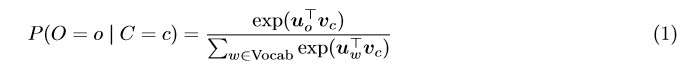
Here, u o u _o uo is the ‘outside’ vector representing outside word o, and v_c is the ‘center’ vector representing center word c. To contain these parameters, we have two matrices, U U U and V V V . The columns of U U U are all the ‘outside’ vectors u w u_w uw. The columns of V V V are all of the ‘center’ vectors v w v_w vw. Both U U U and
V V V contain a vector for every w ∈ V o c a b u l a r y . 1 w ∈ Vocabulary.^1 w∈Vocabulary.1
Recall from lectures that, for a single pair of words c and o, the loss is given by:
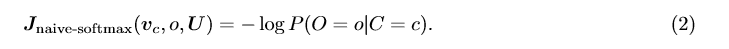
Another way to view this loss is as the c r o s s − e n t r o p y 2 cross-entropy^2 cross−entropy2 between the true distribution y and the predicted distribution y ˆ yˆ yˆ. Here, both y and y ˆ yˆ yˆ are vectors with length equal to the number of words in the vocabulary. Furthermore, the k t h k^{th} kth entry in these vectors indicates the conditional probability of the k t h k^{th} kth word being an ‘outside word’ for the given c. The true empirical distribution y is a one-hot vector with a 1 for the true outside word o, and 0 everywhere else. The predicted distribution y ˆ yˆ yˆ is the probability distribution P ( O ∣ C = c ) P(O|C = c) P(O∣C=c) given by our model in equation (1).
1 ^1 1Assume that every word in our vocabulary is matched to an integer number k. u k u_k uk is both the k t h k^th kth column of U and the ‘outside’ word vector for the word indexed by k. v k v_k vk is both the k t h k^th kth column of V and the ‘center’ word vector for the word indexed by k. In order to simplify notation we shall interchangeably use k to refer to the word and the index-of-the-word.
2 ^2 2The Cross Entropy Loss between the true (discrete) probability distribution p and another distribution q is − ∑ i p i l o g ( q i ) -\sum_{i}p_ilog(q_i) −∑ip
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









