






引入
抛出问题
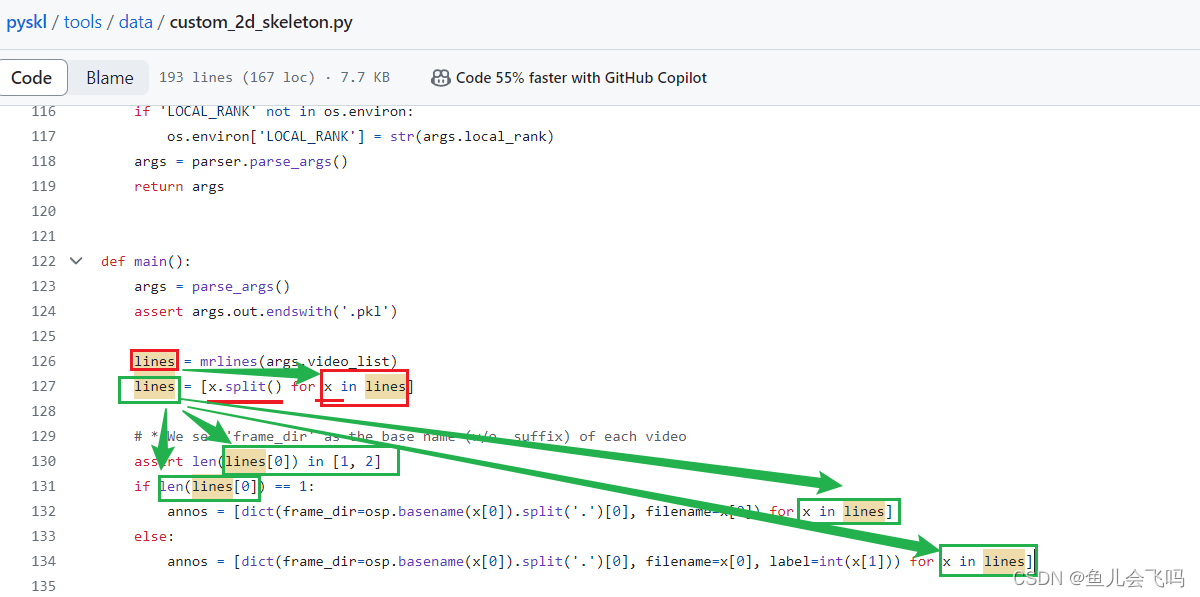
如果假设第127行代码x = "a b c", 那么 x.split() 会得到 ['a', 'b', 'c']。
那第132行代码x此时是列表还是之前的字符串?也就是说我想知道x[0]是什么意思,什么语法?
思路
关键在于第127行等号左边lines被赋值了一个新的值,也就是说第127行等号左边的lines和等号右边的lines是完全两个不一样的东西,虽然名字取得一样,但里面的东西发生了覆盖。
所以需要看第132行里面for x in lines是关键,这里的x是子列表
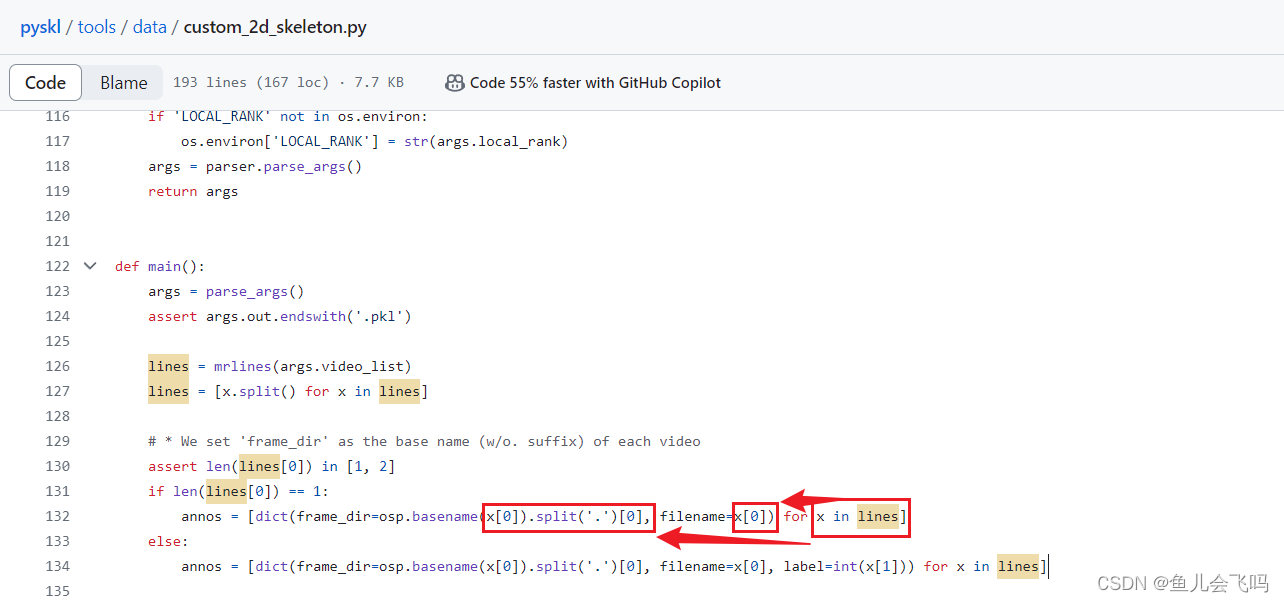
既然是子列表,那x[0]就表示子列表的第一个元素,也就是下面红框里面的第一部分(除了空格之后标签之外的信息)
能看到这一步,就已经把问题解决了
举例子
osp.basename(x[0]).split('.')[0] 这个表达式。
首先,我们假设 x[0] 的值是 "path/to/image.jpg"。
-
