







1、爬虫简介
【1】什么是爬虫:
通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
【2】爬虫的价值:
1、实际应用;
2、就业;
【3】合法性:
1、爬虫在法律是不被禁止的;
2、具有违法风险(公开的信息是可以的);
3、干扰了被访问网站的正常运营(恶意爬虫);爬取了收到法律保护的特定类型的数据或者信息;
4、优化自己程序,避免被访问网站的正常运营;审查抓取的内容;(避免进入局子的方法)
【4】爬虫在使用场景中的分类:
1、通用爬虫
百度、谷歌等常见的浏览器都有一个抓取系统,通用爬虫是抓取系统的重要组成部分,它抓取的是一整张页面数据。
2、聚焦爬虫
建立在通用爬虫的基础之上,抓取的是页面中特定的、指定的局部内容。
3、增量式爬虫
检测网站中数据更新的情况,只会抓取网站中最新更新出来的数据。
【5】爬虫的矛与盾:
1、反爬机制:
门户网站可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
2、反反爬策略:
爬虫程序可以通过制定相应的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以爬取网站中相关的数据。
【6】robots.txt协议:
规定了网站中哪些数据可以爬取,哪些数据不可以爬取。假如看搜狐上的robots.txt规定,可以通过https://sohu.com/robots.txt访问,可以看到有些目录是可以被百度(Baiduspider)爬取(Allow),但是有些是不能被百度爬取的(Disallow)。
User-agent: Baiduspider
Disallow: /*?*
Allow: /a/*?*
Allow: /abroad_a/*?*
Allow: /picture/*?*
Allow: /*_a(/qihoo_a)/*?*
Allow: /collection/*?*
Allow: /ab_a/*?*
Allow: /classic*?*
Allow: /?*$
Allow: /new*?*
Allow: /business*?*
Allow: /it*?*
Allow: /fashion*?*
Allow: /leaening*?*
Allow: /health*?*
Allow: /yule*?*
Allow: /mt*?*
Allow: /travel*?*
Allow: /baobao*?*
Allow: /chihe*?*
Allow: /cul*?*
Allow: /history*?*
Allow: /gov*?*
Allow: /gongyi*?*
Allow: /police*?*
Allow: /mil*?*
Allow: /acg*?*
Allow: /astro*?*
Allow: /game*?*
Allow: /pets*?*
Allow: /sports*?*
Allow: /subject/*?*
User-agent: YisouSpider
Disallow: /*?*
Allow: /a/*?*
Allow: /abroad_a/*?*
Allow: /picture/*?*
Allow: /*_a(/qihoo_a)/*?*
Allow: /collection/*?*
Allow: /ab_a/*?*
Allow: /classic*?*
Allow: /?*$
Allow: /new*?*
Allow: /business*?*
Allow: /it*?*
Allow: /fashion*?*
Allow: /leaening*?*
Allow: /health*?*
Allow: /yule*?*
Allow: /mt*?*
Allow: /travel*?*
Allow: /baobao*?*
Allow: /chihe*?*
Allow: /cul*?*
Allow: /history*?*
Allow: /gov*?*
Allow: /gongyi*?*
Allow: /police*?*
Allow: /mil*?*
Allow: /acg*?*
Allow: /astro*?*
Allow: /game*?*
Allow: /pets*?*
Allow: /sports*?*
Allow: /subject/*?*
User-agent: Bytespider
Disallow: /*?*
Allow: /a/*?*
Allow: /abroad_a/*?*
Allow: /picture/*?*
Allow: /*_a(/qihoo_a)/*?*
Allow: /collection/*?*
Allow: /ab_a/*?*
Allow: /classic*?*
Allow: /?*$
Allow: /new*?*
Allow: /business*?*
Allow: /it*?*
Allow: /fashion*?*
Allow: /leaening*?*
Allow: /health*?*
Allow: /yule*?*
Allow: /mt*?*
Allow: /travel*?*
Allow: /baobao*?*
Allow: /chihe*?*
Allow: /cul*?*
Allow: /history*?*
Allow: /gov*?*
Allow: /gongyi*?*
Allow: /police*?*
Allow: /mil*?*
Allow: /acg*?*
Allow: /astro*?*
Allow: /game*?*
Allow: /pets*?*
Allow: /sports*?*
Allow: /subject/*?*
Allow: /integration-api/*?*
Allow: /public-api/*?*想看网站xxxxx的robots协议的话,可以进去网址中xxxxx.com进行查看。
【7】http协议
服务器和客户端进行数据交互的一种形式。打开百度首页,在空白处单击右键出现“审查元素”,如下图,随便点开一个对象,如下图:

可以看到请求头信息和响应头信息。
常用请求头信息:
(1)User-Agent:指请求载体的身份标识。
在上图中,在请求头信息中可以看到“User-Agent”,内容是:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36
(2)Connection:请求完毕之后,是断开连接还是保持连接。
常用响应头信息:
(1)Content-Type:服务器响应回客户端的数据类型(可以是字符串\JSON等)。
【8】https协议
指安全的http(超文本传输)协议。进行了数据加密。
【9】加密方式
(1)对称秘钥加码;
(2)非对称秘钥加密;
(3)证书秘钥加密(https)。
【10】爬虫的重点步骤是什么?
