








Scheduler
特殊的 Controller,工作原理与其他控制器无差别
Scheduler 的特殊职责在于监控当前集群所有未调度的Pod,并且获取当前集群所有节点的健康
状况和资源使用情况,为待调度 Pod 选择最佳计算节点,完成调度。
调度阶段分为:
- Predict:过滤不能满足业务需求的节点,如资源不足,端口冲突等。
- Priority:按既定要素将满足调度需求的节点评分,选择最佳节点。
- Bind:将计算节点与 Pod 绑定,完成调度。

调度器其实和控制器的行为是一致的,调度器其实就做三个动作,第一个动作叫做filter或者可以成为predict,比如一个集群有5000个节点,用户发来一个请求,一个业务需要一些cpu和内存资源。
要对这个做调度怎么做呢,首先要把不满足需求的节点过滤掉,先忽略掉,这样满足需求的节点数就下降了,这100台里面选什么是最佳的呢?这样调度器就会按照不同的因素去做一个评分,这个过程叫过Priority或者叫做score,这样相当于将所有的节点做个排序,最终将最优的节点和pod产生绑定关系。这样,一个调度就算完成了。

-------------------------------------------------------------------------------------------------------------------------------
在 Kubernetes 项目中,默认调度器的主要职责,就是为一个新创建出来的 Pod,寻找一个最合适的节点(Node)。
而这里“最合适”的含义,包括两层:
- 从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点。
- 从第一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果。
所以在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检查每个 Node。然后,再调用一组叫作 Priority 的调度算法,来给上一步得到的结果里的每个 Node 打分。最终的调度结果,就是得分最高的那个 Node。
而我在前面的文章中曾经介绍过,调度器对一个 Pod 调度成功,实际上就是将它的 spec.nodeName 字段填上调度结果的节点名字。
[root@master ~]# kubectl get pod -n ms -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
eureka-0 0/1 Running 1 37h 10.233.90.8 node1 <none> <none>
eureka-1 0/1 Running 1 37h 10.233.96.6 node2 <none> <none>
eureka-2 0/1 Running 1 37h 10.233.90.9 node1 <none> <none>
[root@master ~]# kubectl get pod eureka-1 -n ms -o yaml | grep -i nodename