osp.basename(x[0])osp.basename()是一个函数,用于获取文件路径的基础名称。- 在这个例子中,它会返回
"image.jpg"。
-
osp.basename(x[0]).split('.')split('.')是一个字符串方法,用于将字符串按照指定的分隔符(这里是".")进行切分。- 在这个例子中,它会返回一个列表
["image", "jpg"]。
-
osp.basename(x[0]).split('.')[0]- 列表
["image", "jpg"]的第一个元素是"image"。 - 所以最终的结果是
"image"。
- 列表
综合起来:
x[0]代表一个文件路径,例如"path/to/image.jpg"osp.basename(x[0])获取文件名,得到"image.jpg"osp.basename(x[0]).split('.')将文件名按照"."分隔,得到["image", "jpg"]osp.basename(x[0]).split('.')[0]取列表的第一个元素,得到"image"
这个表达式的作用是从文件路径中提取出不带后缀的文件名。在某些场景下,这个信息可能会很有用,比如用于构建数据集的目录结构等。
验证
也可以查看一下train.pkl测试验证一下是否是这样的结果。
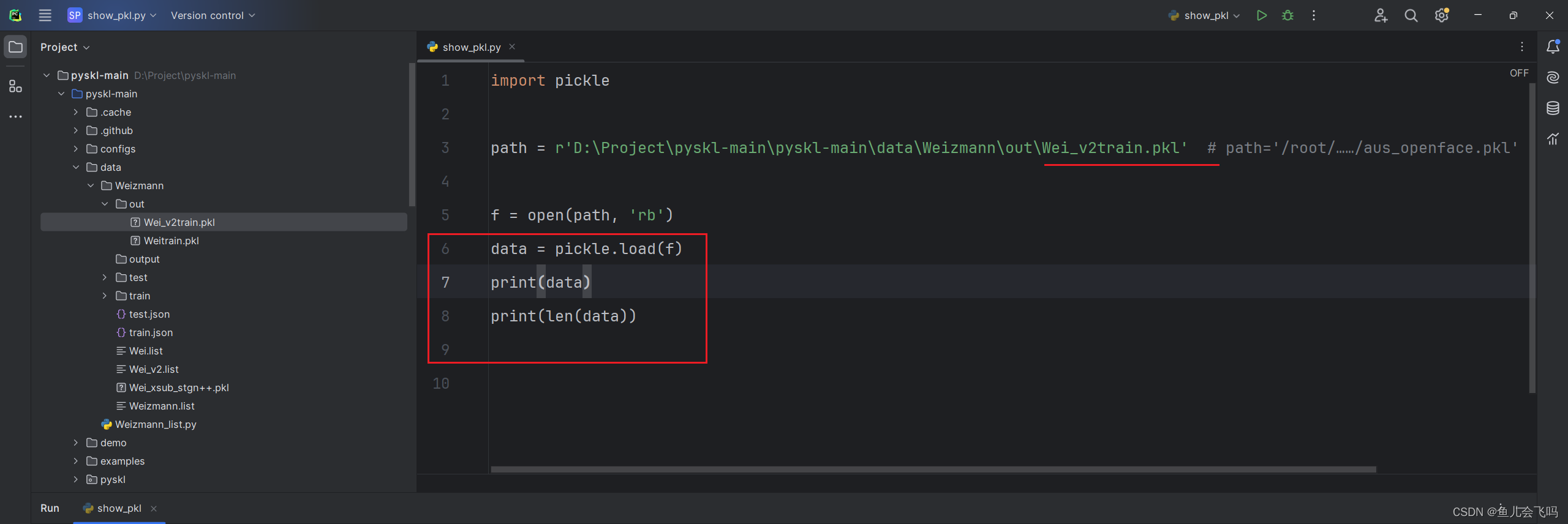
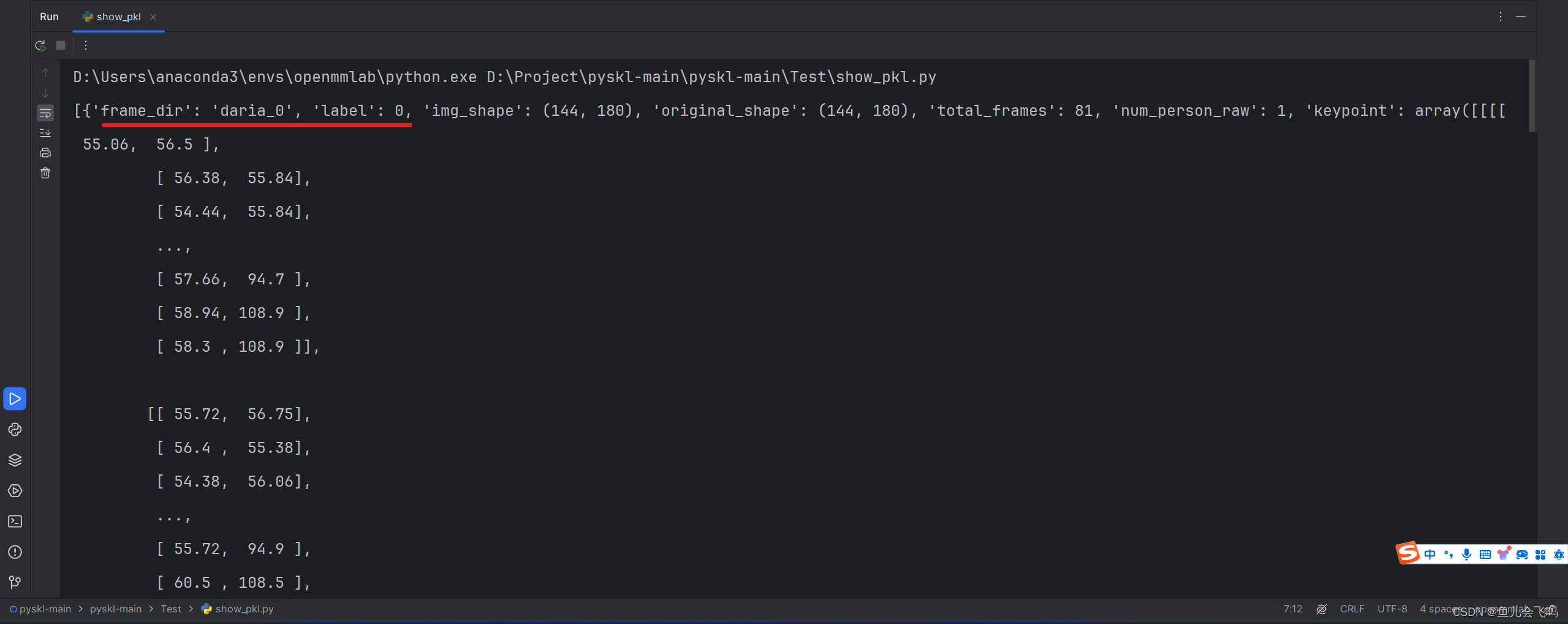
发现frame_dir确实是对应上的,label也确实是对应上的
if len(lines[0]) == 1:
annos = [dict(frame_dir=osp.basename(x[0]).split('.')[0], filename=x[0]) for x in
lines]
else:
annos = [dict(frame_dir=osp.basename(x[0]).split('.')[0], filename=x[0],
label=int(x[1])) for x in lines]-
因为
len(lines[0])等于 2,所以进入了else部分的代码。 -
在
else部分,代码使用列表推导式创建了一个字典列表annos。 -
每个字典包含 3 个键值对:
'frame_dir': 取x[0]的基础名称(不包含后缀)。'filename': 使用x[0]作为文件名。'label': 将x[1]转换为整数作为标签。
也就是说,对于 lines 列表中的每一行数据:
- 第一个元素
x[0]是文件名 - 第二个元素
x[1]是标签信息 - 我们将这两个信息都记录在生成的字典中
这种做法说明输入数据的格式是每行包含两个元素:文件名和标签。
通过这样的处理,我们可以在后续的代码中直接使用 annos 列表,它包含了文件名和标签信息,方便后续的数据处理和分析。
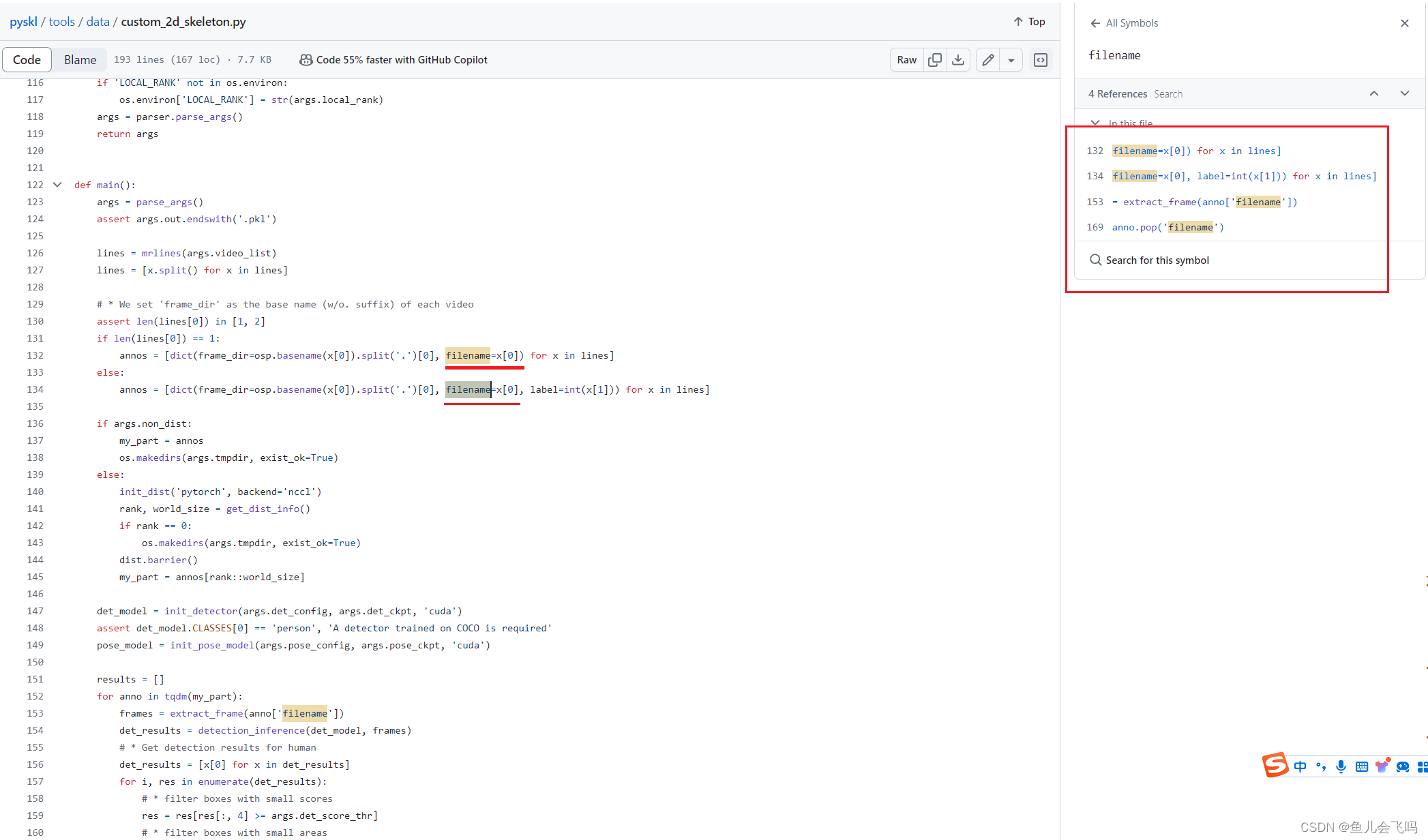
至于生成的字典里面为什么没有'filename'这个键,还需要进一步分析后面的代码逻辑。
pyskl/tools/data/custom_2d_skeleton.py at main · kennymckormick/pyskl · GitHub















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









