







 本文介绍如何在Dashboard中通过添加参数变量,实现按节点过滤监控数据,使用PromQL查询语句动态调整展示的节点信息,提升数据可视化效率。
本文介绍如何在Dashboard中通过添加参数变量,实现按节点过滤监控数据,使用PromQL查询语句动态调整展示的节点信息,提升数据可视化效率。
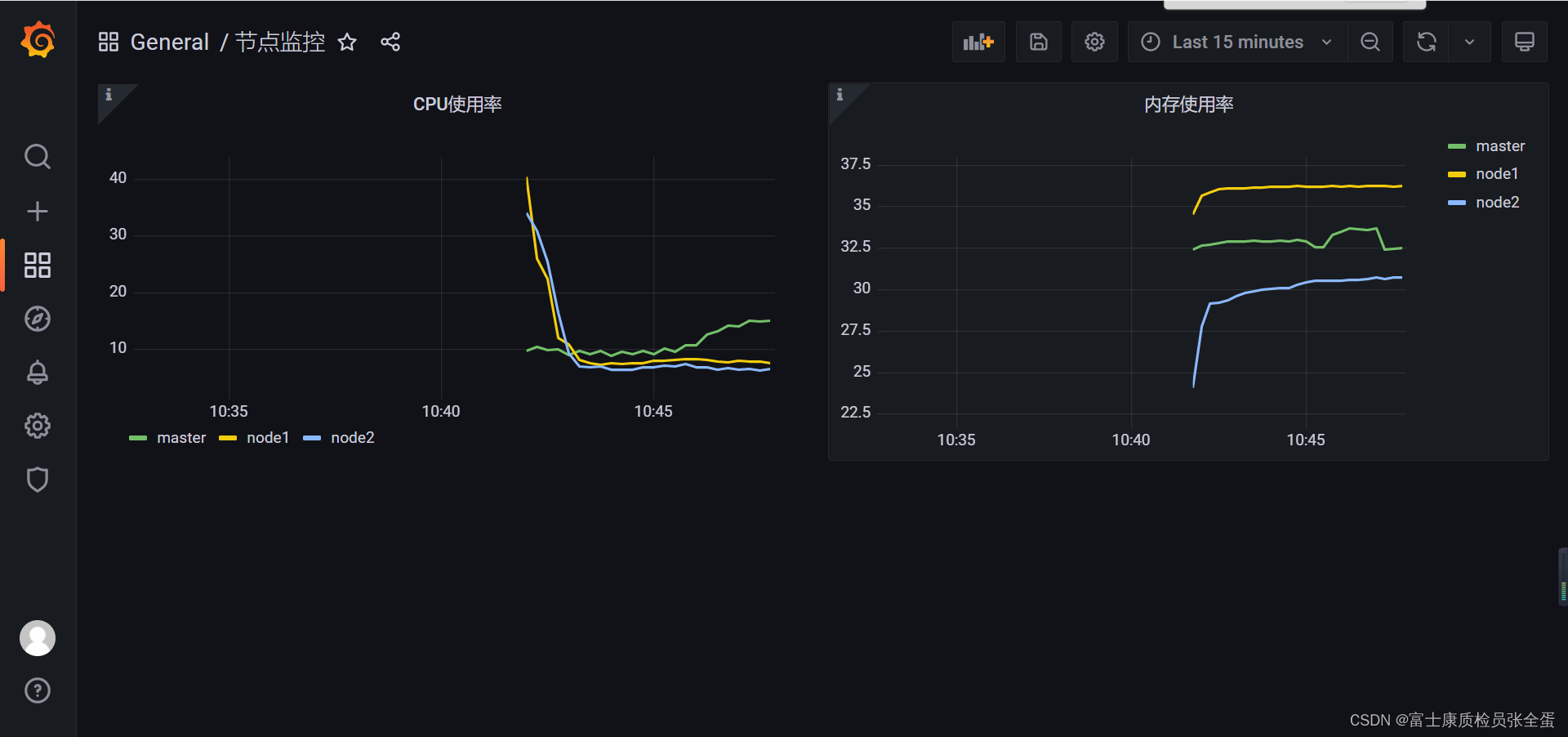
现在我们在一个 Dashboard 中添加了两个 Panel,我们可以很明显看到会直接将所有的节点信息展示在同一个面板中,但是如果有非常多的节点的话数据量就非常大了,这种情况下我们最好的方式是将节点当成参数(通过这个参数添加到Promql里面去,实现对时间序列的过滤,比如只过滤出某些节点),可以让用户自己去选择要查看哪一个节点的监控信息,要实现这个功能,我们就需要去添加一个以节点为参数的变量来去查询监控数据。
步骤一:打开dashboard设置 添加参数 过滤信息
之前将将panel添加到了dashboard里面来了。但是这里有个非常明显的缺陷,这里将所有节点的信息展示到了panel,如果节点的数量非常多,那么这里面的曲线就非常非常的多了,这样看起来就会非常不方便。
