









最外层的花括号表示dataset是一个字典
这个字典有两个字段
类似于下面这个例子
person = {
"name": "John Doe",
"age": 35
}'split' 字段可以当做是name字段,也就是键
而'split' 字段对应的值又是一个字典,又是一个花括号。这个字典又分了键和值
'xsub_train'是键,对应的值是一个列表
'xsub_val'是键,对应的值是一个列表
注意:
- 值可以是任意的 Python 对象,如数字、字符串、列表、元组、字典等
'annotations'字段可以当做是age字段,也就是键
而'annotations' 字段对应的值是一个列表,而列表的每个元素是一个字典。
每个字典元素都包含了一个视频样本的详细信息。这种结构可以方便地存储和访问整个数据集的数据。
总结:
如果是这样的话,那就不需要人工划分训练集和测试集了,这个骨架注释已经将训练集和测试集划分好了,代码里面直接调用这个骨骼注释文件就行
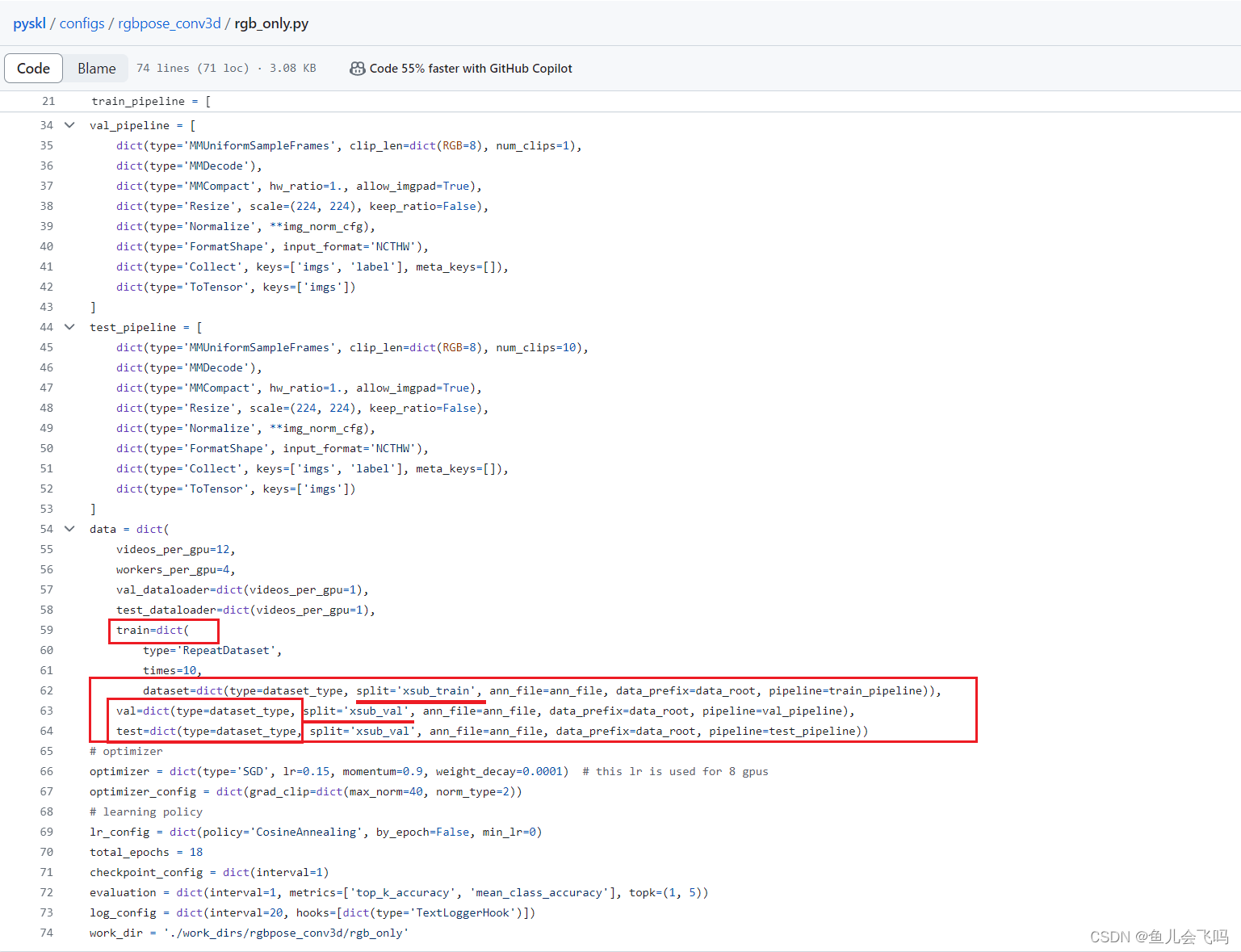
train=dict(
type='RepeatDataset',
times=10,
dataset=dict(type=dataset_type, split='xsub_train', ann_file=ann_file, data_prefix=data_root, pipeline=train_pipeline)),
val=dict(type=dataset_type, split='xsub_val', ann_file=ann_file, data_prefix=data_root, pipeline=val_pipeline),
test=dict(type=dataset_type, split='xsub_val', ann_file=ann_file, data_prefix=data_root, pipeline=test_pipeline))这个是一个嵌套的字典结构,用于配置动作识别任务的数据集。让我逐一解释一下:
-
train字段是一个字典,用于配置训练集:'type'键的值是'RepeatDataset',表示训练集是通过重复一个基础数据集得到的。'times'键的值是10,表示将基础数据集重复 10 次。'dataset'键对应的也是一个字典,用于配置基础数据集:'type'键的值是dataset_type,表示使用指定类型的数据集。'split'键的值是'xsub_train',表示使用训练集切分。'ann_file'键的值是ann_file,表示使用指定的注释文件。'data_prefix'键的值是data_root,表示使用指定的数据根路径。'pipeline'键的值是train_pipeline,表示使用指定的训练数据预处理流水线。
-
val字段是一个字典,用于配置验证集:'type'键的值是dataset_type,表示使用指定类型的数据集。'split'键的值是'xsub_val',表示使用验证集切分。'ann_file'键的值是ann_file,表示使用指定的注释文件。'data_prefix'键的值是data_root,表示使用指定的数据根路径。'pipeline'键的值是val_pipeline,表示使用指定的验证数据预处理流水线。
-
test字段是一个字典,用于配置测试集:'type'键的值是dataset_type,表示使用指定类型的数据集。'split'键的值是'xsub_val',表示使用验证集切分。'ann_file'键的值是ann_file,表示使用指定的注释文件。'data_prefix'键的值是data_root,表示使用指定的数据根路径。'pipeline'键的值是test_pipeline,表示使用指定的测试数据预处理流水线。
总之,这个配置字典定义了训练集、验证集和测试集的数据加载和预处理方式,为后续的动作识别模型训练和评估做好了准备。

pyskl/tools/data/README.md at main · kennymckormick/pyskl · GitHub















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