网页分析;网页分析;网页分析。
2、python库
python中基于网络请求的模块有urllib模块和requests模块。
2.1、requests库
python中原生的一款基于网络请求的模块。作用:模拟浏览器发请求。浏览器发起请求过程:
(1)指定url;
(2)发起请求;
(3)获取响应数据;
(4)持久化存储。
使用requests模拟上面的流程即可。
实战:爬取百度首页的页面数据
# -*-coding = utf-8-*-
# 爬虫爬取百度首页内容,并保存称一个html文件。
import requests
if __name__ == '__main__' :
# 第一步:指定url、指定认证header
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
# 第二步:发起请求;get()会返回一个相应对象
response = requests.get(url = url, headers=header)
# 第三步:获取响应数据[.text是返回字符串形式的相应数据]
page_text = response.text
print(page_text)
# 第四步:持久化存储
with open("./temp/test-0-baiduwangye.html", 'w', encoding='utf-8') as fp :
fp.write(page_text)
print('保存成功!')
2.2、requests中的7中主要方法
| requests.request(method, url, **kwagrs) | 构造一个请求,支持其余的六种方法 |
| requests.get(url, params = None, **kwargs) | 获取html的主要方法 |
| requests.head() | 获取html头部信息的主要方法 |
| requests.post() | 向html网页提交post请求的方法 |
| requests.put() | 向html网页提交put请求的方法 |
| requests.patch() | 向html提交局部修改的请求 |
| requests.delete() | 向html提交删除请求 |
| requests.options() |
注:get,head是从服务器获取信息到本地;put,post,patch,delete是从本地向服务器提交信息。
2.3、requests.request():构造一个请求,支持其余的六种方法
示例:
response = requests.request(method, url, **kwagrs)参数:
(1)method:是请求方式,对应get、head、post、put、patch、delete、options等7种方法;

(2)url:是获取页面的url链接;
(3)**kwagrs:是控制访问的参数,有13个:
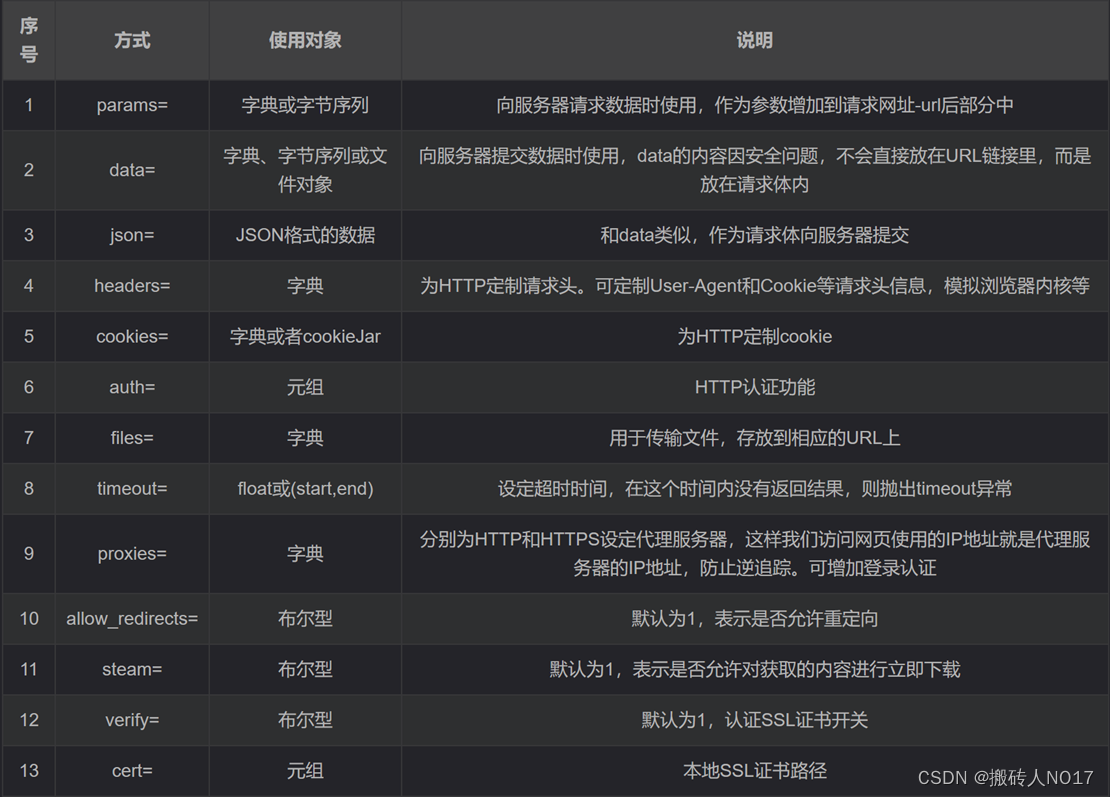
**kwagrs是控制访问的参数,均为可选项,有13种,详细解释如下:
(3.1)params:字典或字节序列,作为参数增加到url中,使用这个参数可以把一些键值对以?key1=value1&key2=value2的模式增加到url中。
import requests
def test() :
url = "https://www.baidu.com"
data = {"key1" : "data1", "key2" : "data2"}
response = requests.get(url=url, params=data)