这种情况下面我们一般会去做下拉框,选择某个节点,只看某个几点的相关信息。
这样就需要使用granfa里面一个功能参数:可以添加一些节点的参数,来做一个筛选。
右上角有个dashboard设置。点击 Dashboard 页面右上方的 Dashboard settings 按钮,进入配置页面:
在该 Settings 页面可以来对整个 Dashboard 进行配置,比如名称、标签、变量等:
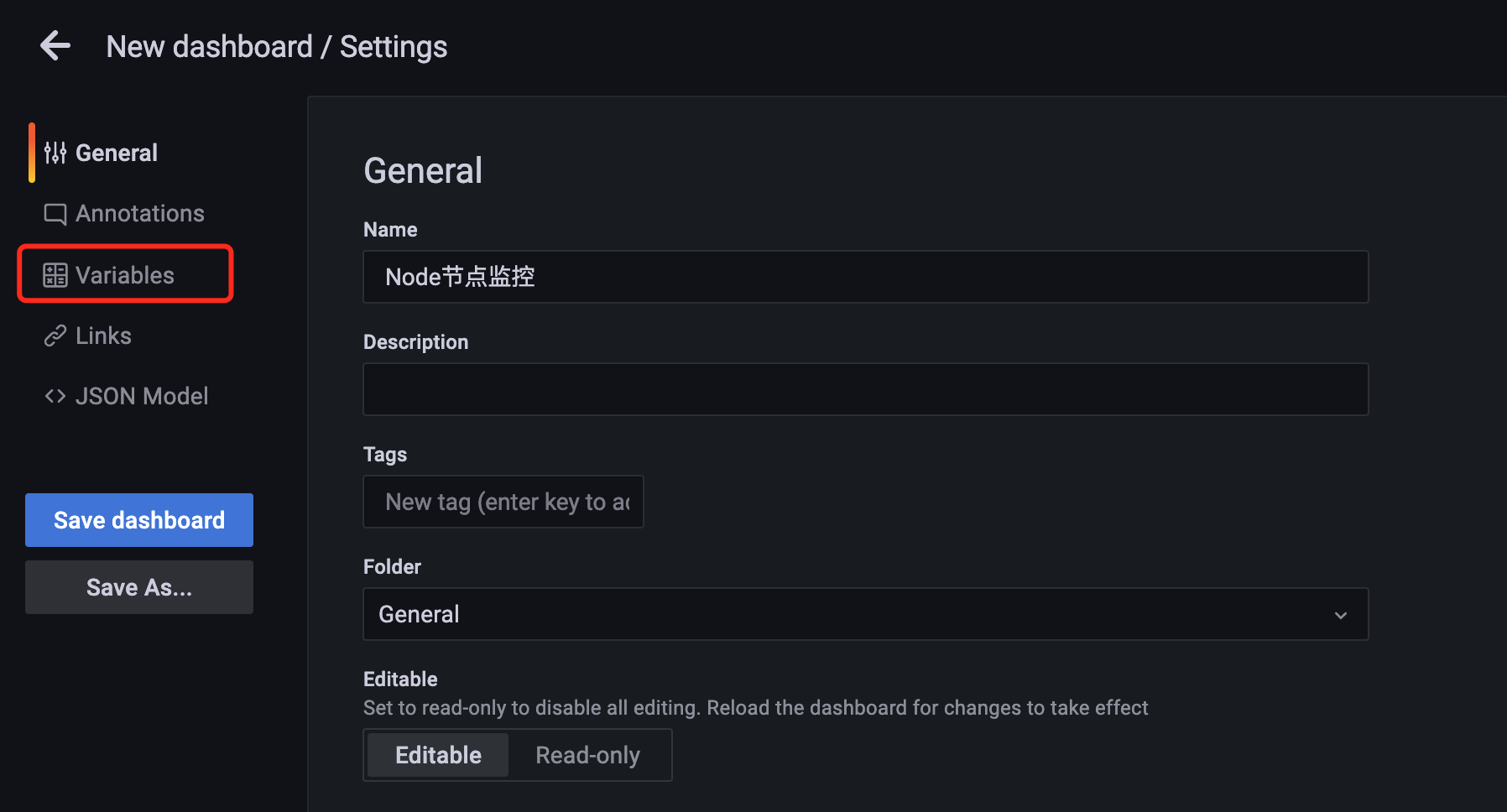
这样就来到了dashboard的配置页面,这里就可以去创建一个变量。
这里我们点击左边的 Variables 添加一个变量,变量支持更具交互性和动态性的仪表板,我们可以在它们的位置使用变量,而不是在指标查询中硬编码,变量显示为 Dashboard 顶部的下拉列表,这些下拉列表可以轻松更改仪表板中显示的数据。
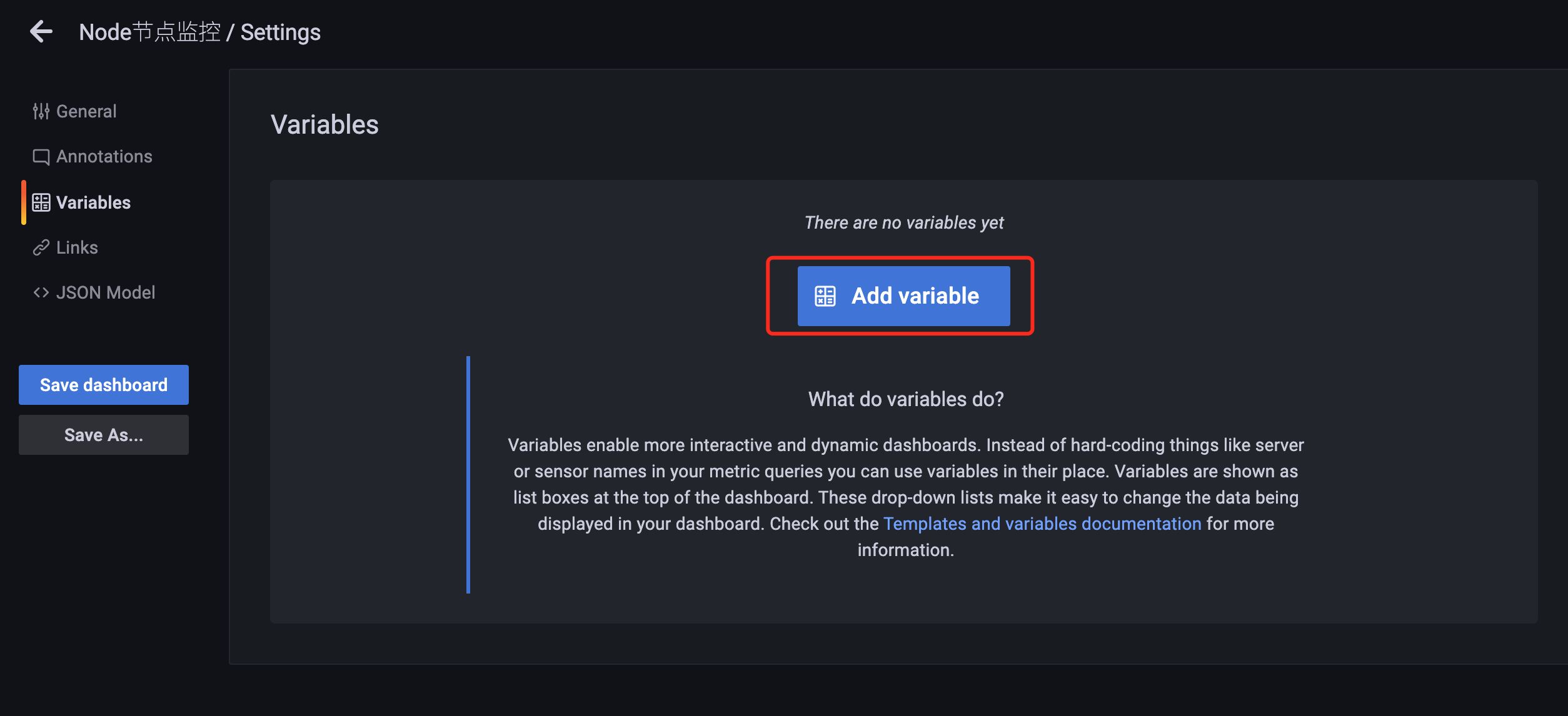
步骤二 配置dashboard 变量设置
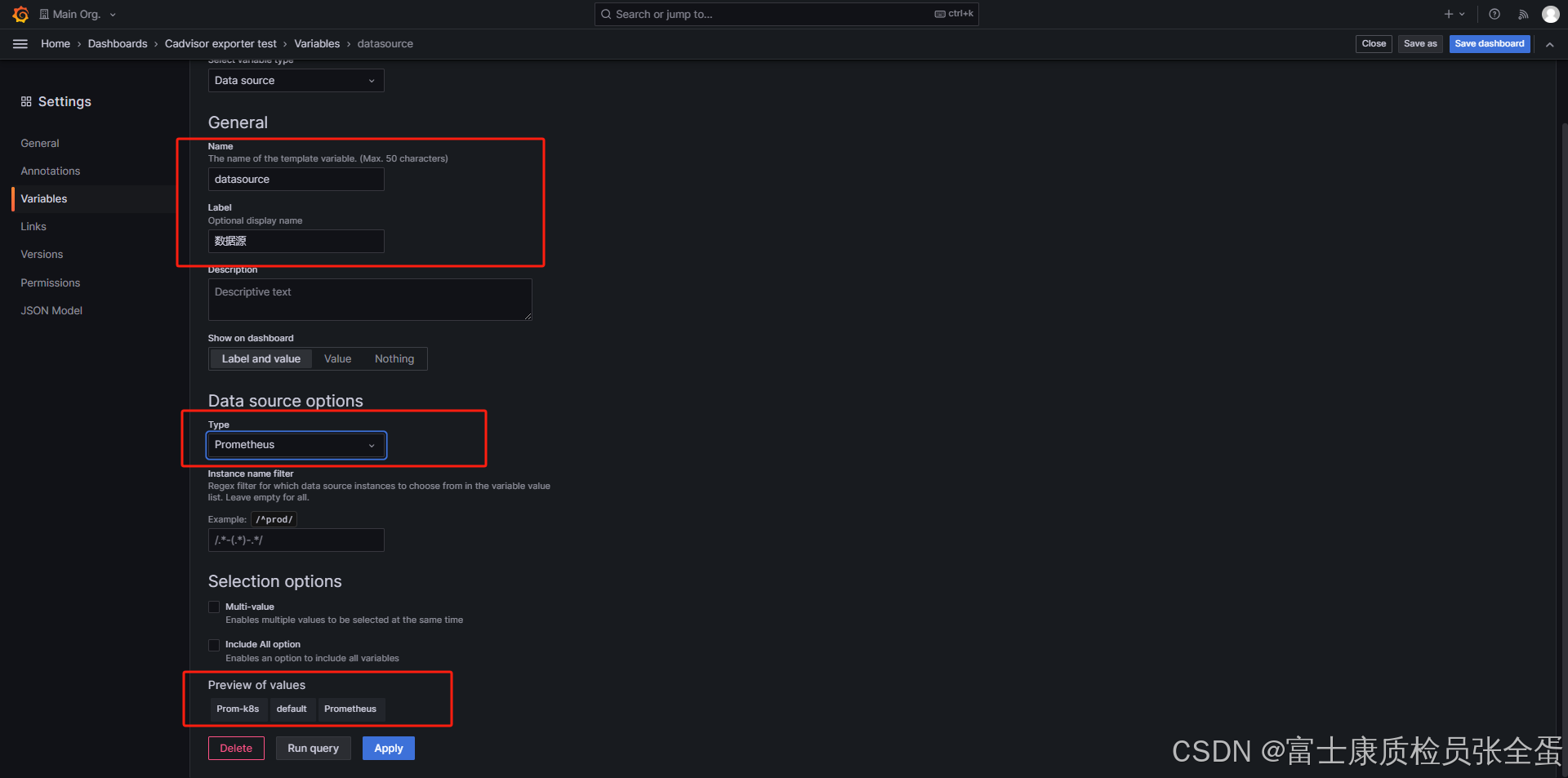
为了能够选择节点数据,这里我们定义了一个名为 instance 的变量名,在添加变量的页面中主要包括如下一些属性:
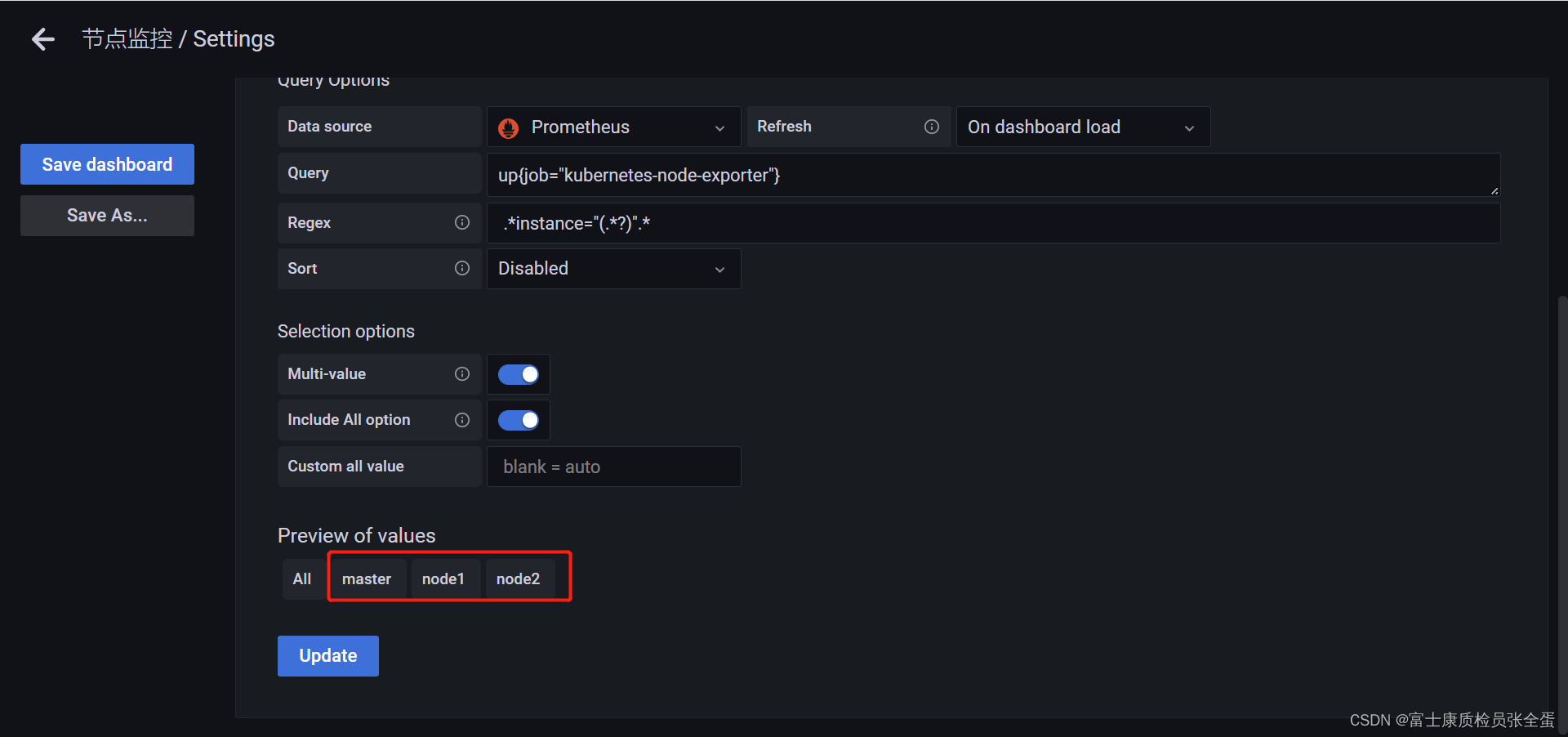
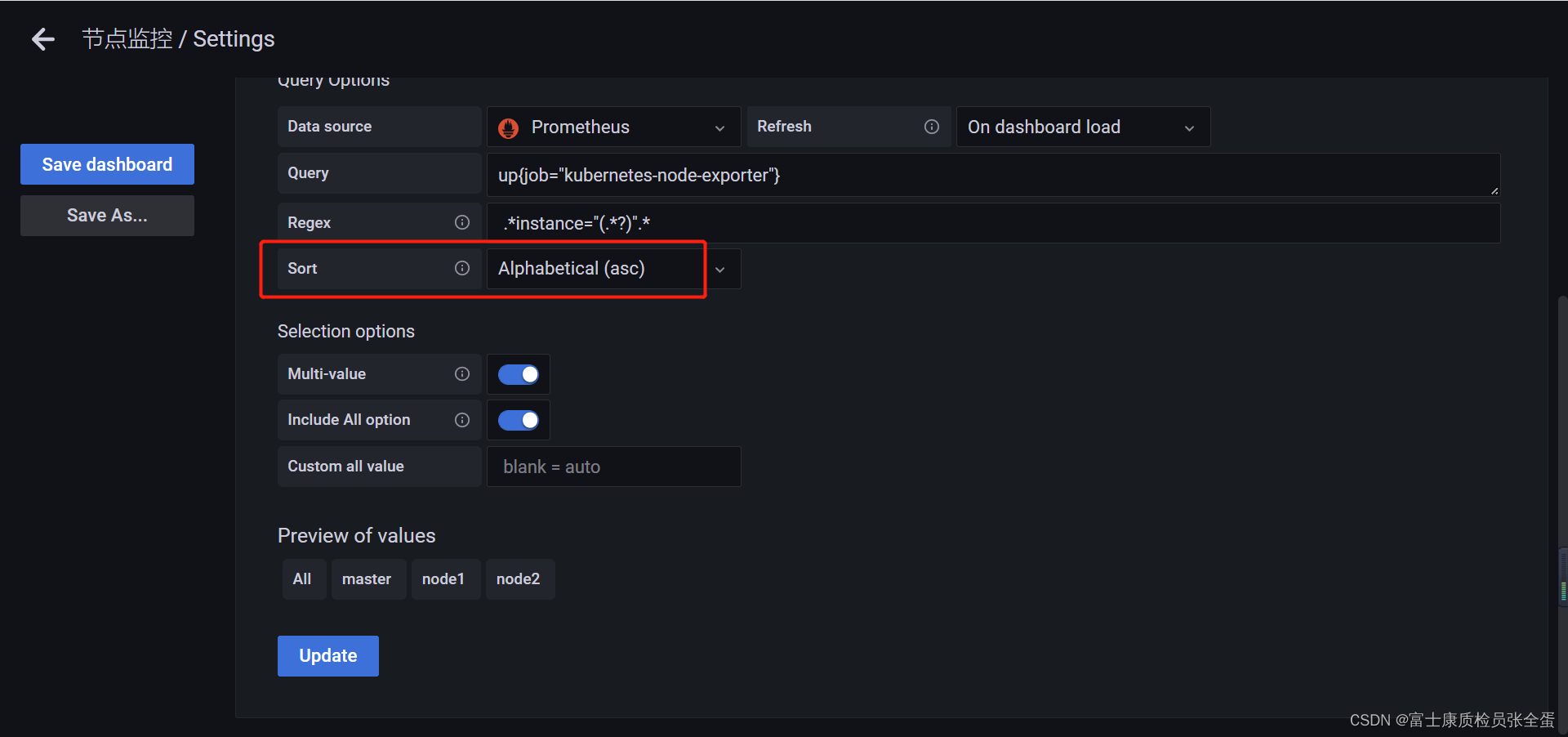
Name:变量名,在仪表盘中调用使用$变量名的方式,这个要放在PromQL语句里面Type:变量类型,变量类型有多种,其中query表示这个变量是一个查询语句Hide:为空是表现为下拉框,选择 label 表示不显示下拉框的名字,选择 variable 表示隐藏该变量,该变量不会在 Dashboard 上方显示出来,默认选择为空Data source:查询语句的数据源Refresh:何时去更新变量的值,变量的值是通过查询数据源获取到的,但是数据源本身也会发生变化,所以要时不时的去更新变量的值,这样数据源的改变才会在变量对应的下拉框中显示出来。Refresh 有两个值可以选择:On Dashboard Load(在 Dashboard 加载时更新)、On Time Range Change(在时间范围变更的时候更新)Query:查询表达式,不同的数据源查询表达式都不同Regex:正则表达式,用来对抓取到的数据进行过滤,默认不过滤Sort:排序,对下拉框中的变量值做排序,默认是 