






data_root = '/root/autodl-tmp/COCO/whole_images/whole_images/'train_dataset = dict(
type='MultiImageMixDataset',
dataset=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True)
],
filter_empty_gt=False,
),
pipeline=train_pipeline)于是得到train_dataset这个字典里面的dataset里面的ann_file是下面这个路径
ann_file = '/root/autodl-tmp/COCO/whole_images/whole_images/annotations/instances_train2017.json'从打印的日志进行验证自己的猜测也可以
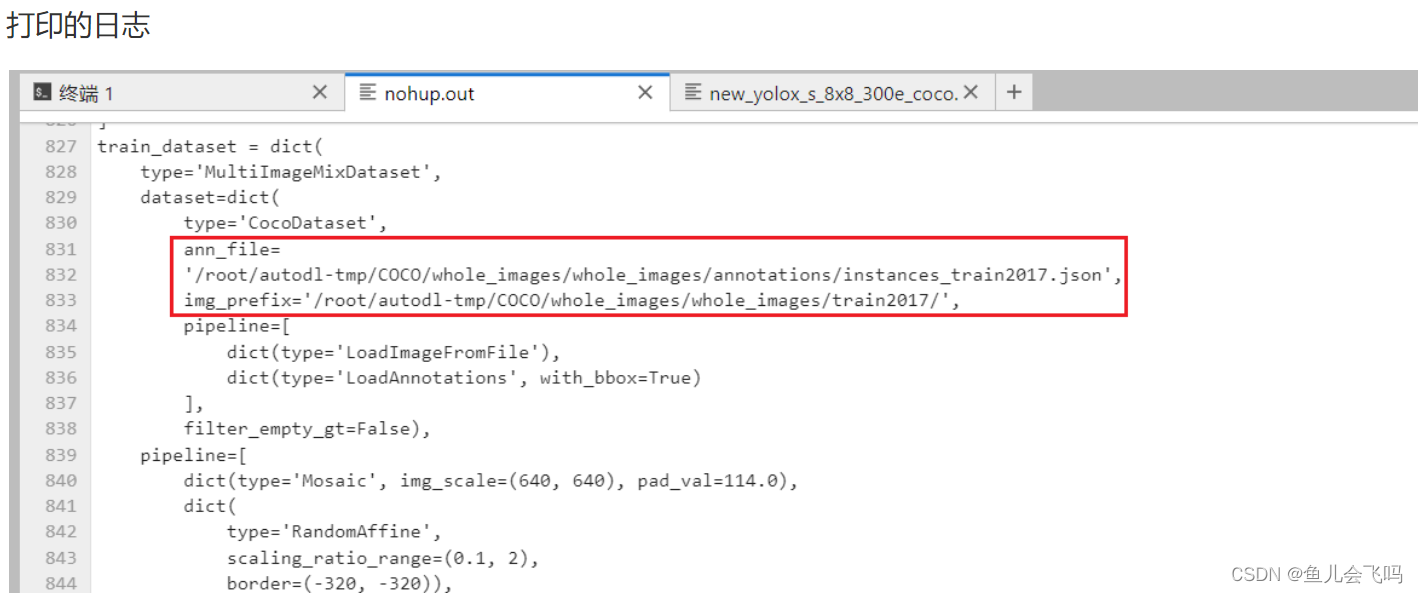
img_prefix也是同样的道理
img_prefix = '/root/autodl-tmp/COCO/whole_images/whole_images/train2017/'下面这里data也是同样的道理
data = dict(
samples_per_gpu=8,
workers_per_gpu=4,
persistent_workers=True,
train=train_dataset,
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline)) train=train_dataset,
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))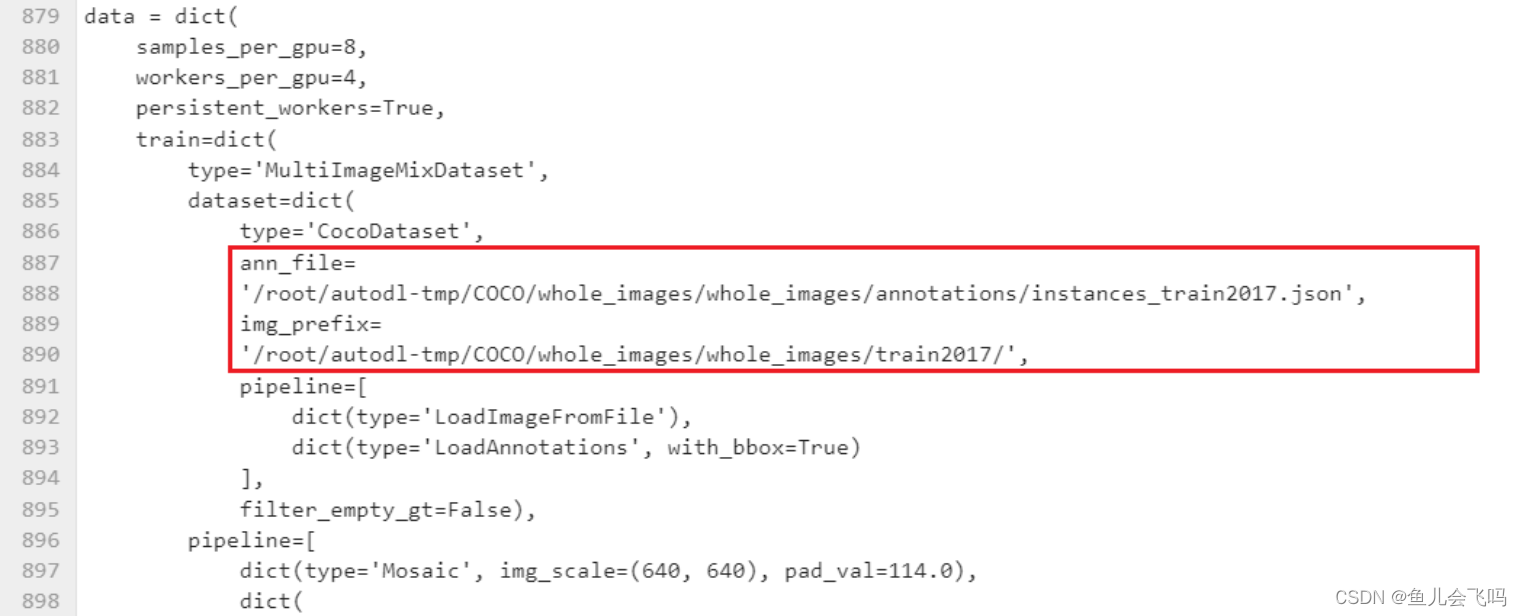

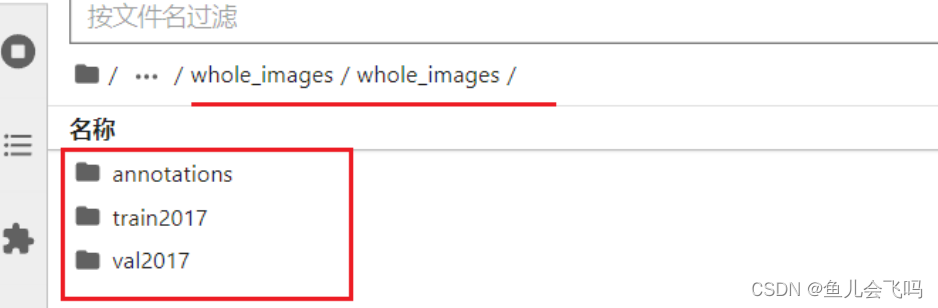
比对一下文件夹结构















 1901
1901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