print(response.url)
# 结果为:https://www.baidu.com/?key1=data1&key2=data2
if __name__ == '__main__':
test()
(2)data:字典,字节序列或文件对象,重点作为向服务器提供或提交资源,作为requests的内容,与params不同的是,data提交的数据并不放在url链接里, 而是放在url链接对应位置的地方作为数据来存储,它也可以接受一个字符串对象。
import requests
def test() :
url = "https://www.baidu.com"
data = {"key1" : "data1", "key2" : "data2"}
response = requests.put(url=url, data=data)
print(response.url)
if __name__ == '__main__':
test()
(3)json:json格式的数据,也是http最经常使用的数据格式,作为request的内容。
import requests
def test() :
url = "https://www.baidu.com"
data = {"key1" : "data1", "key2" : "data2"}
response = requests.post(url=url, json=data)
print(response.url)
if __name__ == '__main__':
test()
(4)headers:字典,可以用这个字段来定义http的访问的http头,可以用来模拟任何我们想模拟的浏览器来对url发起访问。
import requests
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.put(url=url, headers=header)
print(response.headers)
if __name__ == '__main__':
test()
(5)cookies:字典或CookieJar,指的是从http中解析cookie
import requests
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.post(url=url, headers=header)
cookies = response.cookies
print(type(cookies))
if __name__ == '__main__':
test()
(6)auth:元组,用来支持http认证功能
import requests
from requests.auth import HTTPBasicAuth
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.get(url=url, headers=header, auth=HTTPBasicAuth('user', 'user'))
print(response.status_code)
if __name__ == '__main__':
test()
(7)files:字典,用来向服务器传输文件时使用的字段
import requests
from requests.auth import HTTPBasicAuth
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