disable,表示查询结果是怎样下拉框就怎样显示Multi-value:启用这个功能,变量的值就可以选择多个,具体表现在变量对应的下拉框中可以选多个值的组合Include All option:启用这个功能,变量下拉框中就多了一个全选 all 的选项- lable对应的值为:
- Multi-value 下拉框就可以多选那么变量的值都可以是多个,需要在PromQL里面使用=~正则匹配
- Include All option 下拉框里面有全选或的选择
节点的值来源于instance标签
监控节点的相关指标是来源于名为 node-exporter 的任务,我们可以通过查询 up 来获取所有的监控实例:
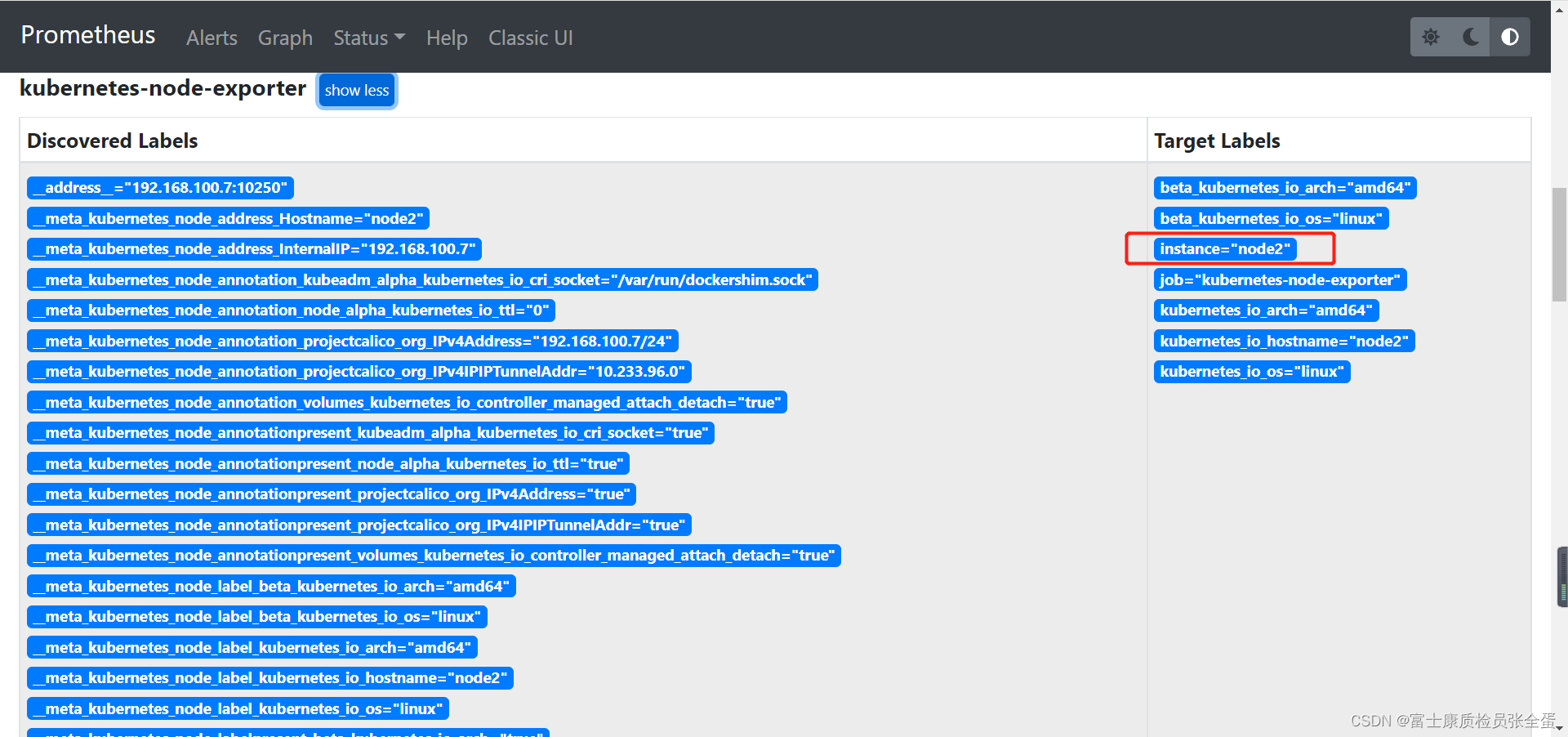
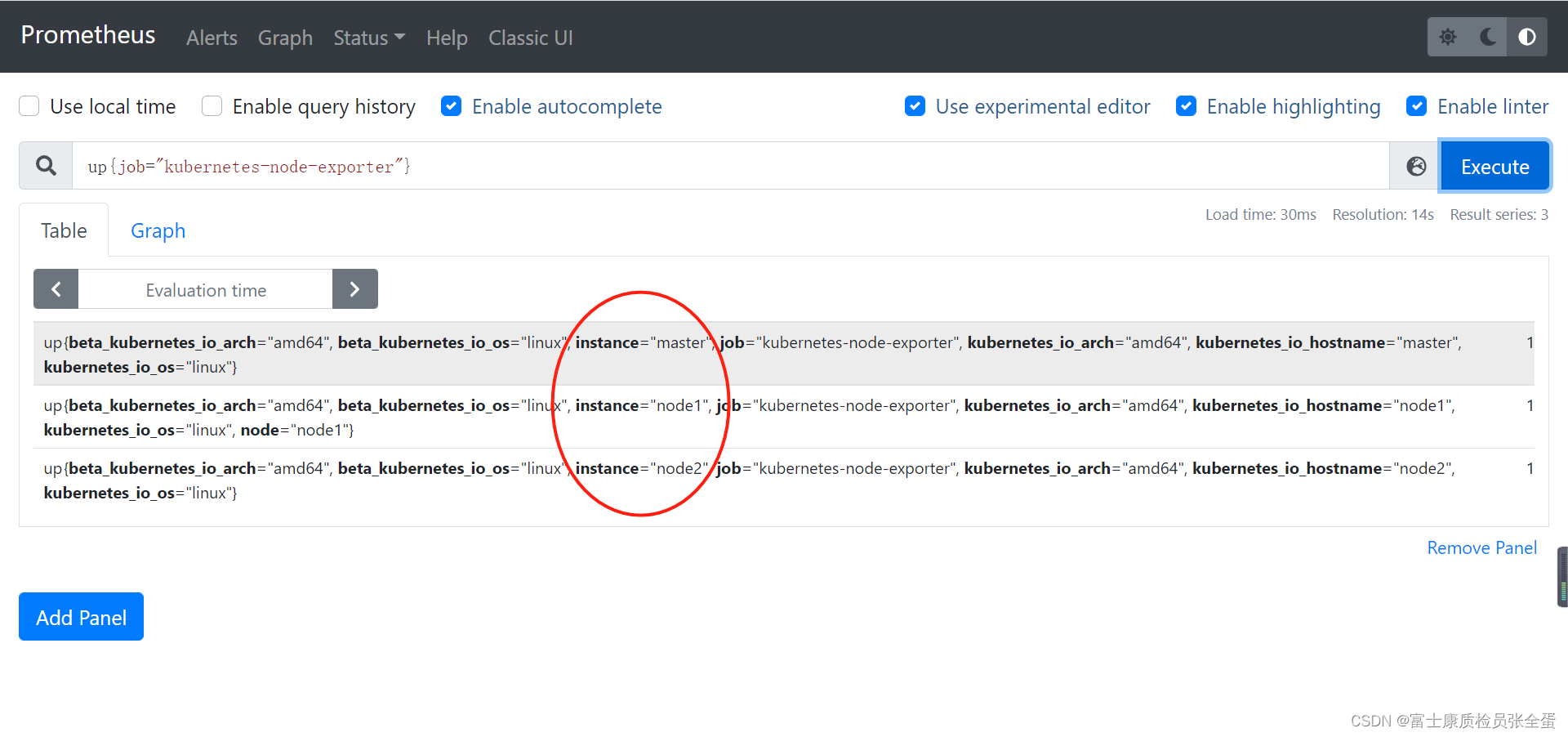

可以看到将所有的值都展现出来了,绿色的部分是预览的值,还要对预览的值进行处理。
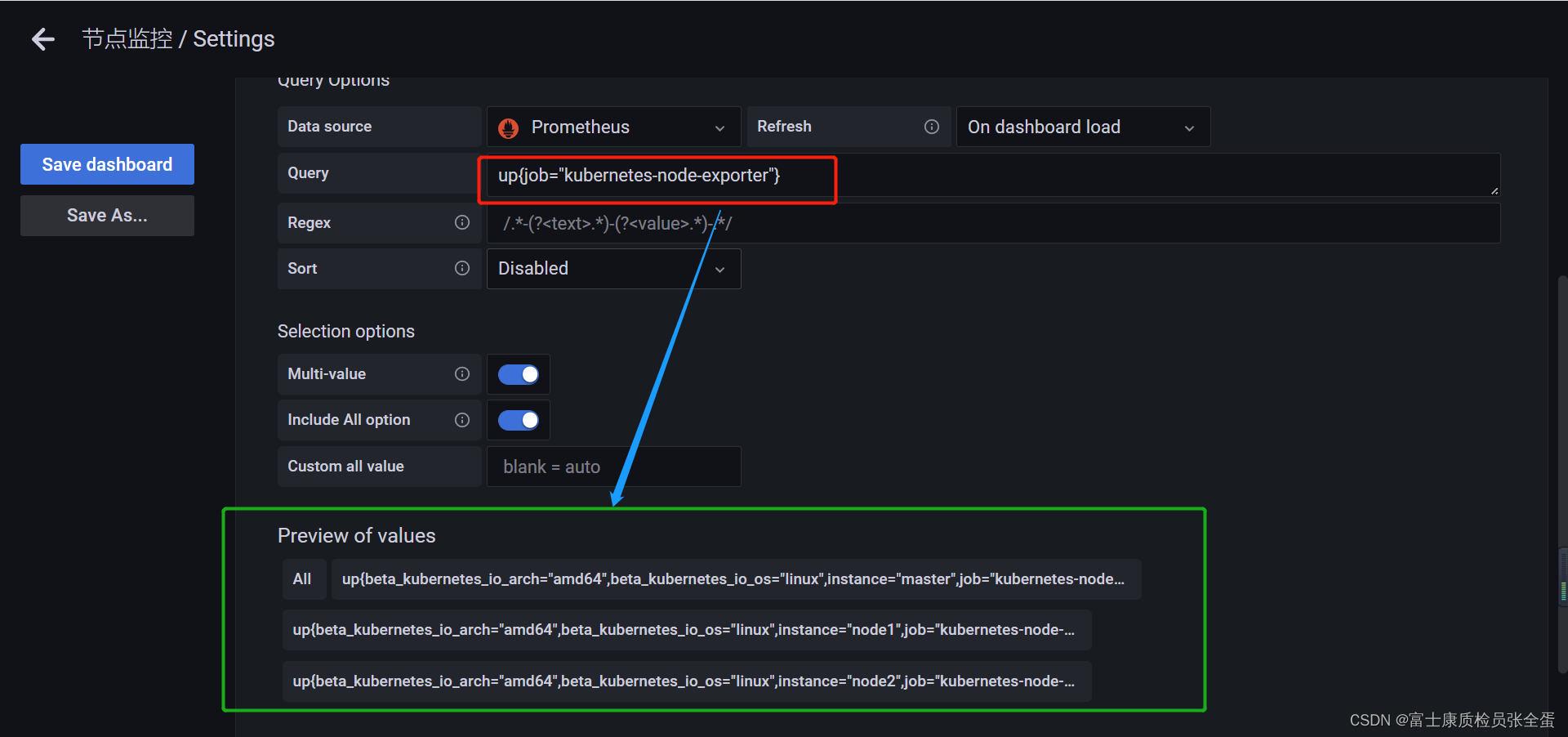
方法一:正则表达式
但是我们只需要instance的值,通过正则匹配到。