nodeName: node2在 Kubernetes 中,上述调度机制的工作原理,可以用如下所示的一幅示意图来表示。
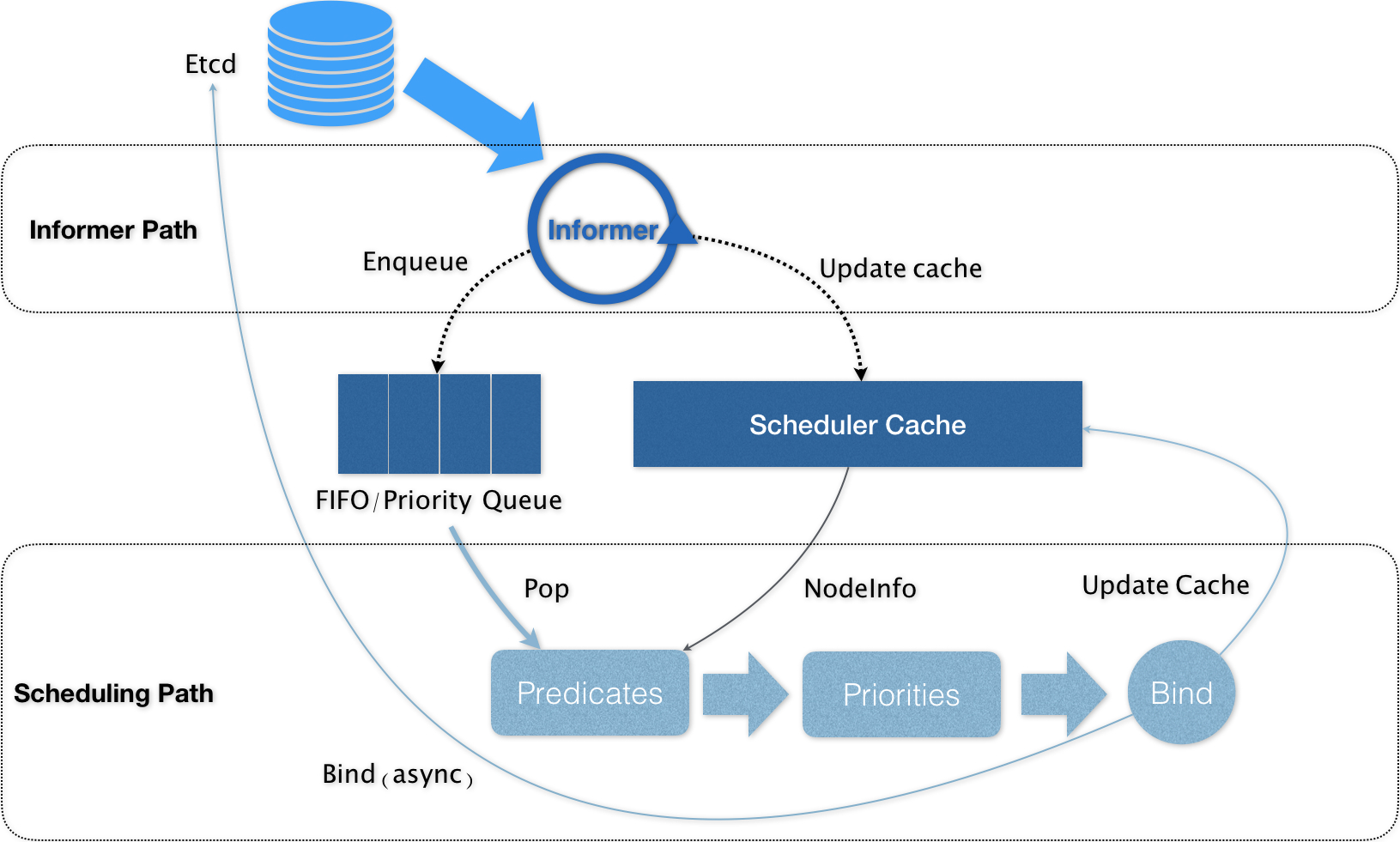
可以看到,Kubernetes 的调度器的核心,实际上就是两个相互独立的控制循环。
第一个控制循环 Informer Path 待调度 Pod 添加进调度队列
其中,第一个控制循环,我们可以称之为 Informer Path。它的主要目的,是启动一系列 Informer,用来监听(Watch)Etcd 中 Pod、Node、Service 等与调度相关的 API 对象的变化。比如,当一个待调度 Pod(即:它的 nodeName 字段是空的)被创建出来之后,调度器就会通过 Pod Informer 的 Handler,将这个待调度 Pod 添加进调度队列。
在默认情况下,Kubernetes 的调度队列是一个 PriorityQueue(优先级队列),并且当某些集群信息发生变化的时候,调度器还会对调度队列里的内容进行一些特殊操作。这里的设计,主要是出于调度优先级和抢占的考虑,我会在后面的文章中再详细介绍这部分内容。
此外,Kubernetes 的默认调度器还要负责对调度器缓存(即:scheduler cache)进行更新。事实上,Kubernetes 调度部分进行性能优化的一个最根本原则,就是尽最大可能将集群信息 Cache 化,以便从根本上提高 Predicate 和 Priority 调度算法的执行效率。
第二个控制循环 Scheduling Path Predicates 算法进行“过滤” 调用 Priorities 算法为Node 打分
- Scheduling Path 的主要逻辑,就是不断地从调度队列里出队一个 Pod。然后,调用 Predicates 算法进行“过滤”。这一步“过滤”得到的一组 Node,就是所有可以运行这个 Pod 的宿主机列表。当然,Predicates 算法需要的 Node 信息,都是从 Scheduler Cache 里直接拿到的,这是调度器保证算法执行效率的主要手段之一。
- 接下来,调度器就会再调用 Priorities 算法为上述列表里的 Node 打分,分数从 0 到 10。得分最高的 Node,就会作为这次调度的结果。
- 调度算法执行完成后,调度器就需要将 Pod 对象的 nodeName 字段的值,修改为上述 Node 的名字。这个步骤在 Kubernetes 里面被称作 Bind。
NodeName:一旦 Pod 的这个字段被赋值,Kubernetes 项目就会被认为这个 Pod 已经经过了调度,调度的结果就是赋值的节点名字。所以,这个字段一般由调度器负责设置,但用户也可以设置它来“骗过”调度器,当然这个做法一般是在测试或者调试的时候才会用到。















 3992
3992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