fs = {"files" : open('xxx/xxx/xxx/cccc.txt', 'rb')}
response = requests.put(url=url, headers=header, files=fs)
print(response.status_code)
if __name__ == '__main__':
test()
(8)timeout:设定超时时间,单位为秒,当发起一个get请求时可以设置一个timeout时间,如果在timeout时间内请求内容没有返回,将产生一个timeout的异常。
import requests
from requests.auth import HTTPBasicAuth
from requests.exceptions import ReadTimeout
def test() :
try:
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.get(url=url, headers=header, timeout=0.5)
print(response.status_code)
except ReadTimeout :
print('Time Out')
if __name__ == '__main__':
test()
(9)proxies:字典,用来设置访问代理服务器,可以增加登录认证
import requests
from requests.auth import HTTPBasicAuth
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.get(url=url, headers=header, proxies=True)
print(response.status_code)
if __name__ == '__main__':
test()
(10)allow_redirects:开关,表示是否允许对url进行重定向,默认为True
import requests
from requests.auth import HTTPBasicAuth
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.get(url=url, headers=header, allow_redirects=True)
print(response.status_code)
if __name__ == '__main__':
test()
(11)stream:开关,指是否对获取内容进行立即下载,默认为True
import requests
from requests.auth import HTTPBasicAuth
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.get(url=url, headers=header, stream=True)
print(response.status_code)
if __name__ == '__main__':
test()
(12)verify:开关,用于认证SSL整数,默认为True
import requests
from requests.auth import HTTPBasicAuth
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.get(url=url, headers=header, verify=True)
print(response.status_code)
if __name__ == '__main__':