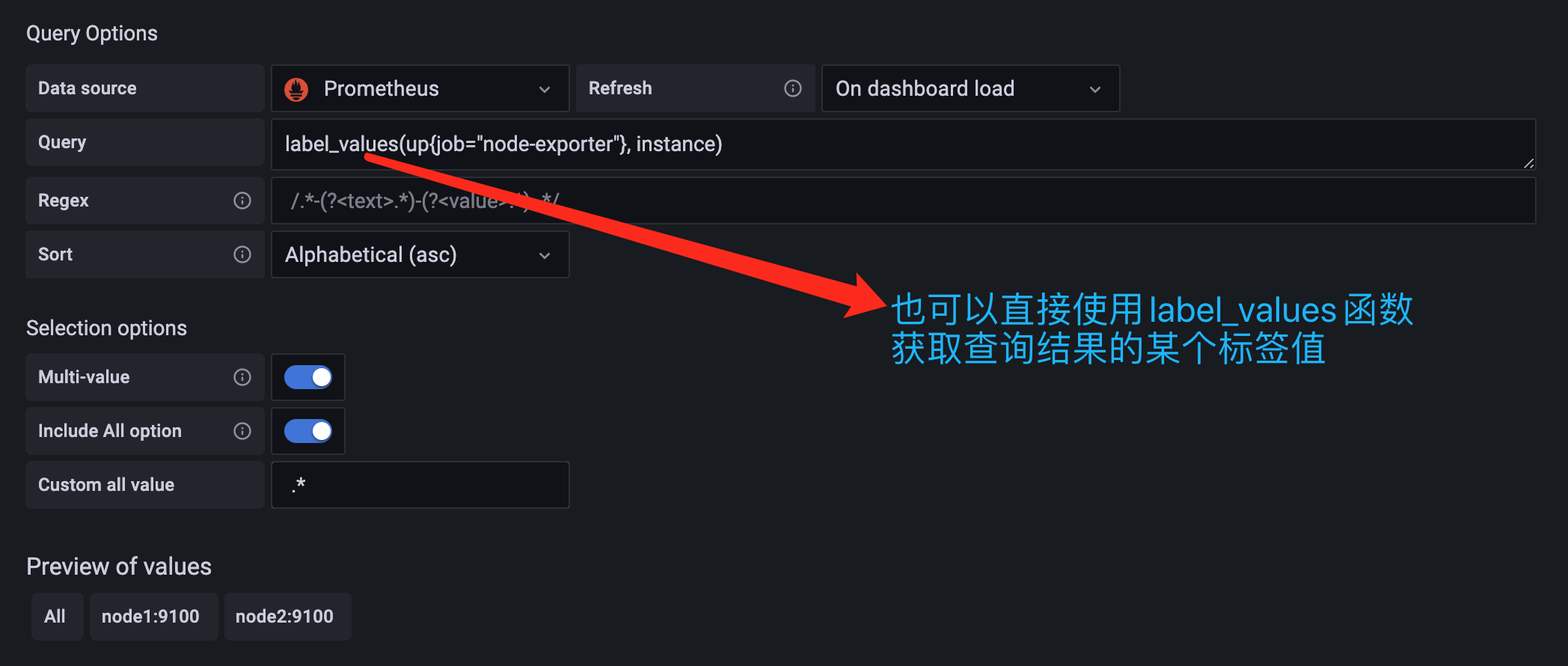
要想获取到 instance 标签中的值,我们这里可以使用一个正则表达式 .*instance="(.*?)".* 来获取实例数据,这样就成功定义了一个变量,除了使用正则表达式的方式来获取需要的值,此外我们还可以使用一个 label_values() 的函数来直接获取查询结果中的某个 label 标签的值:
然后可以根据结果值来做一个排序,主要是上面正则表达式要会写。
常见正则表达式:
^:匹配搜索字符串开始位置
$:匹配搜索字符串结束位置
.:匹配除换行符n之外的任何单个字符
[xyz]:字符集,与任意一个指定字符匹配
[a-z]:字符范围,匹配指定范围内的任何字符
w:与以下任意字符匹配 A-Z a-z 0-9 和下划线,等效于[A-Za-z0-9_]
d:数字字符匹配,等效于[0-9]
{n}:正好匹配n次
{n,}:至少匹配n次
{n,m}:匹配至少n次至多m次
*:零次或多次,等效于{0,}
+:一次或多次,等效于{1,}
?:零次或一次,等效于{0,1}
方法二:lable_values函数
除了上面这种方式,还有一种简单的方式。我们只需要instance标签的值就行了,直接可以使用lable_values函数就可以,这个会去取得时间序列里面的某条标签的值。
label_values(up{job="kubernetes-node-exporter"},instance)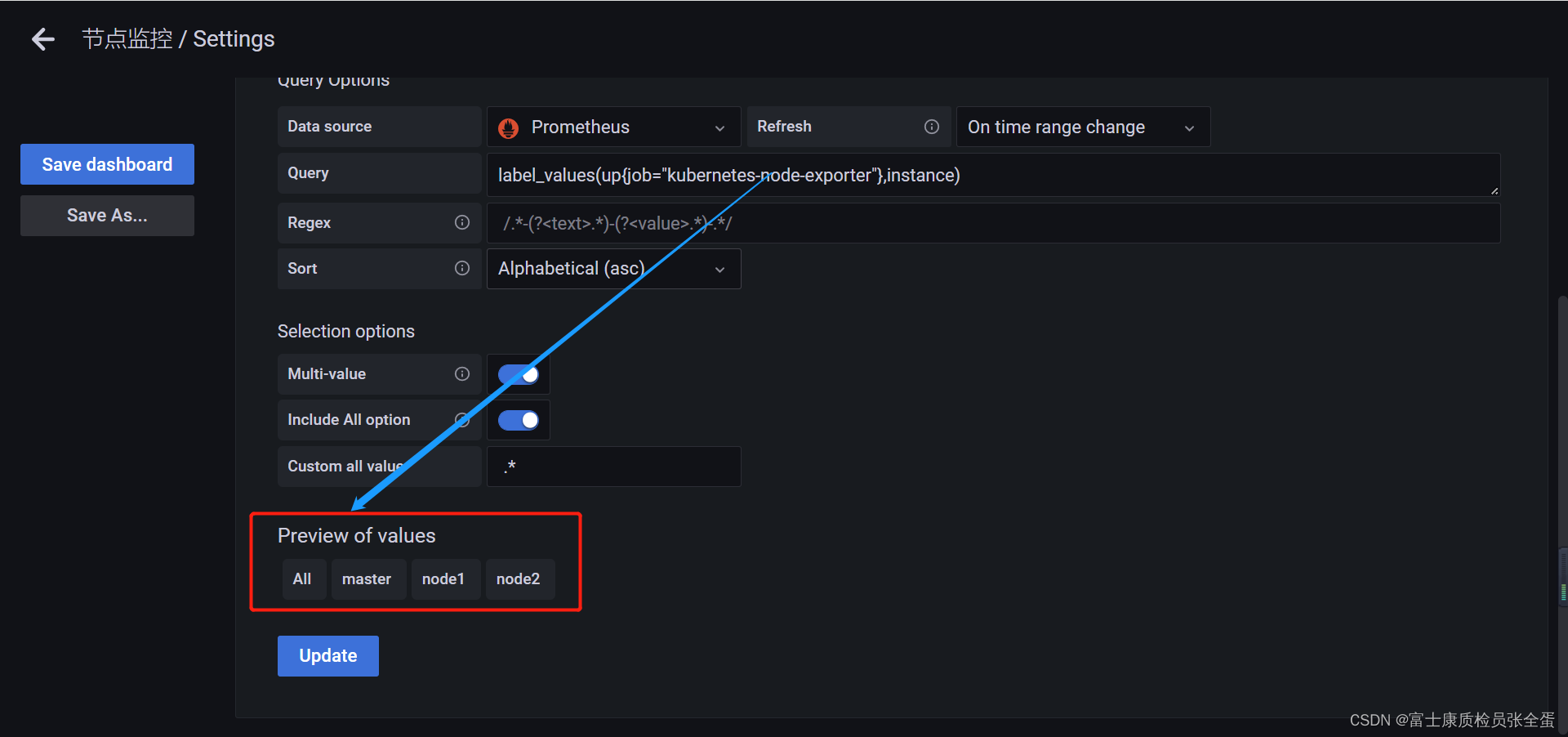

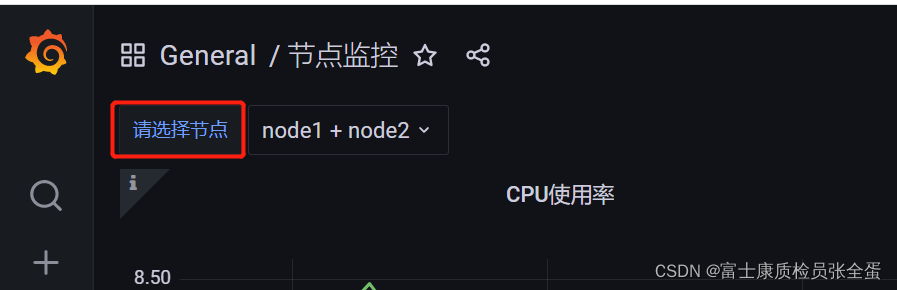
 回到 Dashboard 页面就可以看到多了一个
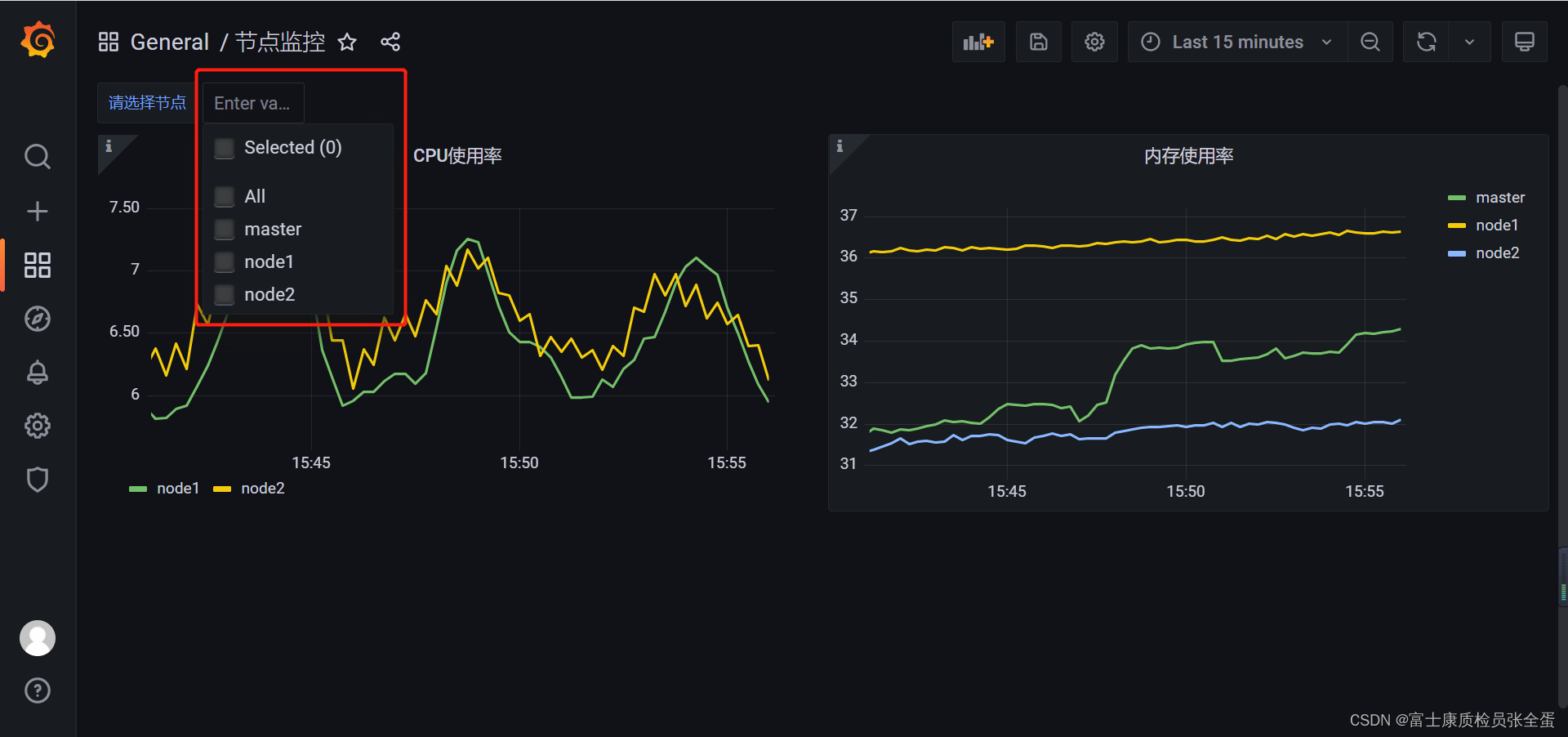
回到 Dashboard 页面就可以看到多了一个选择节点的下拉框:
下面是添加数据源的参数
参数传入promQL语句
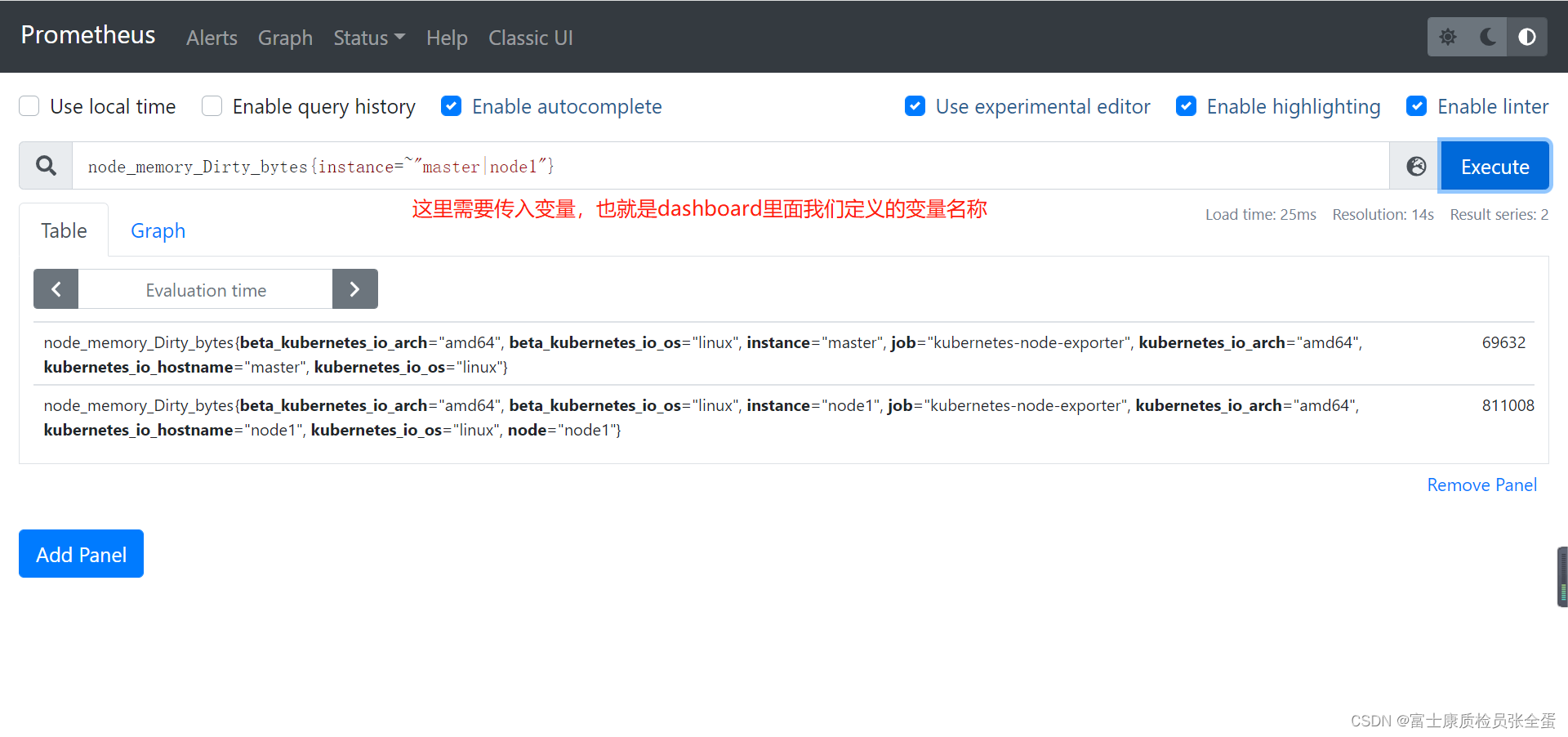
但是这个时候的面板并不会随着我们下拉框的选择而变化,我们需要将 instance 这个变量传入查询语句中,比如重新修改CPU使用率的查询语句:
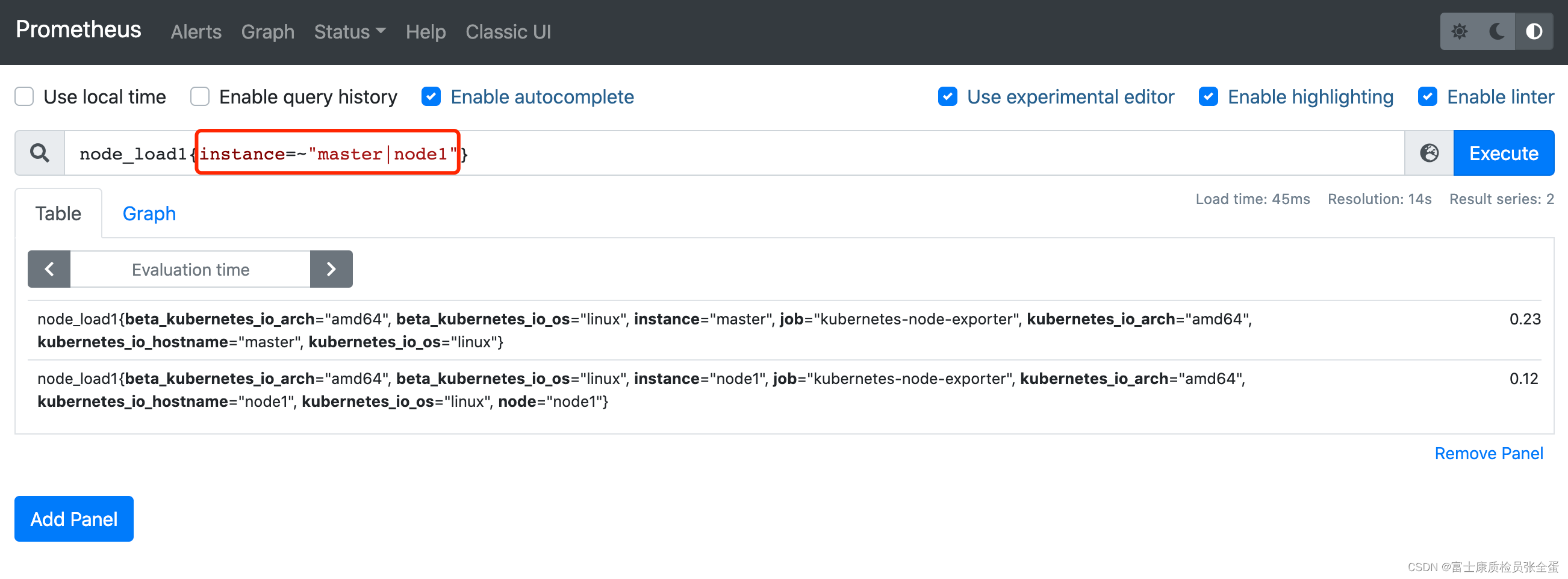
这部分最为关键的是 instance=~"master|node1" ,需要添加这个标签对时间序列进行过滤。