test()
(13)cert:用于设置保存本地SSL证书路径
import requests
from requests.auth import HTTPBasicAuth
def test() :
url = "https://www.baidu.com"
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/108.0.5359.95 Safari/537.36'
}
response = requests.get(url=url, headers=header, cert=('../../*.crt', '../../.ssh/*.key'))
print(response.status_code)
if __name__ == '__main__':
test()
2.4、异常
| requests.ConnectionError | 网络连接异常,如DNS查询失败,拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.ToolManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
2.5、Response对象
示例:
response = requests.get(url)解读:
response:是一个Response对象,一个包含服务器资源的对象;
.get(url):是一个Request对象,构造一个向服务器请求资源的Request。
获取response的类型:type(response)。
显示response具有的属性:dir(response)。
response具有如下几个属性:
| 属性 | 说明 |
| response.status_code | HTTP请求返回状态码,200表示成功 |
| response.text | HTTP响应的字符串形式,即url对应的页面内容 |
| response.encoding | 从HTTP header中猜测的响应内容的编码方式 |
| response.apparent_encoding | 从内容中分析响应内容的编码方式(备选编码方式) |
| response.content | HTTP响应内容的二进制形式 |
| response.json | 返回JSON格式,可能抛出异常 |
| response.url | 返回请求URL |
| response.headers | 请求头 |
| response.cookies | 返回RequestsCookieJar对象 |
| response.history | 返回以列表存储的请求历史记录 |
3、示例
3.1、实现一个网页采集器
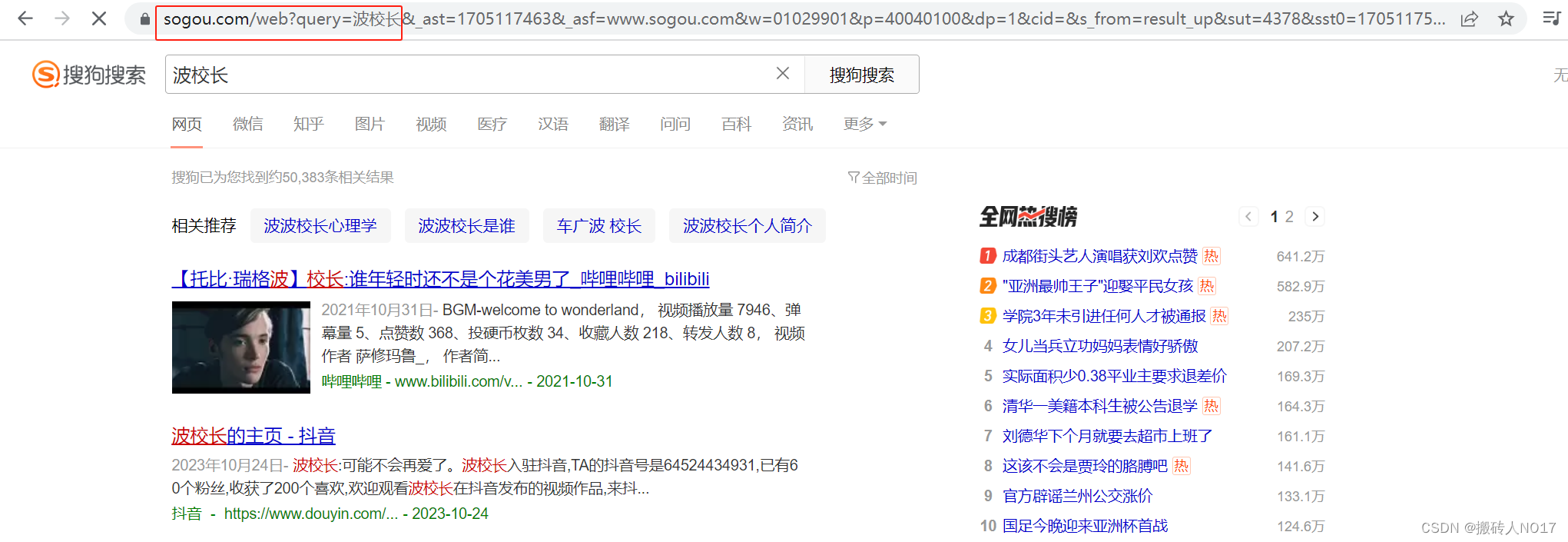
分析网页:在搜狗浏览器中搜索“波校长”得到的结果页面如下:
# -*-coding = utf-8-*-
# 爬取搜狗浏览器中任意词条的搜索结果。
import requests
'''
反爬策略:UA检测
反反爬机制:UA伪装(UA:User-Agent:请求载体的身份标识)
UA伪装:门户网站的服务器会检测对应请求的载体身份标识,
如果检测到请求的载体身份标识为某一款浏览器,就说明该请求是一个正常的请求;
如果检测到请求的载体身份标识不是某一款浏览器,则表明该请求为不正常的请求(爬虫);
服务器端就很有可能拒绝该请求。
UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器。
爬虫中一定要进行UA伪装。
'''
if __name__ == '__main__' :
'''
url = "https://www.sogou.com/web?query=%E6%B3%A2%E6%A0%A1%E9%95%BF"
url = "https://www.sogou.com/web?query=波校长"
上述这两个utl是一样的。
'''
# UA伪装:将对应的User-Agent封装到一个字典中
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
# 处理url携带的参数,封装到字典中;动态参数
kw = input('enter a word: ')
param = {
'query' : kw
}
url = "https://www.sogou.com/web"
# 对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response = requests.get(url = url, params = param, headers = header)
# 得到结果
page_text = response.text
# 存储
file_name = './temp/test-1-网页采集器-' + kw + '.html'
with open(file_name, 'w', encoding='utf-8') as fp :
fp.write(page_text)
print(file_name, '保存成功!')
print(response.url)
3.2、爬取百度翻译内容
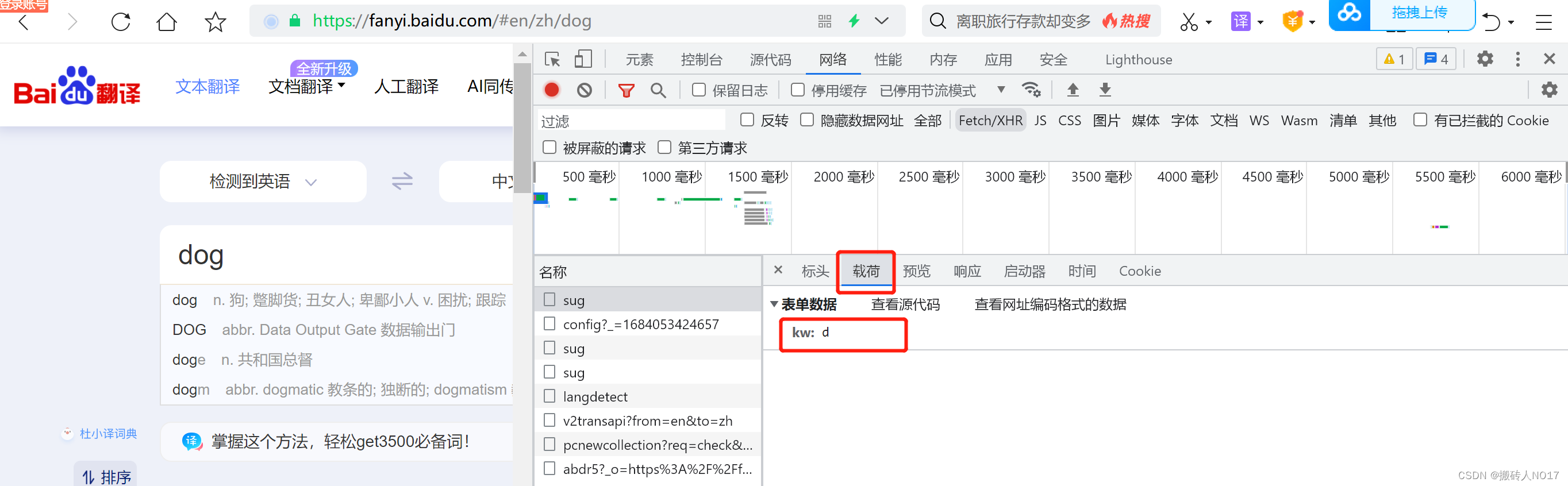
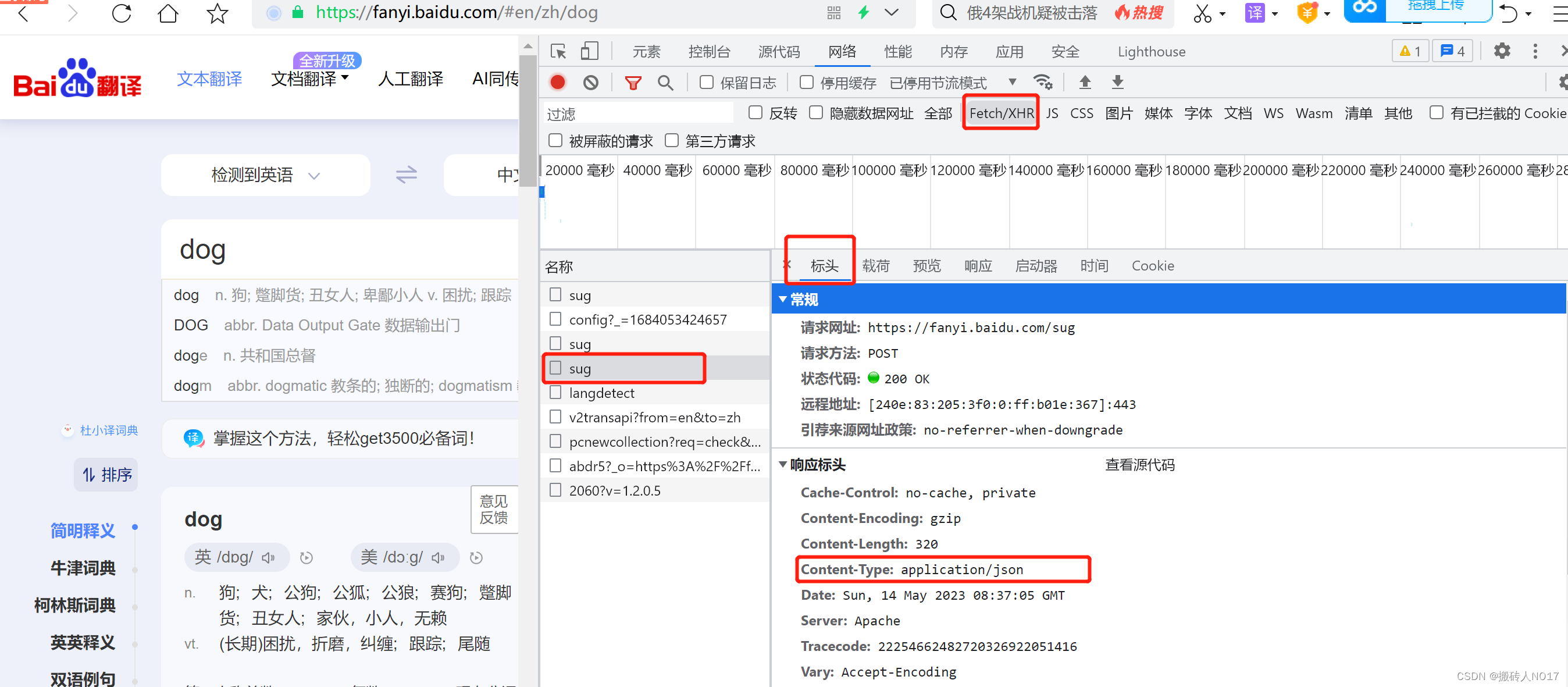
分析网页:在百度翻译中,依次输入“d” “o” “g”三个字符,查看网页Fetch/XHR的变化,出现三个“sug”的POST请求,如下:



# -*-coding = utf-8-*-
# 爬取百度翻译。
import requests
import json
if __name__ == '__main__' :
# step1:指定url
post_url = "https://fanyi.baidu.com/sug"
# step2:UA伪装:将对应的User-Agent封装到一个字典中
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
# step3:处理post携带的参数,封装到字典中;动态参数
fanyi_word = input('enter a word: ')
data = {
'kw' : fanyi_word
}
# step4:请求发送
response = requests.post(url = post_url, data = data, headers = header)
# step5:获得响应数据;json()方法返回的是obj(确认服务器响应数据是json的,才可以用json())
dict_obj = response.json()
print(dict_obj)
# step6:存储
file_name = './temp/test-2-百度翻译-' + fanyi_word + '.json'
fp = open(file_name, 'w', encoding='utf-8')
json.dump(dict_obj, fp = fp, ensure_ascii = False)
print('保存成功!')