node_load1{instance=~"master|node1"}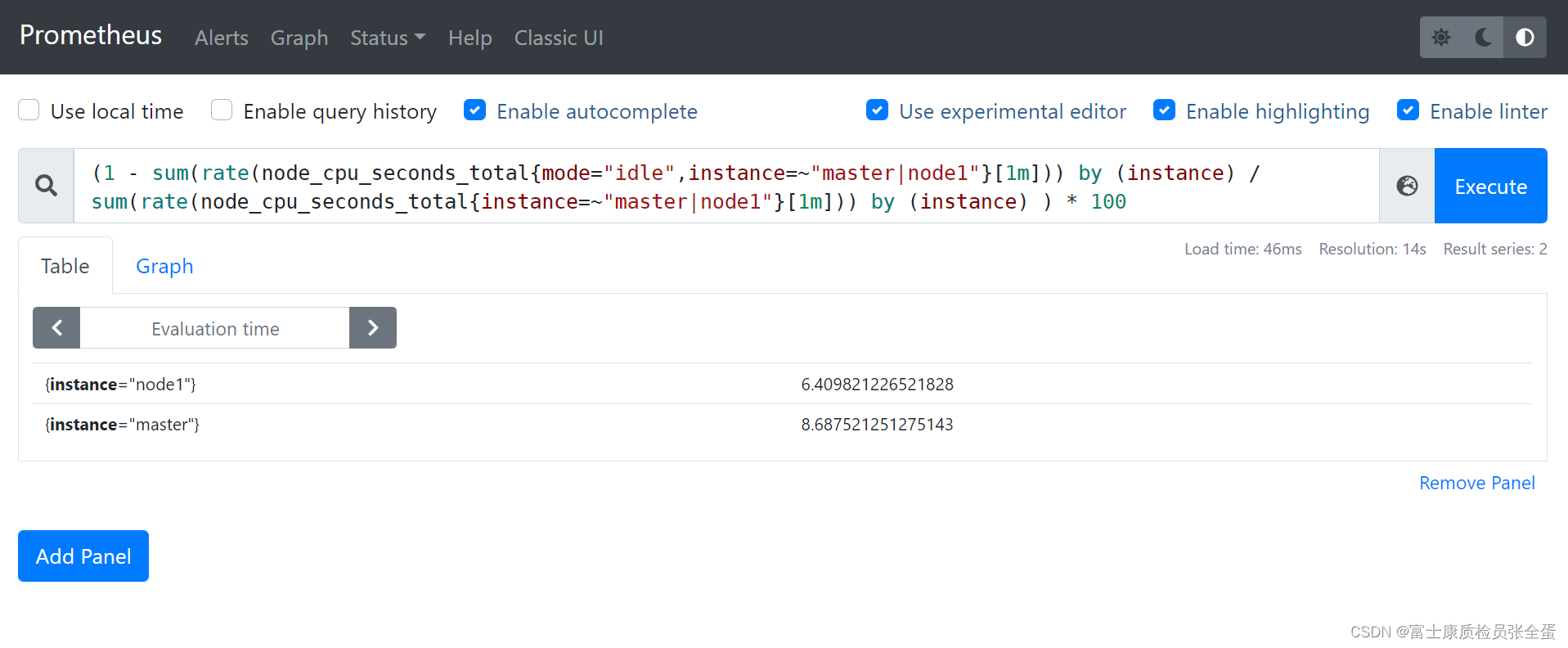 最后修改一下查询语句,查询语句里面都是写死了的,没有根据下拉框的参数去做过滤。
最后修改一下查询语句,查询语句里面都是写死了的,没有根据下拉框的参数去做过滤。
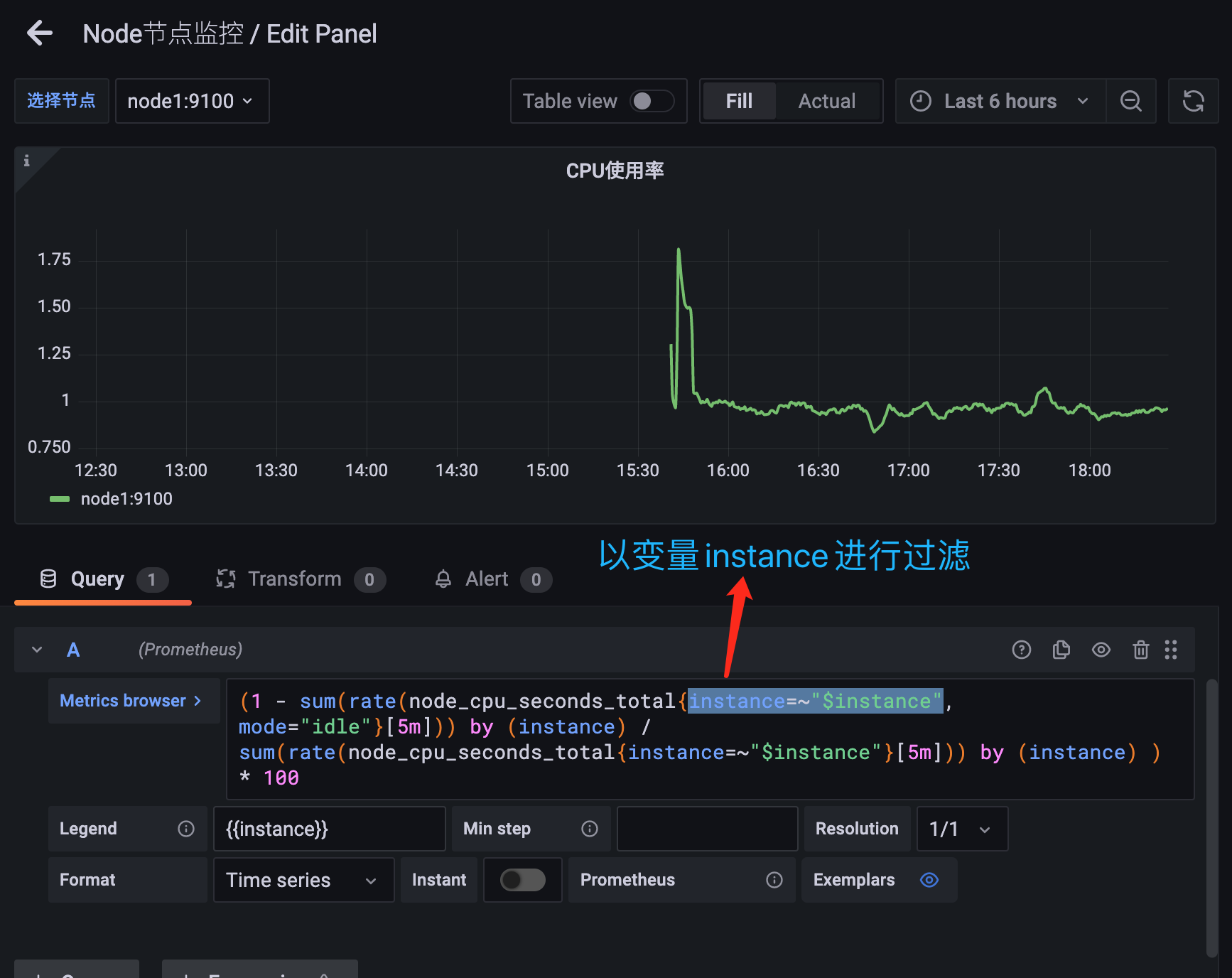
(1 - sum(rate(node_cpu_seconds_total{mode="idle",instance=~"$instance"}[1m])) by (instance) / sum(rate(node_cpu_seconds_total{instance=~"$instance"}[1m])) by (instance) ) * 100这样就相当于对节点进行了过滤
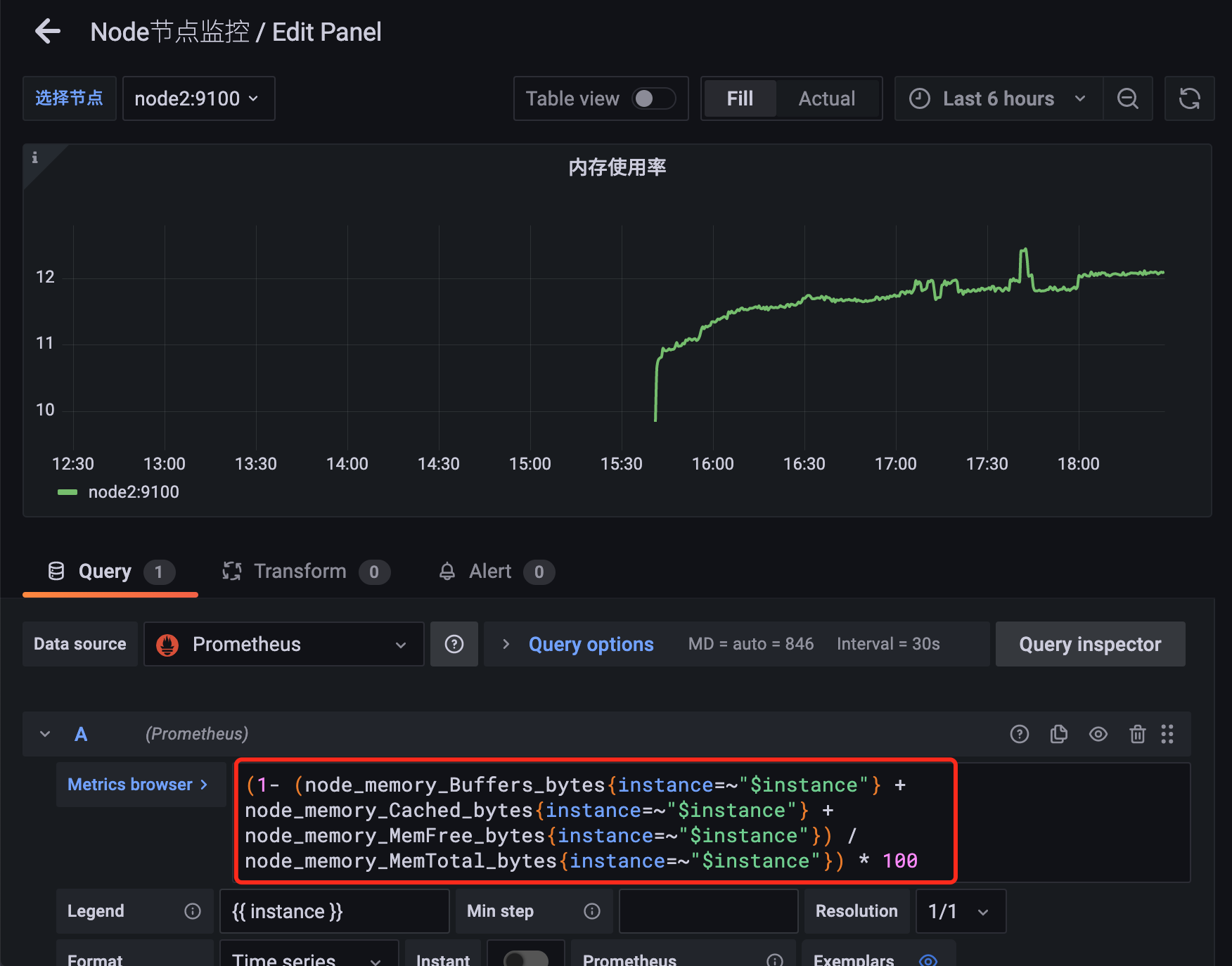
可以看到选哪个节点的时候,就会将这个变量替换为node1 node2。
回到 Dashboard 页面就可以根据我们的下拉框来选择需要监控的节点数据了,定义参数的时候如果选择了可以选择所有,同样可以查看所有节点的数据:
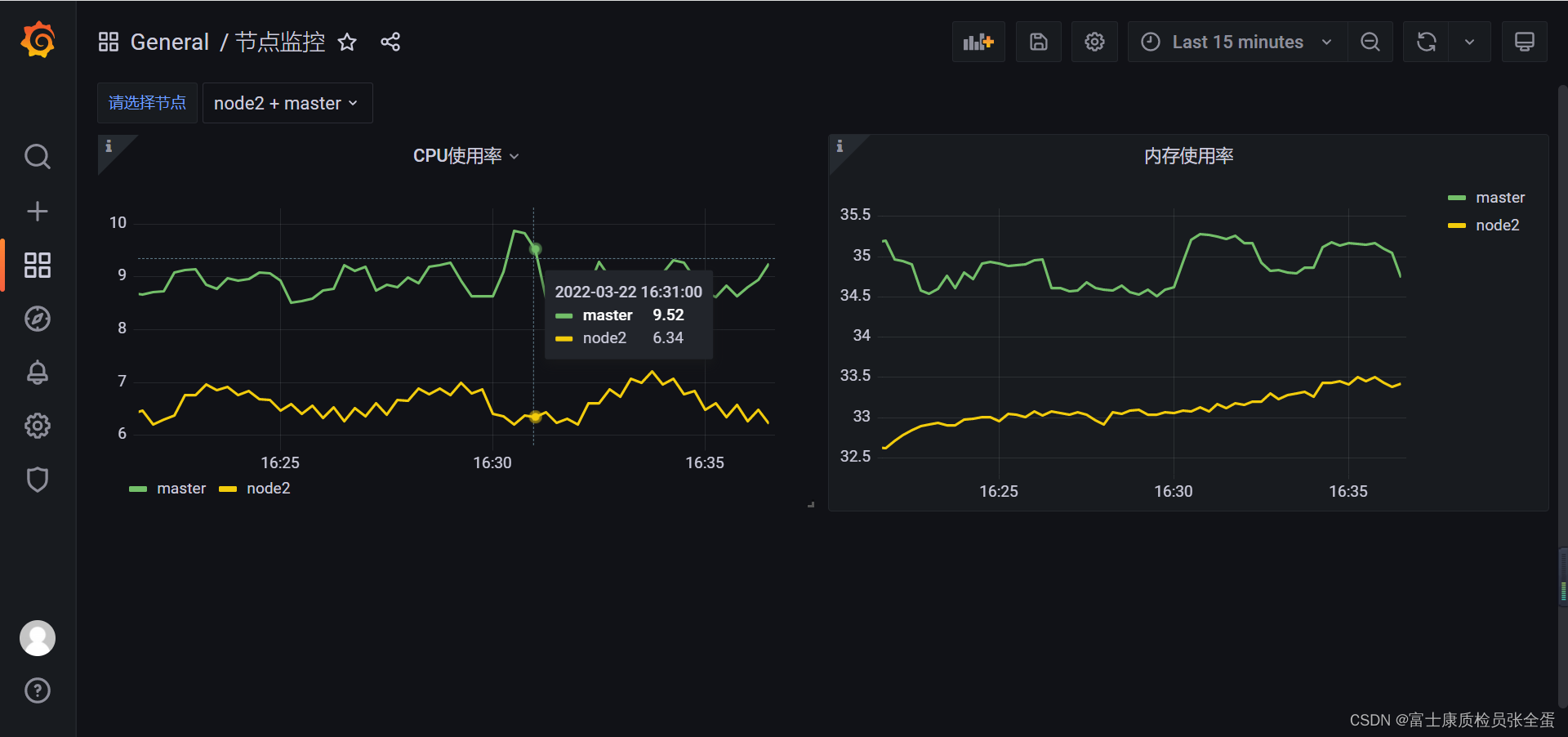
最后添加了hosts参数,promql语句修改如下
(1 - sum(rate(node_cpu_seconds_total{instance=~"$hosts",mode="idle"}[1m])) by (instance) / sum(rate(node_cpu_seconds_total{instance=~"$hosts"}[1m])) by (instance) ) * 100
(1- (node_memory_Buffers_bytes{instance=~"$hosts"} + node_memory_Cached_bytes{instance=~"$hosts"} + node_memory_MemFree_bytes{instance=~"$hosts"}) / node_memory_MemTotal_bytes{instance=~"$hosts"}) * 100
















 55
55

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