print(response.url)
3.3、爬取豆瓣电影分类排行榜(豆瓣电影中的电影详情数据)
分析网页,刚打开网页时,一共刷新了20个电影的信息,返回的是一个JSON文件,载荷中start=0,limit=20;

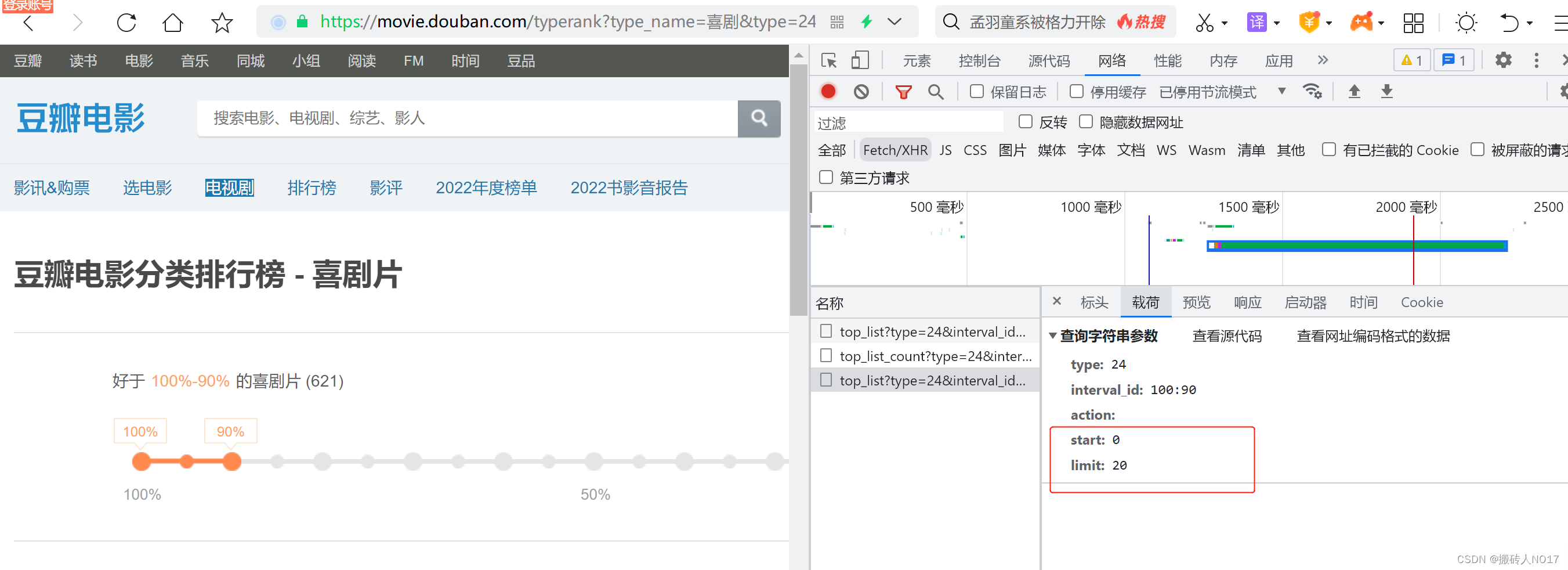
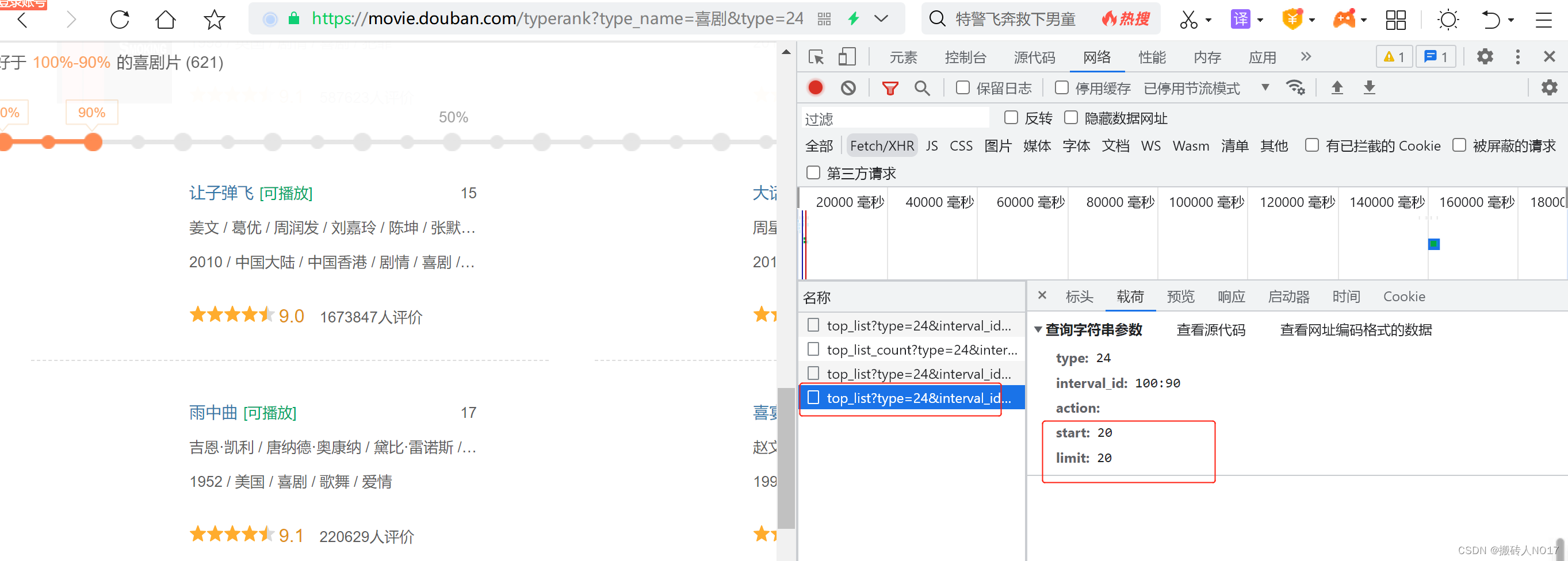
然后再网页面,往下滑动网页,又刷新出了20个电影的详细信息,载荷中start=20,limit=20;再往后可以一次类推。
# -*-coding = utf-8-*-
# 爬取豆瓣电影中电影详情数据。
import requests
import json
if __name__ == '__main__' :
# step1:指定url
url = "https://movie.douban.com/j/chart/top_list"
# step2:UA伪装:将对应的User-Agent封装到一个字典中
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
# step3:处理get携带的参数,封装到字典中;动态参数
data = {
'type' : '24',
'interval_id' : '100:90',
'action' : '',
'start' : '1', # 从库中的第几部电影去取
'limit' : '68' # 一次取出个个数
}
# step4:请求发送
response = requests.get(url = url, params = data, headers = header)
# step5:获得响应数据;json()方法返回的是obj(确认服务器响应数据是json的,才可以用json())
list_data = response.json()
print(list_data)
# step6:存储
file_name = './temp/test-3-douban-' + 'douban.json'
fp = open(file_name, 'w', encoding='utf-8')
json.dump(list_data, fp = fp, ensure_ascii = False)
# ensure_ascii = False 中文不用ascii形式去写
print('保存成功!')
3.4、爬取肯德基餐厅查询肯德基餐厅信息查询 中指定的餐厅数
分析网页,在“餐厅关键字”输入“北京”,然后回车得到如下的数据。是一个post请求,返回的是一个text的数据类型。载荷携带的信息如下:


# -*-coding = utf-8-*-
# 爬取肯德基餐厅信息。
import requests
import json
if __name__ == '__main__' :
# step1:指定url
post_url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx"
# step2:UA伪装:将对应的User-Agent封装到一个字典中
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
# step3:处理post携带的参数,封装到字典中;动态参数
data = {
'op' : 'keyword',
'cname' : '',
'pid' : '',
'keyword' : '北京',
'pageIndex' : '1', # 查询返回的页码
'pageSize' : '10' # 查询返回的每页的数据的个数
}
# step4:请求发送
response = requests.post(url = post_url, data = data, headers = header)
# step5:获得响应数据;json()方法返回的是obj(确认服务器响应数据是json的,才可以用json())
text = response.text
print(text)
# step6:存储
print('保存成功!')















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









